Как построить конвейер машинного обучения с помощью библиотеки Flink ML, из каких компонентов она состоит и как работает, а также что позволяет объединить алгоритмы потоковой обработки данных Apache Flink с ML-моделями.
Что такое Flink ML
Помимо MLeap, библиотеки сериализации для моделей машинного обучения, Apache Flink также включает Flink ML — библиотеку, которая предоставляет API-интерфейсы Machine Learning и инфраструктуры, упрощающие создание ML-конвейеров. Пользователи могут реализовывать алгоритмы Machine Learning с помощью стандартных API-интерфейсов машинного обучения и в дальнейшем использовать эти инфраструктуры для построения ML-конвейеров для обучения и логических выводов.
API Flink ML основан на табличном API этого фреймворка, который представляет собой интегрированный в язык API запросов для Java, Scala и Python, позволяющий составлять запросы из реляционных операторов, включая выборку, фильтрацию и соединение. Дополнительно к набору типов данных, который поддерживает Table API, Flink ML также обеспечивает поддержку векторов с двойными значениями, включая плотные (DenseVector) и разреженные (SparseVector). Каждый вектор инициализируется с фиксированным размером, и пользователи могут получить или установить двойное значение любого положения индекса, начиная с 0. Flink ML также имеет класс с именем Vectors, предоставляющий служебные методы для создания экземпляров векторов.
Основным компонентом Flink ML является этап (Stage) – узел в конвейере (Pipeline) или графе (Graph). Этот интерфейс является только концепцией и не имеет реальной имплементации, в отличие от его подклассов:
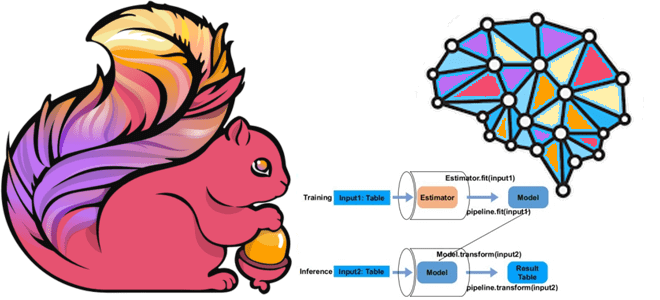
- Оценщик (Estimator) отвечает за процесс обучения алгоритмам машинного обучения, реализуя метод fit(), который берет список таблиц и создает файл модели.
- Алгоритмический оператор (AlgoOperator) используется для кодирования общей логики вычислений с несколькими входами и несколькими выходами. Он реализует метод transform() , который применяет определенную логику вычислений к заданным входным таблицам и возвращает список таблиц результатов.
- Трансформер (Transformer), в отличие от AlgoOperator, кодирует логику преобразования, так что запись на выходе обычно соответствует одной записи на входе. Поэтому AlgoOperator лучше подходит для выражения логики агрегирования, когда запись в выходных данных может быть вычислена из произвольного числа записей во входных данных.
- Модель (Model) дополняет API трансформера для установки и получения данных модели, что обычно генерируется путем подгонки Estimator к списку таблиц. Этот класс имеет методы getModelData() и setModelData(), что позволяет пользователям явно читать или записывать таблицы данных модели в трансформер. Каждая таблица может быть неограниченным потоком изменений данных модели.
Типичное использование Stage состоит в том, чтобы создать экземпляр Estimator, запустить процесс его обучения, вызвав метод fit(), и выполнить прогнозы с результирующим экземпляром модели.
Чтобы организовать этапы Flink ML в более сложный формат для достижения расширенных функций, таких как объединение алгоритмов обработки данных и машинного обучения, Flink ML предоставляет API-интерфейсы, которые помогают управлять взаимосвязью и структурой этапов в заданиях Flink. Запись этих API включает Pipeline и Graph, о которых мы поговорим далее.
