 295
295 
При том, что чаще всего дата-инженер работает со статическими DAG в Apache AirFlow, иногда возникает необходимость динамически менять цепочку задач пакетного конвейера обработки данных. Разбираемся, как это сделать, а также смотрим, какие достоинства и недостатки имеет каждый из 5 возможных способов.
Как организовать динамическое изменение DAG в Apache AirFlow: 5 способов
AirFlow упрощает дата-инженеру моделирование конвейера обработки данных: достаточно сформировать направленный ациклический граф (DAG) из задач с операторами. Большинство DAG являются статичными, т.е. не изменяются при возникновении каких-то событий, но некоторым цепочкам задач нужно вести себя динамически при обработке данных. Например, DAG перемещает исходные файлы перед выполнением ETL-конвейера. Если источники данных определяются только во время выполнения, DAG должен динамически создавать группы ETL-задач для каждого имеющегося источника данных. Иногда исходные файлы могут отсутствовать, тогда и удалять ничего не нужно.
Есть следующие способы организовать динамическое изменение DAG в AirFlow:
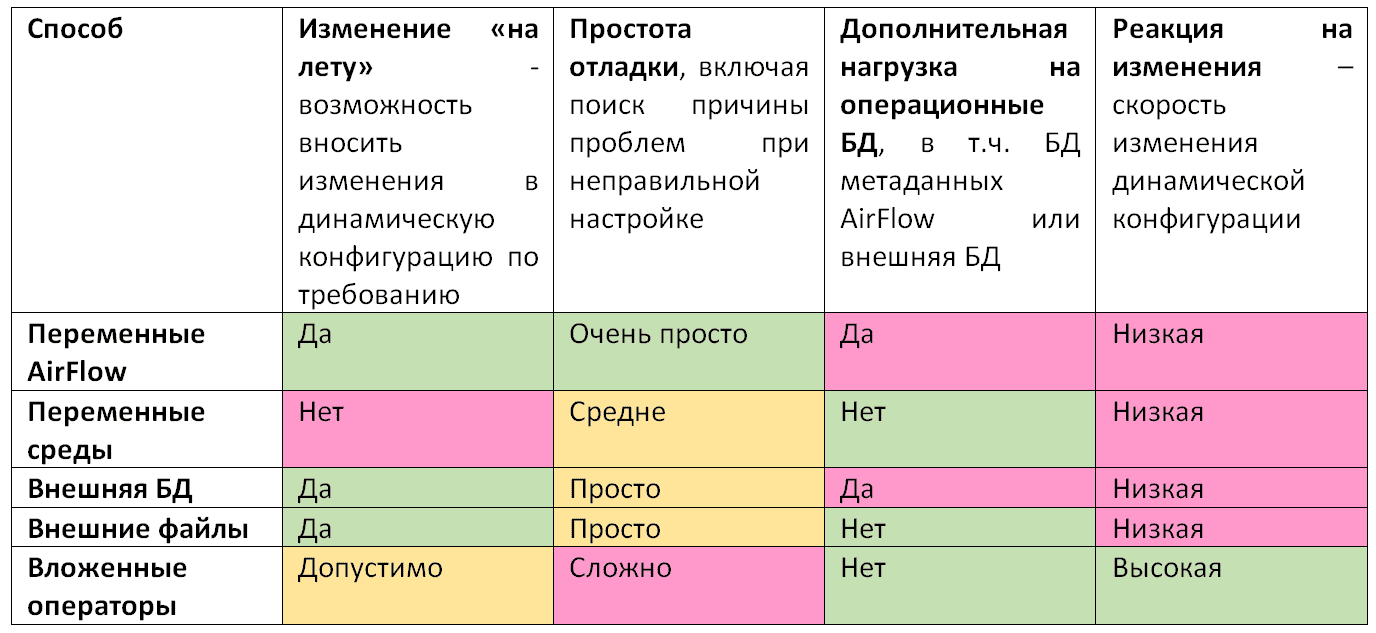
- переменные, что очень просто в реализации и отладке, но повышает нагрузку на внутреннюю базу данных метаданных этого фреймворка, снижает его производительность и масштабируемость, а также имеет ощутимую задержку, т.к. изменения переменных обрабатываются AirFlow только после того, как планировщик проанализировал и сериализовал DAG.
- переменные среды на локальной машине разработчика DAG. Извлечение динамической конфигурации выполняется исключительно на том узле, где запущен процесс планировщика AirF Этот способ не увеличивает нагрузку на базу данных метаданных и упрощает внесение изменений в динамической конфигурации DAG. Но, несмотря на высокую скорость этого способа, в реализации он не очень удобен: любое изменение динамической конфигурации требует перезапуска процесса планировщика AirFlow. Это повлечет простой других DAG, т.к. планирование задач будет приостановлено до тех пор, пока планировщик не вернется в исходное состояние.
- подключение внешней базы данных для хранения динамических конфигураций DAG. Например, это может быть MongoDB или другая документо-ориентированная NoSQL-СУБД, где удобно хранить JSON-объекты или другие подобные структуры. Однако, в этом случае рост нагрузки на внешнюю базу данных может снизить общую производительность ETL-конвейера. Кроме того, из-за обращения вовне изменения DAG не будут происходить мгновенно.
- внешние файлы Python или JSON/YAML с плоской структурой, что считается лучшей практикой организации динамического изменения DAG AirFlow в процессе изменения. Этот способ не увеличивает нагрузку на внутреннюю базу данных фреймворка: извлечение динамической конфигурации выполняется исключительно на машине, где запущен процесс планировщика AirF Но самый большой недостаток этого метода в том, что импортированный файл Python должен существовать, когда файл DAG анализируется планировщиком. Это означает, что в импортированном файле Python должно быть указано значение по умолчанию для используемой динамической конфигурации, и файл Python должен быть развернут вместе с файлами DAG в планировщике AirFlow. Причем посмотреть содержимое этого Python или JSON/YAML-файлов можно просмотреть только через отдельный инструмент, что усложняет отладку. Наконец, как и в других способах, динамические изменения не отражаются мгновенно: изменения обрабатываются только после того, как планировщик проанализировал и сериализовал DAG. Подробнее об этом способе мы писали здесь.
- вложенные операторы. Главным плюсом этого способа является высокая скорость: динамические изменения конфигурации немедленно отражаются во время выполнения. Нет необходимости ждать, пока планировщик AirFlow проанализирует и сериализует DAG, чтобы динамические изменения вступили в силу. Однако, этот способ недостаточно прозрачен, т.к. вложенные операторы не отображаются в пользовательском интерфейсе AirF Хотя можно регистрировать ход выполнения этих вложенных операторов в логах родительского оператора, на практике это не очень удобно. Кроме того, может произойти несогласованное выполнение вложенного оператора, когда динамическая конфигурация используется в нескольких местах в родительском операторе, а конфигурация изменяется между выполнением вложенных операторов. Это приводит к ошибкам, которые трудно отлаживать, поскольку для динамической конфигурации может отсутствовать история изменений. Наконец, при использовании переменных среды для хранения динамической конфигурации сложно вносить изменения в нее, которые необходимо выполнять на всех машинах, где запущен рабочий процесс AirFlow.
Чтобы резюмировать все рассмотренные способы, сделаем сравнительную таблицу.
Читайте в нашей новой статье, почему в Apache AirFlow могут возникнуть задачи-зомби, чем они опасны и как дата-инженеру бороться с ними.
Освойте приемы администрирования и эксплуатации Apache AirFlow для дата-инженерии и аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
[elementor-template id=»13619″]
Источники

