 1209
1209 
В рамках продвижения наших курсов по Data Science и Machine Learning, сегодня познакомимся с Python-библиотекой spaCy и русскоязычной NLP-моделью, развернув их в интерактивной среде Google Colab. В качестве практического примера решим небольшую SEO-задачу: определим части речи для каждого слова в небольшом тексте и количество их повторений.
Применение библиотеки spaCy на русскоязычной ML-модели для NLP в Google Colab
Машинное обучение давно и успешно применяется для задач обработки естественного языка (NLP, Natural Language Processing). Причем современный Data Scientist не часто разрабатывает собственную ML-модель распознавания текста самостоятельно. Обычно используются готовые библиотеки, например, spaCy. Эта библиотека с открытым исходным кодом для NLP, написанная на Python и Cython. В отличие от пакета NLTK, который чаще применяется для обучения и исследований, spaCy широко используется в реальных проектах.
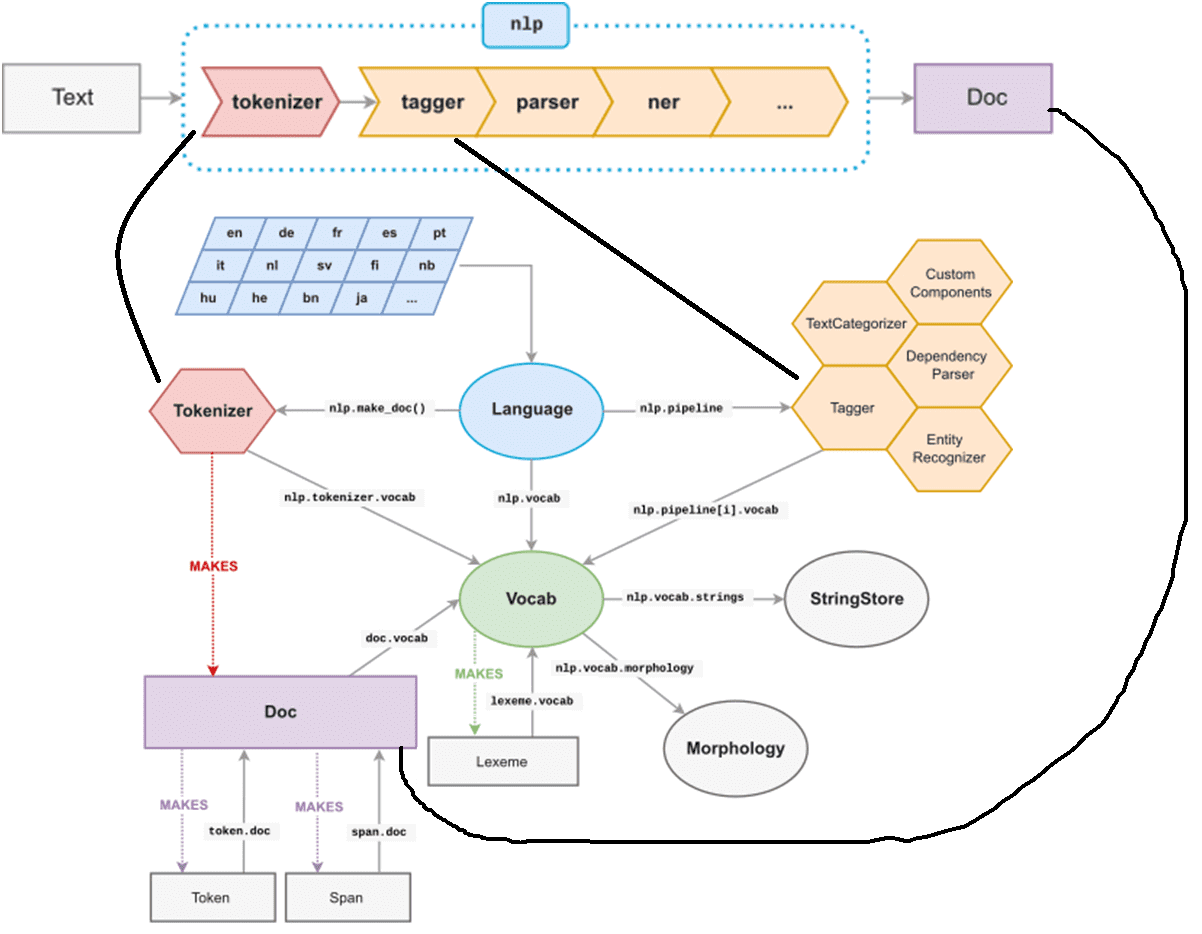
Центральными структурами данных в spaCy являются объекты документ (Doc) и словарь (Vocab):
- Doc хранит последовательности токенов и все их аннотации. Он создается объектом Tokenizer, а затем модифицируется внутренними компонентами конвейера, которые координируются объектом Language. Он берет необработанный текст и отправляет его по конвейеру, возвращая аннотированный документ.
