Хотя Apache Kafka является надежной платформой потоковой обработки событий, что особенно важно для распределенных приложений, отказы случаются и в ней. Сегодня разберем важную для обучения разработчиков и дата-инженеров тему про идентификацию и обработку отказов в Kafka-приложениях с помощью простого, но эффективного метода теории надежности. Что такое FMECA-анализ, как его проводить и насколько это полезно при исследовании причин возникновения сбоев в Kafka-приложениях и других распределенных системах.
Почему случаются отказы в распределенных приложениях: основы FMECA
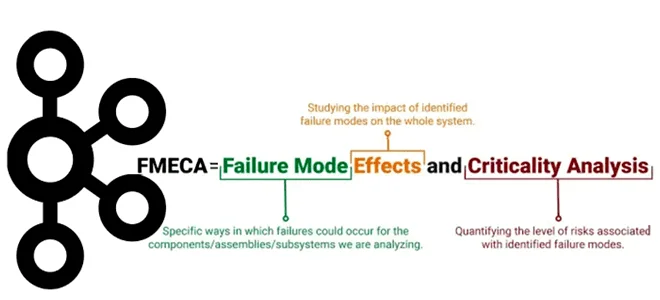
Распределенные приложения являются сложными системами из множества компонентов. Поэтому неудивительно, что для их проектирования и исследования применяются методы системного анализа и теории надежности. В частности, анализ видов и последствий отказов (FMEA – Failure Mode and Effects Analysis) — метод идентификации способов отказа компонентов, систем или процессов, которые могут привести к невыполнению их назначенной функции. FMEA как регулярно проводимая процедура позволяет проанализировать все возможные ошибки системы и определить их воздействие на систему с целью классификации критичности. Расширенной версией метода FMEA является FMECA – анализ эффективной критичности режима отказа (Failure Mode Effective Criticality Analysis). FMECA позволяет оценить критичность и значимость каждого идентифицированного вида отказа и представляет собой процесс проверки всех компонентов и интеграций архитектуры системы для выявления потенциальных режимов отказа, их причин и последствий. Целью FMECA является повышение осведомленности о рисках и предотвращение отказов.
Проводя несколько режимов сбоев в реальной системе и активируя для них различные превентивные и обнаруживающие меры, можно повысить надежность, отказоустойчивость, безопасность и качество архитектуры распределенного приложения. Это комплексное упражнение позволяет установить взаимосвязь между причинами отказа и его последствиями, а также важность корректирующих действий. На практике применение FMECA к распределенным приложениям дает следующие преимущества:
- повышенная надежность и ремонтопригодность;
- раннее выявление точек одиночного отказа и проблем системного интерфейса;
- документированный метод выбора дизайна с высокой вероятностью успеха;
- критерии раннего планирования интеграционных тестов и других проверок архитектуры;
- сокращение времени разработки и редизайна;
- более эффективные планы контроля;
- улучшенные требования к проверке и валидации.
- эффективный метод оценки последствий предлагаемых изменений в проекте;
- основа для процедур устранения неполадок и контроля производительности;
- оптимизированное профилактическое обслуживание;
- снижение экономических затрат на устранение отказов благодаря их профилактике и быстрому устранению.
В распределенных приложениях разные виды отказов можно разделить по следующим категориям:
- упущение данных, связанное с обменом информацией между отправителями и получателями. Например, сервер слишком медленно отвечает получателю из-за помех или низкой пропускной способности канала связи между отправителем и получателем. Этот тип сбоя обычно возникает, когда каналы связи между компонентами перегружены или неправильно настроены. В случае Kafka-приложений ответ потребителю может быть медленным из-за высокой задержки между потоковым приложением и сервером Kerberos.
- сбой процесса, когда он перестает отвечать из-за постоянного отказа. Например, серверный процесс перестает отвечать на новый запрос от потребителей из-за исчерпания ресурсов. Еще до того, как процесс достигнет состояния аварийного сбоя, он начинает демонстрировать симптомы замедления.
- ошибка синхронизации, когда ответ процесса слишком медленный. К примеру, задержки в обработке клиентских запросов. Сюда же относится сбой производительности системы.
- ошибка ответа, когда процесс отвечает неверными данными или неправильным ответом. Большинство сбоев, связанных с данными, подпадают под эту категорию.
- произвольный сбой, который считается наихудшим типом отказа. Процесс может давать произвольные ответы в произвольное время. Например, канал повторяет сообщения или искажает их. Этот тип отказа труднее всего обнаружить, и он более всего влияет на всю систему.
Если представить разложить архитектуру распределенного приложения на различные уровни, наложенные друг на друга, можно понять, какие типы отказов могут возникнуть на разных слоях. Самый верхний прикладной уровень является наиболее уязвимым уровнем в архитектуре: любой сбой, возникающий на нижележащих слоях, повлияет на прикладной уровень. Целесообразно проводить FMECA в программно-аппаратной среде, где включены все сторонние интеграции с распределенной системой. Эта среда должна быть аналогична производственной, но не являться ею, чтобы позволять запускать разные режимы отказа для проверки устойчивости системы. Как эти идеи FMECA-анализа применить для идентификации отказов в Kafka-приложениях, запущенных в кластере Kubernetes на облаке Google (GKE), мы рассмотрим далее.
Идентификация отказов в Kafka-приложениях
Прежде всего отметим, что в реальной производственной среде причин отказа может быть намного больше, т.к. они обусловлены сложностью инфраструктуры и большим объемом компонентов, например, для обеспечения безопасности, LDAP для аутентификации и пр. Тем не менее, в целом архитектуру Kafka-приложений на GKE можно представить в виде комплексной многокомпонентной системы с разными каналами связи/интеграции между компонентами.