Построение конвейеров машинного обучения
Pipeline действует как Estimator, поскольку состоит из упорядоченного списка этапов, каждый из которых может быть оценщиком. Его метод последовательно проходит все этапы этого конвейера, выполняя следующие действия:
- Если этап является Estimator, он вызовет метод fit() этапа с входными таблицами для создания Model. Последующий Estimator будет преобразовывать входные таблицы, используя сгенерированные модели для получения таблиц результатов, а затем передавать таблицы результатов на следующий этап в качестве входных данных.
- Если этап представляет собой AlgoOperator, Estimator после этого этапа преобразует входные таблицы, используя предыдущий этап, чтобы получить таблицы результатов, а затем передает таблицы результатов на следующий этап в качестве входных данных.
После того, как все оценщики будут обучены соответствовать своим входным таблицам, модель конвейера (PipelineModel) создает новый конвейер с теми же этапами, заменив все оценщики моделями, сгенерированными в описанном выше процессе. PipelineModel действует как модель и состоит из упорядоченного списка этапов, каждый из которых может быть Model или Transformer. В случае AlgoOperator метод transform() применяет все этапы PipelineModel к входным таблицам по порядку. Выход одного этапа используется как вход следующего этапа при его наличии. Вывод последнего этапа возвращается как результат этого метода. Конвейер можно создать, передав список этапов в конструктор Pipeline.
Graph также действует как Estimator и представляет собой направленный ациклический граф (DAG) этапов, каждый из которых может быть Estimator, Model, Transformer или AlgoOperator. При вызове метода fit() этапы выполняются в топологически отсортированном порядке. Если этап является оценщиком, его метод fit() будет вызываться для входных таблиц из входных ребер, чтобы соответствовать модели. Далее он будет использоваться для преобразования входных таблиц и создания выходных таблиц для выходных ребер. Если этап является AlgoOperator, его метод transform() будет вызываться для входных таблиц и создавать выходные таблицы для выходных ребер. Подгонка GraphModel из Graph состоит из подгонки Models и AlgoOperators, соответствующих этапам Graph.
GraphModel действует как Model и также состоит из DAG этапов, каждый из которых может быть Estimator, Model, Transformer или AlgoOperator. При вызове transform() этапы выполняются в топологически отсортированном порядке. Когда этап выполняется, метод transform() для AlgoOperator будет вызываться для входных таблиц от входных ребер и создавать выходные таблицы для выходных ребер. Graph может быть построен с помощью класса GraphBuilder, который предоставляет методы addAlgoOperator() или addEstimator() для добавления этапов в граф. Во Flink ML также есть класс TableId для представления ввода/вывода этапа, который помогает выразить взаимосвязь между этапами в графе, что позволяет пользователям создавать DAG еще до доступности конкретных таблиц.
Будучи базовой концепцией Flink ML, технически этап является подклассом WithParams, который предоставляет единый API для получения и установки параметров. Param — это определение параметра, включая имя, класс, описание, значение по умолчанию и валидатор. Установить параметр алгоритма можно любым из следующих способов:
- вызвать специальный метод установки параметра. Например, чтобы установить K-число кластеров алгоритма K-средних, можно напрямую вызывать метод setK() для этого экземпляра.
- Передать сопоставление параметров, содержащих новые значения, в метод этапа ParamUtils.updateExistingParams().
Если Model генерируется с помощью fit()-метода Estimator, он унаследует параметры объекта Estimator. Таким образом, нет необходимости устанавливать параметры во второй раз, если параметры не изменились.
Главным строительным блоком для ML-библиотеки является итерация, которая может использоваться в автономном или онлайн-процессе обучения. Flink ML поддерживает два типа итераций, чтобы обеспечить инфраструктуру для различных алгоритмов:
- Ограниченная итерация обычно используется в автономном режиме, когда ML-алгоритм обучается на ограниченном наборе данных, обновляя параметры для нескольких раундов до сходимости.
- Неограниченная итерация обычно используется в случае онлайн-обучения, когда алгоритм тренируется на неограниченном наборе данных, накапливая мини-пакет данных, а затем выполняет одно обновление параметров.
