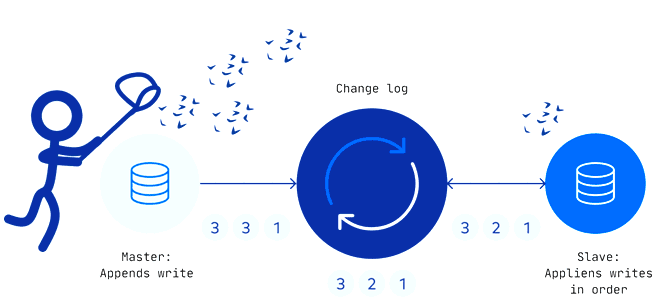
Захват измененных данных считается довольно известным паттерном организации ETL-процессов для корпоративных хранилищ и озер данных. Как реализуется CDC-технология, по каким шаблонам, что их ограничивает и чем опасен дрейф изменений в Change Data Capture. Паттерны и принципы реализации захвата измененных данных Эффективность эксплуатации озера данных зависит от ETL-процессов, поскольку объемы данных...

В этой статье рассмотрим настройку инфраструктуры Kubernetes для потоковой платформы комплексных мобильных приложений на основе Apache Kafka. Что поможет добиться оптимальной масштабируемости приложений-потребителей и высокой доступности всей Big Data системы. Проблемы масштабирования платформы Grab из приложений-потребителей Apache Kafka Grab считается ведущей платформой суперприложений в 8 странах Юго-Восточной Азии, которая предоставляет...

Сегодня рассмотрим, как оптимизировать потребление памяти в приложениях Apache Flink, разобрав основные принципы работы и конфигурации настройки памяти этого вычислительного фреймворка. А также перечислим типовые ошибки, с которыми дата-инженер может столкнуться при разработке и эксплуатации Flink-приложений Компоненты памяти в Apache Flink Apache Flink обеспечивает эффективные рабочие нагрузки поверх JVM, строго...
Мы уже писали о важности резервного копирования данных в Apache HBase на примере ИТ-компании Clairvoyant. Сегодня рассмотрим опыт индийской компании Myntra, которая предложила простую методику создания инкрементных бэкапов для Apache HBase 2.1.4 и Hadoop 2.7.3, а также восстановления нужных данных из этих резервных копий в BLOB-хранилищах по требованию пользователя. 5...

Что такое SQL-оператор VACUUM, зачем эта команда нужна в Greenplum и как она работает. Разбираемся с таблицами системного каталога и тонкостями ускорения SQL-запросов в самой популярной MPP-СУБД. Что такое сборка мусора в Greenplum и PostgreSQL Напомним, в объектно-реляционной базе данных PostgreSQL, на которой основана MPP-СУБД Greenplum, о чем мы писали...

Хотя Apache AirFlow считается достаточно зрелой платформой оркестрации рабочих процессов, при практическом использовании этого фреймворка дата-инженер может столкнуться с некоторыми сложностями. Одной из таких проблем являются так называемые «зомби-задачи». Разбираемся, чем они опасны, и как от них избавиться. Что такое зомби-задачи и чем они опасны В Unix-подобных операционных системах есть...
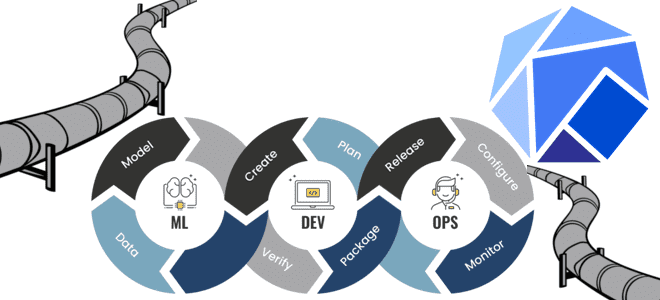
Помимо популярного MLflow от Databrics, специалисты по машинному обучению часто используют другой MLOps-инструмент – Kubeflow, о чем мы писали здесь. Сегодня разберем, как работает это средство, упрощающее разработку и развертывание конвейеров Machine Learning на платформе контейнерной виртуализации Kubernetes. Что такое конвейеры Kubeflow и как они работают Как мы уже отмечали,...
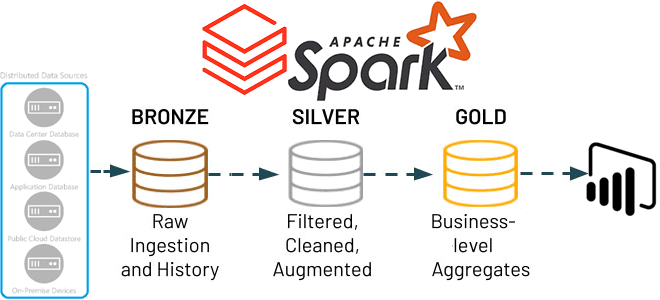
В этой статье для обучения дата-инженеров и ИТ-архитекторов рассмотрим, как Apache Spark Structured Streaming помогает реализовать самообслуживаемый сервис потоковой передачи данных в Delta Lake. А также вспомним каноническую 3-хслойную модель этого уровня хранения от Databricks. Много потоковых сценариев в одном приложении Apache Spark Structured Streaming Мы недавно писали, что архитектуры,...

Сегодня заглянем под капот Apache NiFi, чтобы понять, какие данные хранит этот потоковый ETL-маршрутизатор, зачем и где. Репозитории Apache NiFi для администратора, дата-инженера и проектировщика конвейеров обработки данных: как они устроены и какие практики улучшают их работу. Репозитории Apache NiFi: что это такое и зачем они нужны В Apache NiFi...

Зачем корпорации Confluent, которая продвигает Apache Kafka, понадобился Flink-стартап, чего ожидать от очередного слияния поглощения крупным игроком более мелкого предприятия, и какую пользу это принесет экосистеме потоковой передачи событий. Что Immerok и зачем это Confluent Год только начался, а в мире Big Data уже появились интересные новости. 6 января в...