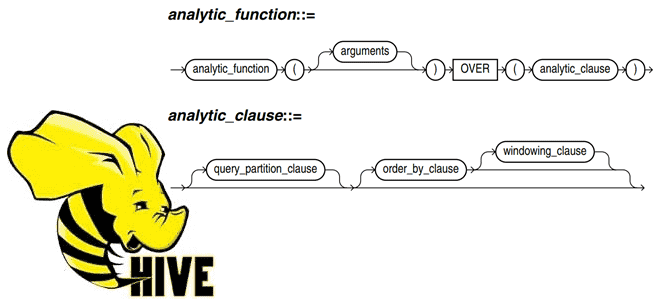
Постоянно добавляя в наши курсы по SQL-on-Hadoop для дата-инженеров и разработчиков распределенных приложений интересные примеры, сегодня рассмотрим пару практических техник по работе с Apache Hive. Читайте далее, как автоматически пронумеровать строки Hive-таблицы, исключив дубликаты в последовательности, и чем аналитическая функция row_number() отличается от rank() с dense_rank(). Генерация порядкового номера строки...

Недавно на примере ИТ-компании Salesforce мы рассказывали про вторичную индексацию таблиц Apache HBase с помощью Phoenix – средства обращения к NoSQL-хранилищу через SQL-запросы. В продолжение этого кейса, сегодня рассмотрим, как были перепроектированы глобальные вторичные индексы для обеспечения более высокого уровня согласованности, чем предлагает Apache Phoenix. Реализация вторичных индексов в таблицах...
Практическая реализация MLOps-концепции на примере международной рекрутинговой компании Glassdoor. Как построить самоуправляемую автоматизированную систему разработки и сопровождения ML-моделей с MLFlow, Apache Spark и AirFlow, Kubernetes, GitLab, SageMaker Feature Store, Whylogs, Jenkins, Spinnaker и Prometheus с Grafana. Предыстория: зачем MLOps в Glassdoor Glassdoor с 2008 года помогает соискателям по всему миру...

Чтобы сделать наши курсы по Apache Spark еще более полезными, сегодня разберем 2 варианта решения типовой задачи инженерии данных. Как быстро и эффективно считать данные из множества CSV-файлов с одинаковой схемой за несколько строк кода на PySpark. Постановка задачи: рутинная работа с CSV-файлами Наряду с JSON-файлами, про которые мы писали...
Сегодня обсудим ключевые тренды развития дата-инженерии и инструментальные средства их реализации. Как это применяется на практике, рассмотрим на примере эволюции хранилища данных в индонезийской ИТ-компании Bukalapak, от локального кластера Apache HBase до Лямбда-архитектуры в облаке Google Cloud Platform с Kafka, Spark и AirFlow. 7 главных драйверов развития дата-инженерии В наши...

24 февраля в 19:30 (мск) Школа Больших Данных проводит открытую встречу по нашему новому курсу "Графовые алгоритмы. Бизнес-приложения". За пару часов вы узнаете, как повысить эффективность предприятия с помощью Data Science, дискретной математики и прикладных средств реализации графовых алгоритмов в современных базах данных и вычислительных движках. Автор курса и ведущий...
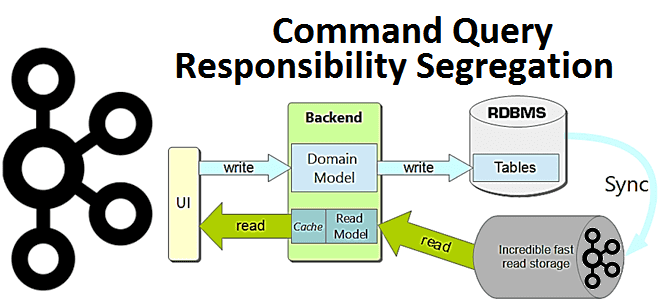
В этой статье для разработчиков распределенных приложений и ИТ-архитекторов разберем достоинства и недостатки паттерна проектирования CQRS, а также рассмотрим пример его реализации на Apache Kafka, Spring Cloud Stream и MongoDB. Что такое CQRS: основы проектирования архитектуры приложений Спрос на приложения, управляемые событиями, постоянно растет как для решения новых бизнес-задач, так...

Чтобы самостоятельное обучение по Impala стало еще интереснее, сегодня мы предлагаем вам простой комплексный тест по основам работы с различными функциями в этой распределенной СУБД, включая особенности их применения. Комплексный тест по основам работы с функциями в Impala для новичков Для тех, кто начинает самостоятельное обучение по Apache Impala, мы...

Продвигая наш новый курс по графовым алгоритмам в бизнес-приложениях, сегодня рассмотрим применение теории графов к задаче анализа социальных связей на практическом примере возможностей библиотеки Graph Data Science СУБД Neo4j и ее языка запросов Cypher. А также разберем сопутствующую теорию: что такое центральность графа, почему эта мера не подходит для сетей...

Добавляя в наши курсы для дата-инженеров интересные кейсы, сегодня рассмотрим, как реализовать Лямбда-архитектуру для комплексной аналитики больших данных с помощью Apache Flink, Kafka и Cassandra на примере системы интернета вещей. Объединение пакетной и потоковой обработки данных средствами Flink API и библиотек этого фреймворка. Постановка задачи на примере IoT-системы Несмотря на...