Итеративный алгоритм имеет тело итерации, которое повторно вызывается до тех пор, пока не будут достигнуты некоторые критерии завершения, заданное пользователем количество эпох. Тело итерации — это подграф операторов, который реализует логику вычислений, например, алгоритма итеративного машинного обучения, чьи выходные данные могут быть возвращены в качестве входных данных этого подграфа. При каждом вызове тело итерации обновляет параметры модели на основе предоставленных пользователем данных, а также самых последних параметров модели. Итеративный алгоритм принимает в качестве входных данных предоставленные пользователем данные и исходные параметры модели, и может выводить запрашиваемую пользователем информацию, такую как потери после каждой эпохи или окончательные параметры модели.
Таким образом, тело итерации — это подграф Flink со входными данными в виде переменных модели (список потоков данных) и предоставленных пользователем данные (другой список потоков данных). Выходными данными в виде списка потоков данных являются переменные модели обратной связи и пользовательские выходные данные. Условие завершения указывает, когда итеративное выполнение тела итерации должно быть прекращено. Чтобы выполнить тело итерации, пользователю необходимо выполнить тело итерации со входными данными в виде списка ограниченных или неограниченных потоков данных и получить выходные данные.
Важно отметить, что переменные модели, ожидаемые телом итерации, не совпадают с переменными начальной модели, предоставленными пользователем. Вместо этого переменные модели вычисляются как объединение переменных модели обратной связи, выдаваемых телом итерации, и переменных исходной модели, предоставляемых вызывающей стороной. Во Flink ML есть служебный класс для запуска тела итерации с входными данными, предоставленными пользователем.
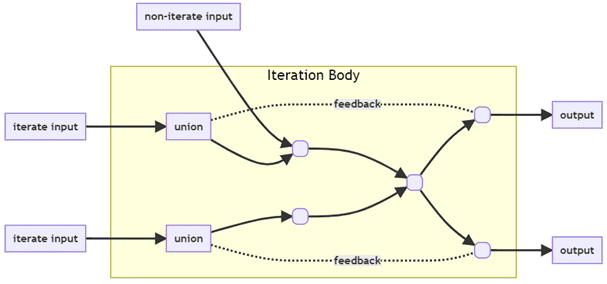
Основная запись итерации Flink ML находится в классе Iterations, который предоставляет два общедоступных метода для ограниченных и неограниченных потоков данных.
Чтобы построить итерацию, разработчик приложения Flink ML должен задать следующие переменные:
- initVariableStreams – начальные значения переменных потоков данных, которые будут обновляться в каждом раунде;
- dataStreams – другие потоки данных, используемые внутри итерации, но не обновляемые;
- iterationBody – подграф для обновления переменных потоков и выходов.
IterationBody вызывается с двумя параметрами: список потоков входных переменных, которые создаются как объединение исходных потоков переменных и соответствующих потоков переменных обратной связи, возвращаемых телом итерации, а также сами потоки данных, отдаваемые этому методу.
Во время выполнения тела итерации к каждой записи, участвующей в итерации, прикрепляется эпоха, которая отмечает ход итерации. Эпоха вычисляется следующим образом:
- все записи в исходных потоках переменных и исходных потоках данных имеют эпоху = 0;
- для любой записи, испускаемой этим оператором в поток без обратной связи, эпоха этой записи равна эпохе входной записи, которая ее запустила. Если запись создается функцией onEpochWatermarkIncremented(), то эпоха этой записи равна эпохе водяного знака (epochWatermark).
- для любой записи, испускаемой оператором в переменный поток обратной связи, эпоха равна запустившей ее эпохе входной записи + 1.
В конце каждой эпохи фреймворк уведомляет операторов и UDF, которые реализуют слушатель итерации (IterationListener).
Узнайте больше про использование Apache Flink для потоковой обработки событий в распределенных приложениях аналитики больших данных и машинного обучения на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