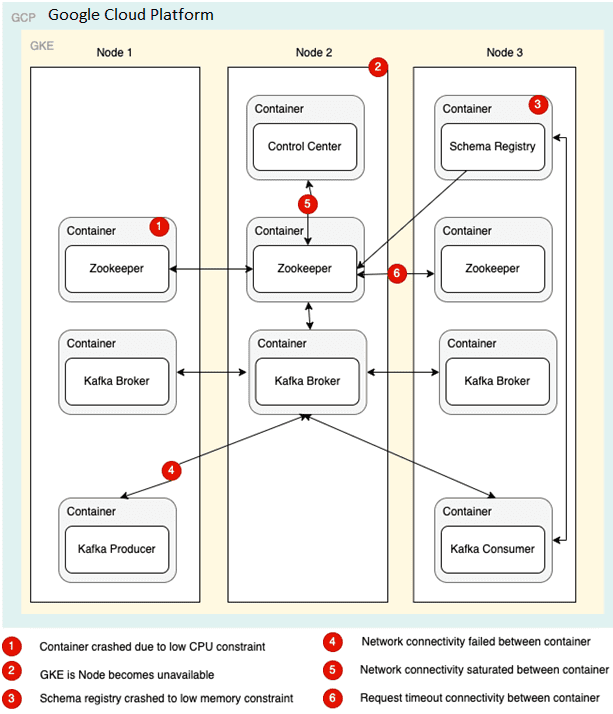
Каждый компонент и его интеграция усложняют систему и могут выйти из строя. Чтобы сопоставить и определить серьезность режимов отказа, необходимо зафиксировать сценарии отказа и их результирующие последствия для остальной части системы. При этом следует рассматривать каждый отказ с точки зрения следующих критериев:
- приоритет – критичность сбоя в зависимости от серьезности деловых и технических последствий;
- воздействие на бизнес, т.е. влияние сбоя на бизнес-процессы;
- техническое воздействие – сценарий сбоя, который может привести к последствиям для бизнеса, если не будет устранен в течение определенного периода времени;
- предотвращение – предупредительные меры например, предоставление достаточного количества ресурсов (ЦП, память, диск и пр.);
- обнаружение – меры по упреждающему мониторингу ресурсов компонентов для предотвращения сбоев;
- разрешение/исследование – шаги по исследованию и устранению отказа.
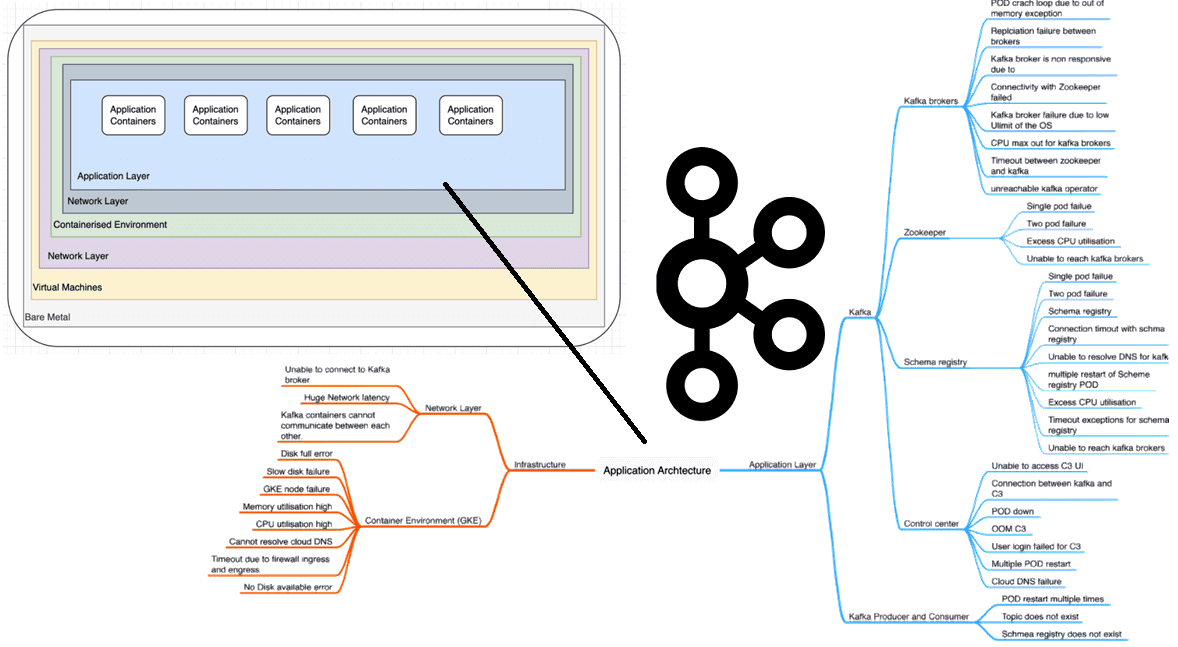
Визуализировать отказы и их последствия поможет простой и наглядный метод системного анализа, называемый карты ассоциаций. К примеру, возможные сбои Kafka-приложений могут быть вызваны следующими причинами:
- отказы реестр схемы;
- отказы центра управления;
- отказы брокера;
- отказы Zookeeper.
Узнайте больше про тестирование и разработку распределенных приложений с Apache Kafka для потоковой аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков больших данных в Москве:
Источники
- https://abhishek-kapoor.medium.com/failure-mode-effect-criticality-analysis-fmeca-for-distributed-applications-f7a6bd5a9bb5
- http://sewiki.ru/FMEA
- https://abhishek-kapoor.medium.com/step-by-step-process-to-identify-failure-modes-in-distributed-systems-19aeeee2c4ee

