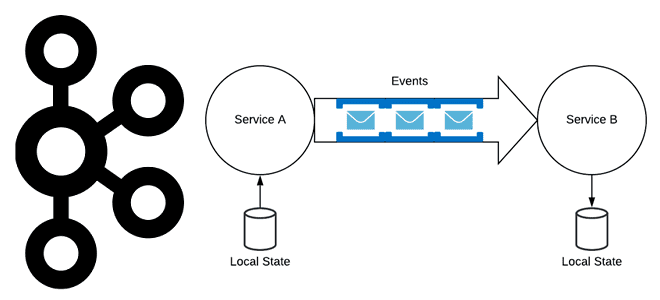
Хотя Apache Kafka часто используется в качестве шины обмена данными в микросервисной архитектуре, о чем мы писали здесь, не стоит воспринимать эту платформу как хранилище событий. В чем разница между событием и сообщением, а также другие тонкости построения микросервисной архитектуры, управляемой событиями. События vs сообщения Событие — это сообщение программной...

Использование СУБД вместо очереди сообщений считается антипаттерном, однако, команда разработки облачной системы организации конвейеров обработки данных Dagster Cloud выбрала PostgreSQL вместо Apache Kafka для регистрации событий. Разбираемся, почему плохой шаблон принес хорошие результаты и что нужно учитывать при выборе технологии. Почему не стоит использовать СУБД вместо очереди сообщений Dagster Cloud...

Мы уже писали про некоторые новинки свежего релиза Greenplum 7 здесь и здесь. Разбираемся, что еще полезного появилось в бета-версии, выпущенной 15 декабря 2022 года. А также рассмотрим, каковы ограничения этого выпуска и почему его пока нельзя использовать в production. Новые функции PostgreSQL Помимо возможности применения команды ALTER TABLE к...

Специально для обучения дата-инженеров и разработчиков распределенных программ, сегодня рассмотрим подходы к организации модульного тестирования Spark-приложений через классы тестовых данных. Зачем и как генерировать эти классы, где их хранить и при чем здесь система автоматической сборки приложений Gradle. Сборка и тестирование Spark-приложений Модульное тестирование лежит в основе проверки работоспособности программного...

Управление версиями датасетов для ML-моделей, а также версионирование самих алгоритмов машинного обучения является одной из важных задач MLOps-концепции непрерывной разработки и развертывания систем Machine Learning. Читайте, как реализовать это с помощью платформы LakeFS и фреймворка MLflow. Что такое LakeFS и при чем здесь MLOps Системы контроля версий, такие как Git,...

В рамках продвижения наших курсов по Data Science и Machine Learning, сегодня познакомимся с Python-библиотекой spaCy и русскоязычной NLP-моделью, развернув их в интерактивной среде Google Colab. В качестве практического примера решим небольшую SEO-задачу: определим части речи для каждого слова в небольшом тексте и количество их повторений. Применение библиотеки spaCy на...

Мы уже рассказывали, что Apache Flink использует Calcite для оптимизации SQL-запросов. Продолжая разбирать эту тему, важную для обучения разработчиков Flink-приложений и дата-инженеров, сегодня рассмотрим, как отследить происхождение отношения на уровне поля, используя методы класса RelMetadataQuery в Calcite. Что такое Apache Calcite и при чем здесь Flink SQL Напомним, Apache Flink...
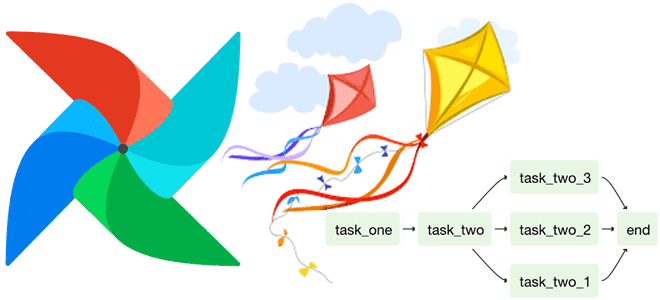
При том, что чаще всего дата-инженер работает со статическими DAG в Apache AirFlow, иногда возникает необходимость динамически менять цепочку задач пакетного конвейера обработки данных. Разбираемся, как это сделать, а также смотрим, какие достоинства и недостатки имеет каждый из 5 возможных способов. Как организовать динамическое изменение DAG в Apache AirFlow: 5...
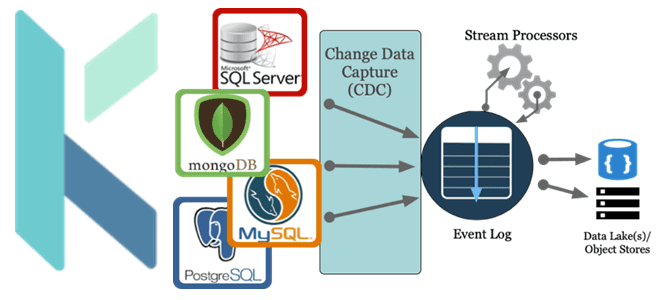
Как реализовать CDC-сценарий, используя платформу оркестрации Kestra вместо Debezium с Kafka Connect для планирования и управления конвейером обработки данных. За счет чего Kestra работает эффективнее Debezium с коннекторами Kafka Connect и при чем здесь Apache AirFlow с NiFi. Что не так с реализацией CDC на Debezium с Kafka Connect Мы...
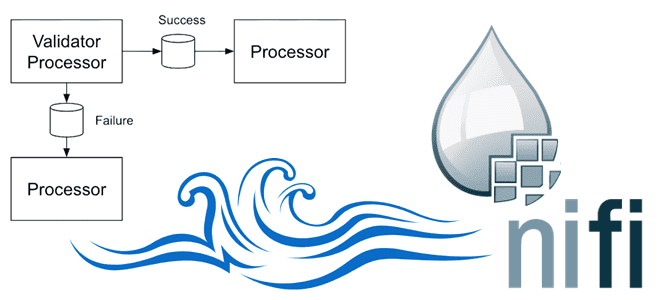
Зачем нужны средства записи и чтения в процессорах Apache NiFi и как они работают: разбираемся на примере QueryRecord, PartitionRecord и RouteText. Сходства и отличия этих процессоров, а также тонкости их использования в задачах дата-инженерии. Процессор QueryRecord в Apache NiFi Напомним, в потоковом ETL-маршрутизаторе Apache NiFi процессоры используются для прослушивания входящих...