- Vocab хранит набор справочных таблиц, что делает общую информацию доступной для всех документов. Благодаря централизованному хранению в словаре строк, векторов слов и лексических атрибутов нет необходимости хранить несколько копий этих данных, что экономит память и обеспечивает единый источник истины.
Текстовые аннотации нужны для обеспечения единого источника истины: объект Doc владеет данными, а Span и Token являются представлениями, указывающими на них.
Чтобы продемонстрировать пример использования библиотеки spaCy для NLP-задач, воспользуемся интерактивной средой Google Colab. Сперва нужно установить библиотеку:
! pip install spacy
SpaCy обучить собственные ML-модели или загрузить предварительно обученные статистические алгоритм для разных задач. В рамках этой демонстрации будем использовать предварительно обученную модель на русском языке ru_core_news_sm. Это NLP-конвейер, включающий несколько компонентов, таких как токенизатор, синтаксический анализатор, лемматизатор и пр. Чтобы загрузить эту модель, выполним в Google Colab следующую инструкцию:
! python -m spacy download ru_core_news_sm
При применении NLP-методов к тексту, spaCy разбивает этот текст на токены, получая объект Doc, который содержит последовательность объектов класса Token и другую полезную информацию. Затем объект Doc последовательно обрабатывается в несколько шагов, что называется конвейером. В стандартных ML-моделях конвейер состоит из нескольких компонентов, которые тегируют, выполняют синтаксический анализ и распознавание сущностей в тексте. Каждая компонента принимает на вход объект Doc и возвращает его расширенную версию с новыми атрибутами для каждого токена или для всего объекта в целом.
