 977
977 
В рамках продвижения нашего нового курса по графовой аналитике больших данных в бизнес-приложениях, сегодня рассмотрим проблемы неконстистентности чтения из графовой СУБД Neo4j и способы их решения. Что такое bookmarks-механизм, как работает объект сеанса в Neo4j в кластерном режиме и при чем здесь драйверы.
Зачем нужны закладки в Neo4j
Драйверы графовой СУБД Neo4j, о которых мы писали здесь, имеют концепцию, называемую закладками (bookmarks), которая позволяет читать собственные записи. Рассмотрим, как это работает на примере последовательного выполнения следующих запросов на SQL-подобном языке Cypher в Neo4j:
- CREATE (p:Person { name: ‘David’ })
- MATCH (p:Person) WHERE name = ‘David’ RETURN count(p)
В реальном кластере Neo4j их выполнение происходит так:
- первый запрос завершается успешно, когда большинство членов кластера подтвердили запись;
- если второй запрос случайно будет перенаправлен узлу кластера, у которого еще нет записи, он может вернуть ответ 0, что не соответствует действительности.
Впрочем, это легко обойти, если использовать тот же объект сеанса для чтения, что и для записи, поскольку сервер возвращает закладку при записи. Объект сеанса использует цепочку закладок (bookmark chaining), и все последующие чтения выполняются с этой закладкой в базе данных.
Таким образом, если при выполнении последовательности операций нужно, чтобы более поздние операции гарантированно считывали записи из более ранних, следует повторно использовать один и тот же объект сеанса, т.к. сеансы связывают закладки, ранее полученные от каждого запроса.
Если же требуется координировать несколько разных программ, к примеру, программе B нужно читать записи программы A, тогда программа A должна передать свою закладку записи в сеанс другой программы. Так B сможет прочитать состояние базы данных, чтобы гарантировать согласованность к этому моменту времени.
Доступ к объектам bookmarks можно получить следующим образом:
my_bookmark = Nonewith driver.session() as session: results = session.write_transaction(write_bunch_of_people) my_bookmark = session.last_bookmark()with driver.session(bookmarks=[my_bookmark]) as session2
Хотя операционная механика кластера интересна с точки зрения приложений, также полезно подумать о том, как они будут использовать базу данных. Часто аналитическим приложениям требуется как читать данные из графа, так и записывать их в него. В зависимости от характера рабочей нагрузки нужно, чтобы чтения из графа учитывали предыдущие записи, чтобы обеспечить причинно-следственную согласованность. Что это такое и как влияет на механизм закладок в кластерном режиме графовой СУБД Neo4j, рассмотрим далее.
Причинно-следственная согласованность
Причинно-следственная согласованность часто используется в распределенных вычислениях, гарантируя, что причинно-связанные операции просматриваются каждым узлом распределенной системы в одном и том же порядке. Так клиентские приложения читают записи независимо от того, с каким экземпляром они взаимодействуют. Это упрощает взаимодействие с большими кластерами, позволяя клиентам логически рассматривать их как единый сервер.
Причинно-следственная согласованность позволяет записывать данные на основные серверы для безопасного хранения и читать эти записи из реплики чтения, где графовые операции масштабируются. Например, причинно-следственная согласованность гарантирует, что запись, создавшая аккаунт пользователя, будет присутствовать, когда тот же пользователь впоследствии попытается войти в систему.
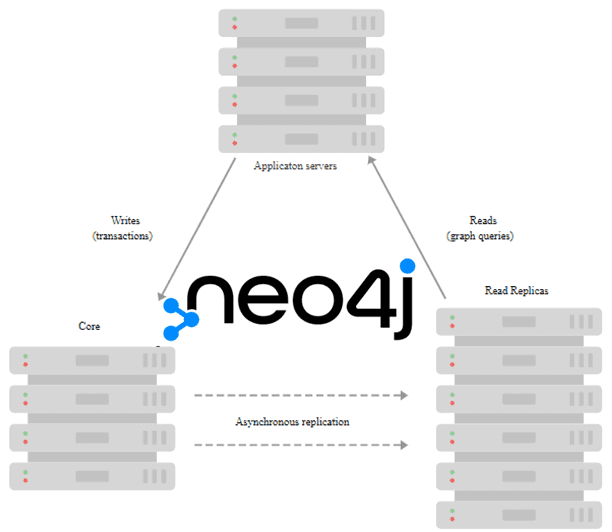
При выполнении транзакции клиент может запросить закладку, которую затем представляет в качестве параметра для последующих транзакций. Используя эту закладку, кластер может гарантировать, что только серверы, обработавшие отмеченную закладкой транзакцию клиента, будут выполнять следующую транзакцию. Это обеспечивает причинно-следственную цепочку, которая обеспечивает правильную семантику чтения после записи с точки зрения клиента.
Кроме самой закладки, все части Cypher-запроса обрабатываются кластером Neo4j. Драйверы базы данных работают с менеджером топологии кластера, чтобы выбрать наиболее подходящие основные серверы и реплики чтения для обеспечения высокого качества обслуживания. Эта концепция реализуется в Neo4j, что позволяет назвать ее кластер поддерживающим причинно-следственную согласованность.
Закладки гарантируют, что при чтении данных из кластера эти считанные данные представляют собой самое последнее представление графа пользователем. Однако, на практике не существует универсального сценария, когда имеет смысл использовать закладки. В реальности скорость распространения данных зависит от лидера, подписчиков, реплик чтения и количества транзакций.
Поэтому целесообразно применять bookmark-механизм для запросов, где необходимо читать собственные записи, в т.ч. запросы прямого чтения, чувствительные к задержке для лидера. При этом направлять транзакции чтения лидеру, следует осторожно, чтобы не перегрузить его чрезмерным количеством запросов. Впрочем, поскольку закладки существуют на уровне транзакций, их можно настроить их по-своему для достижения оптимальной пропускной способности и опыта. К примеру, задав уникальные условия для разных клиентов с различными требованиями к согласованности и готовности данных.
Узнайте больше реальных примеров применения Neo4j и других инструментов графовой аналитики больших данных для практических бизнес-задач на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков больших данных в Москве:
[elementor-template id=»13619″]
Источники

