
Запуск Apache Airflow с Kubernetes сегодня стал стандартом де-факто. Однако, при практическом развертывании Airflow с помощью исполнителя Kubernetes и оператора пода в кластере этой платформы оркестрации контейнерных приложений возникает множество препятствий и трудностей. Сегодня рассмотрим, как обойти их с помощью service-mesh проекта с открытым исходным кодом Istio, какие проблемы могут при...
Мы уже рассказывали, что такое реестр схема Apache Kafka и зачем он нужен. Чтобы глубже разобраться с этой темой, важной для обучения разработчиков распределенных приложений и дата-инженеров, сегодня заглянем под капот Schema Registry и разберем работу этого компонента платформы Confluent Apache Kafka с продюсерами и потребителями. Еще раз про реестр...
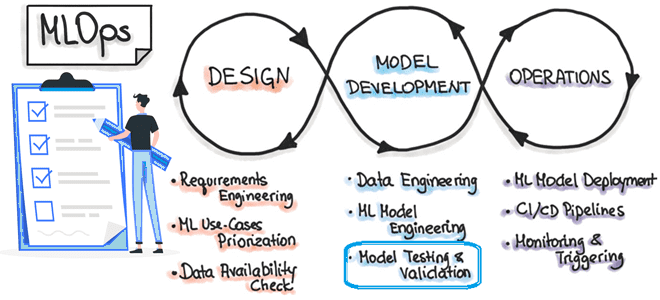
Поскольку разработка и развертывание ML-систем отличаются от традиционного ПО, о чем мы писали здесь и здесь, процесс тестирования модели машинного обучения тоже имеет свою специфику, которую учитывает концепция MLOps. Читайте далее, что и как тестировать при разработке систем Machine Learning, а также при чем здесь подход Arrange-Act-Assert. MLOps и тестирование...

Продолжая разговор про импортозамещение, сегодня рассмотрим новый продукт от «Аренадата Софтвер» - разработчика широкой линейки российских решений для хранения и аналитики больших данных. Компания адаптирует открытые дистрибутивы Big Data фреймворков к специфике корпоративного использования и предоставляет русскоязычную поддержку 24/7. Что такое Arenadata Postgres, кому и зачем нужен этот продукт, и...
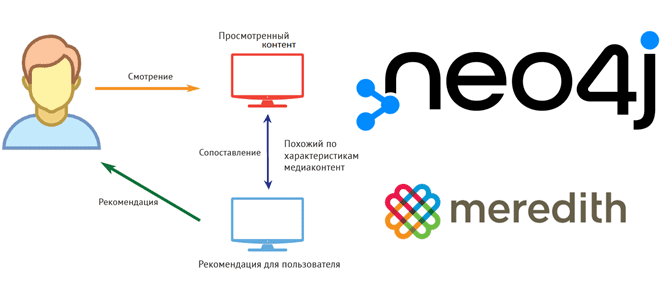
Развивая наш новый курс по графовой аналитике больших данных в бизнес-приложениях, сегодня рассмотрим американского медиаконгломерат Meredith Corporation по персонализации пользовательских профилей с помощью графовой СУБД Neo4j и алгоритма непересекающихся множеств (Union-Find). Постановка задачи: сложности идентификации анонимных клиентов Различными контент-продуктами конгломерата Meredith Corporation ежемесячно пользуется более 180 миллионов человек через приложения,...
Недавно мы писали про Yandex Managed Service for Apache Kafka. Продолжая тему импортозамещения, сегодня рассмотрим, как этот и другие полностью управляемые сервисы Яндекса помогли отечественному маркетплейсу KazanExpress построить эффективное BI-решение. Что такое Yandex DataLens и как он способен заменить зарубежные системы бизнес-аналитики типа Tableau с Power BI, а также открытый Apache...
Чтобы на наглядном примере показать, чем Apache NiFi полезен для дата-инженера, сегодня рассмотрим практический кейс построения простого ETL-конвейера. Как собрать данные из разных API, записать их в СУБД и отправить уведомление о результатах с готовыми процессорами NiFi. Постановка задачи: ETL-конвейер тревел-приложения В качестве примера рассмотрим корпоративное приложение для путешественников, которое...
В этой статье для дата-инженеров и аналитиков данных, рассмотрим, что такое широковещательные соединение в Apache Spark SQL, чем оно полезно и как работает на практических примерах. BROADCAST JOIN в SELECT-запросах Spark SQL, а также краткий ликбез по подсказкам или хинтам. Что такое широковещательное соединение в Apache Spark SQL Распределенная природа...