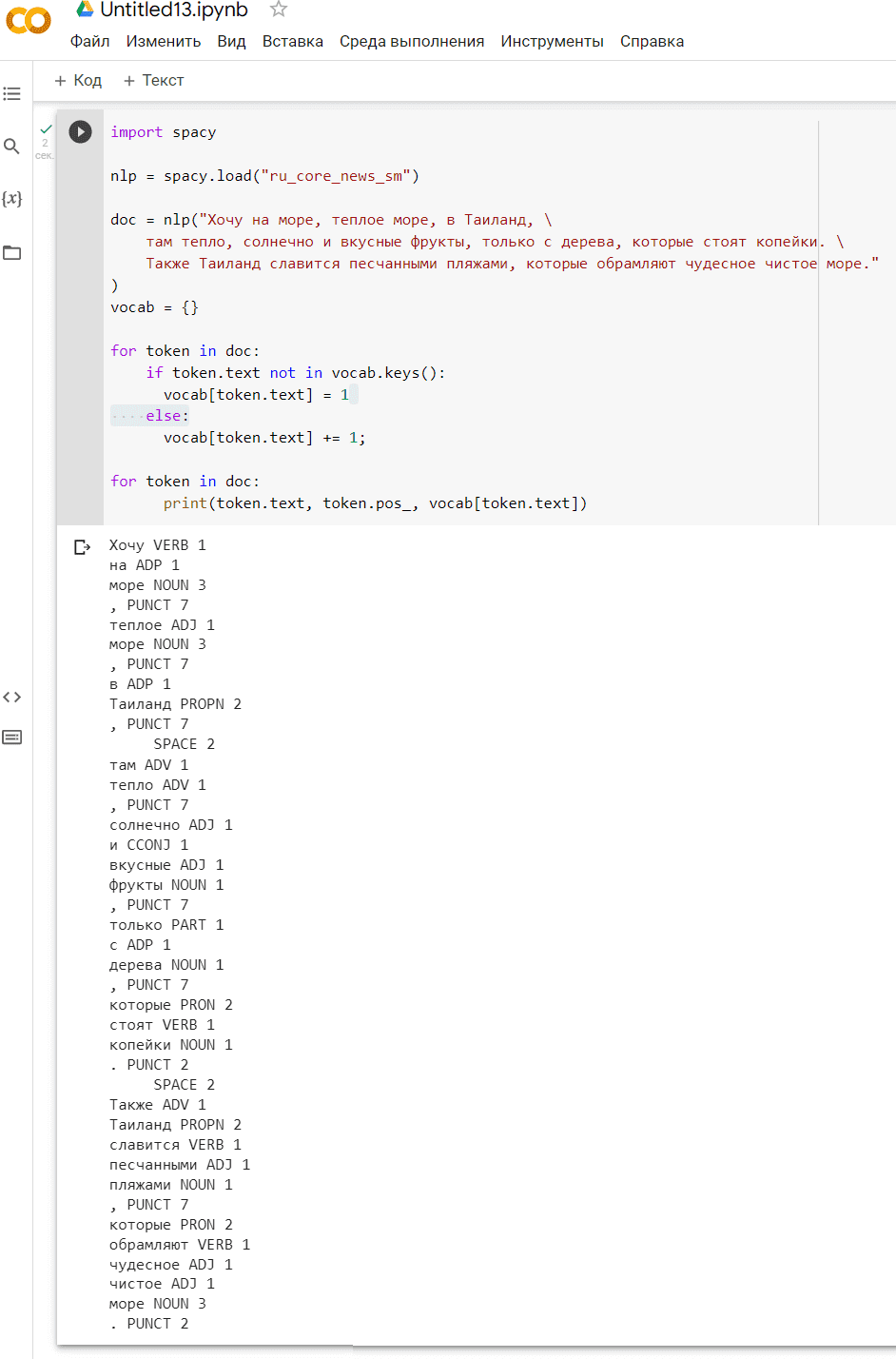
В качестве практического примера решим небольшую SEO-задачу: определим части речи для каждого слова в небольшом тексте и количество их повторений. Для этого импортируем библиотеку spaCy в свой Python-скрипт, загрузим библиотеку с обученной русскоязычной ML-моделью и с помощью готовых методов определим, к какой части речи относится каждое слово в следующем тексте, а также сколько раз оно встречается. В качестве анализируемого текста зададим следующую пару предложений:
Хочу на море, теплое море, в Таиланд, там тепло, солнечно и вкусные фрукты, только с дерева, которые стоят копейки. Также Таиланд славится песчаными пляжами, которые обрамляют чудесное чистое море.
Скрипт в Google Colab выглядит следующим образом:
import spacy
nlp = spacy.load("ru_core_news_sm")
doc = nlp("Хочу на море, теплое море, в Таиланд, \
там тепло, солнечно и вкусные фрукты, только с дерева, которые стоят копейки. \
Также Таиланд славится песчаными пляжами, которые обрамляют чудесное чистое море."
)
vocab = {}
for token in doc:
if token.text not in vocab.keys():
vocab[token.text] = 1
else:
vocab[token.text] += 1;
for token in doc:
print(token.text, token.pos_, vocab[token.text])
Получим следующий результат:
В заключение отметим, что именно по рассмотренному принципу выделения одних и тех же слов с подсчетом количества их повторов в тексте работают различные SEO-сервисы, которые используются для поискового продвижения сайтов.
Как применить эти и другие методы и средства NLP для аналитики больших данных в реальных проектах Machine Learning, вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
[elementor-template id=»13619″]
Источники

