Почему запросы Flink SQL перестают работать эффективно при больших объемах несбалансированном распределенных данных и как это исправить с помощью мини-пакетной агрегации. Что такое MiniBatch, как это работает и чем может опасно. Перекос данных по ключу группировки в Apache Flink Flink SQL — это мощный инструмент, объединяющий пакетную и потоковую обработку...
Как кодек сжатия snappy может вызвать ошибку нехватки памяти на брокерах, что может нарушить пользовательская JAAS-конфигурация клиента с протоколом безопасности на основе SASL и еще 4 уязвимости Apache Kafka в 2023 и 2022 гг. Уязвимости Apache Kafka 2023 года В 2023 году обнаружена уязвимость CVE-2023-34455, связанная с тем, что клиенты,...

23 июня 2023 года опубликован очередной релиз Apache Spark 3.4.1, который считается отладочным выпуском для предыдущего, содержащий исправления стабильности. Помимо исправления ошибок, в нем также 16 новых фичей и более 20 улучшений, самые главные из которых мы рассмотрим далее. Исправления ошибок и новые фичи Apache Spark 3.4.1 Поскольку выпуск считается...
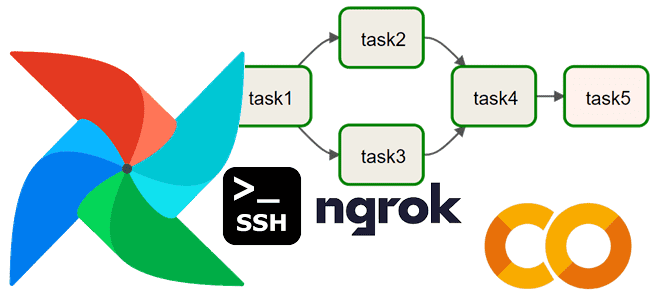
Сегодня рассмотрим, как выполнить DAG Apache AirFlow, запустив его в интерактивной среде Colab и получив доступ в веб-GUI этого фреймворка, создав туннель локального хоста на публичный URL с помощью утилиты ngrok. В качестве примера построим простой конвейер из 5 задач. Запуск Apache AirFlow в Google Colab Чтобы не повторять содержимое...

Зачем биомедикам понадобился свой язык описания онтологий, как эти задачи решает BioCypher и при чем здесь Neo4j: практическое приложение Data Science и графовых алгоритмов в биомедицинской сфере. Что такое BioCypher Графовые алгоритмы активно применяются в биомедицине для анализа различных биологических данных, таких как геномные, протеомные, данные о белковых взаимодействиях и...
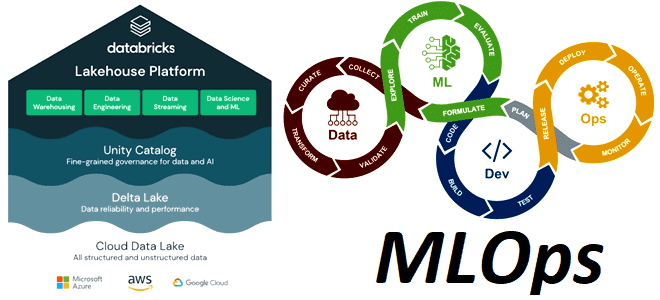
Мы уже писали, какие инструменты пригодятся MLOps-инженеру для развертывания моделей машинного обучения в производственных средах. Сегодня рассмотрим, как сделать это, используя MLOps-паттерны и средства платформы Databricks Lakehouse. MLOps в production: шаблоны развертывания на платформе Databricks MLOps представляет собой набор лучших практик и инструментов для автоматизации управления кодом, данными и моделями,...

15 июня 2023 года опубликован очередной выпуск самой популярной распределенной платформы потоковой передачи событий. Разбираемся с новинками Apache Kafka 3.5.0, особенно важными для разработчиков, дата-инженеров и администраторов кластера. Обновления брокеров, контроллеров, продюсеров и потребителей Релиз Apache Kafka 3.5.0 богат на новинки: в нем 50 улучшений и почти 80 исправленных ошибок....
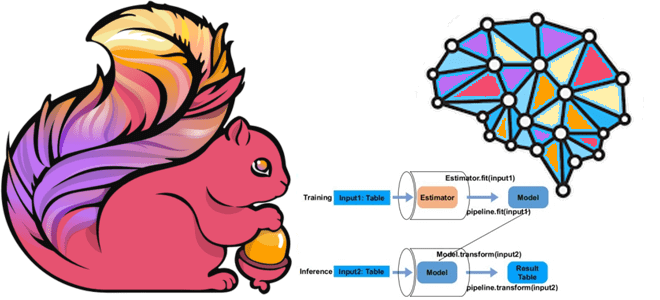
Как построить конвейер машинного обучения с помощью библиотеки Flink ML, из каких компонентов она состоит и как работает, а также что позволяет объединить алгоритмы потоковой обработки данных Apache Flink с ML-моделями. Что такое Flink ML Помимо MLeap, библиотеки сериализации для моделей машинного обучения, Apache Flink также включает Flink ML —...

Как расширить возможности MPP-СУБД Greenplum, используя фоновые рабочие процессы и почему это небезопасно. А также рассмотрим, что такое API Greenplum Partner Connector и как это использовать. Фоновые рабочие процессы Обычно фоновыми процессами в СУБД называются системные задания, которые запускаются при запуске базы данных и выполняют различные служебные задачи. К таким рутинным сервисным задачам...
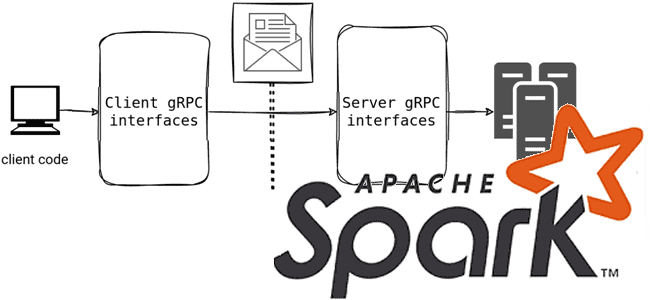
Мы уже писали, что в выпуске 3.4.0 от апреля 2023 года Spark Connect представил несвязанную архитектуру клиент-сервер, которая обеспечивает удаленное подключение к кластерам Spark из любого приложения, работающего в любом месте. Сегодня рассмотрим подробнее, как это работает и каковы плюсы для практического использования. Что такое Spark Connect и зачем это...