 992
992 
Содержание
Почему запросы Flink SQL перестают работать эффективно при больших объемах несбалансированном распределенных данных и как это исправить с помощью мини-пакетной агрегации. Что такое MiniBatch, как это работает и чем может опасно.
Перекос данных по ключу группировки в Apache Flink
Flink SQL — это мощный инструмент, объединяющий пакетную и потоковую обработку средствами стандартных SQL-запросов. Table API и SQL Flink позволяют разработчику создавать эффективные приложения потоковой аналитики, а также поддерживают множество оптимизаций запросов и настроенных реализаций операторов. Однако, не все оптимизации включены по умолчанию, поэтому для некоторых рабочих нагрузок целесообразно сделать это вручную, изменив некоторые параметры конфигурации.
В частности, такая необходимость возникает в ситуациях, когда по мере масштабирования рабочей нагрузки задания SQL, которые раньше работали хорошо на меньших объемах данных, начинают тормозить или даже выходить из строя. Чаще всего это случается из-за так называемых искаженных данных или перекосов, когда данные распределены неравномерно по некоторым признакам. Перекос данных относится к асимметрии распределения вероятностей переменной относительно ее среднего значения. Подробнее об этом мы писали здесь.
Рассмотрим пример пользовательского поведения в интернет-магазине. Таблица Users содержит информацию о пользователях и DDL-запрос на ее создание выглядит так:
CREATE TABLE `Users` ( `uid` BIGINT, `name` STRING, `country` STRING, `zcode` STRING ) ;
А таблица GenOrders содержит информацию о заказах и имеет следующую схему:
CREATE TEMPORARY TABLE `GenOrders` ( `uid` BIGINT, `oid` BIGINT, `category` STRING, `price` DECIMAL(3, 2) ) ;
Чтобы узнать количество заказов на одного пользователя в таблице Users, необходимо соединить эти таблицы, сопоставив идентификаторы клиентов с помощью JOIN-оператора в SQL-запросе на выборку данных:
SELECT o.uid, COUNT(o.oid) FROM GenOrders o JOIN Users u ON o.uid = u.uid GROUP BY o.uid;
Однако, в случае потоковой обработки информации обе таблицы представляют собой непрерывные потоки. В Apache Flink агрегирующие функции, к которым относятся COUNT и SUM, выполняются stateful-операторами агрегации. Оператор агрегации отслеживает состояние, сохраняя в нем промежуточные результаты агрегирования. По умолчанию операторы потоковой агрегации обрабатывают входные записи одну за другой, работая с аккумуляторами, т.е. накопителями, общими переменными, которые могут накапливать значения на рабочих узлах в распределенной среде. Они добавляются только посредством ассоциативной и коммутативной операции и поэтому могут эффективно поддерживаться параллельно. Подробнее про аккумуляторы читайте здесь на примере Apache Spark.. Когда поступает запись, оператор выполняет следующие шаги:
- извлекает из состояния аккумулятор;
- накапливает/извлекает запись в аккумулятор;
- сохраняет аккумулятор обратно в состояние.
Каждое чтение/запись состояния имеет определенную стоимость, т.е. усилия, необходимые программе для выполнения этих операций обработки данных. Поэтому такой шаблон обработки данных может увеличить нагрузку на бэкэнд состояния, особенно для key-value базы RocksDB, которая часто используется в Apache Flink в качестве бэкенда состояния, о чем мы писали здесь.
В крупномасштабных приложениях Flink потоки часто разделяются на основе определенных ключей (ключи группировки) и распределяются на несколько задач для параллельной обработки. Если распределение записей неравномерно, то одни задачи будут тяжеловеснее других, т.е. на их выполнение уйдет больше времени. Это может стать узким местом конвейера обработки данных. Причиной такого неэффективного поведения распределенной программы становится перекос ключа группировки.
Для вышерассмотренного примера с пользователями интернет-магазина можно распределить записи по идентификатору пользователя для параллельного выполнения задач агрегирования. Поскольку необходимо найти количество заказов на одного пользователя, имеет смысл сгруппировать данные по идентификатору пользователя. Чтобы визуализировать ситуацию с перекосом данных по ключу группировки, раскрасим записи для разных пользователей различными цветами. Например, у пользователя, чьи записи отмечены красным цветом, намного больше записей, чем у других. Если распределить данные по идентификатору пользователя, то задача агрегации, которая обрабатывает записи пользователя, отмеченного красным цветом, займет намного больше времени, чем аналогичные задачи для других пользователей. В данном примере к базе данных, где хранятся состояния, т.е. бэкенду состояния, придется обратиться 15 раз, что довольно много.
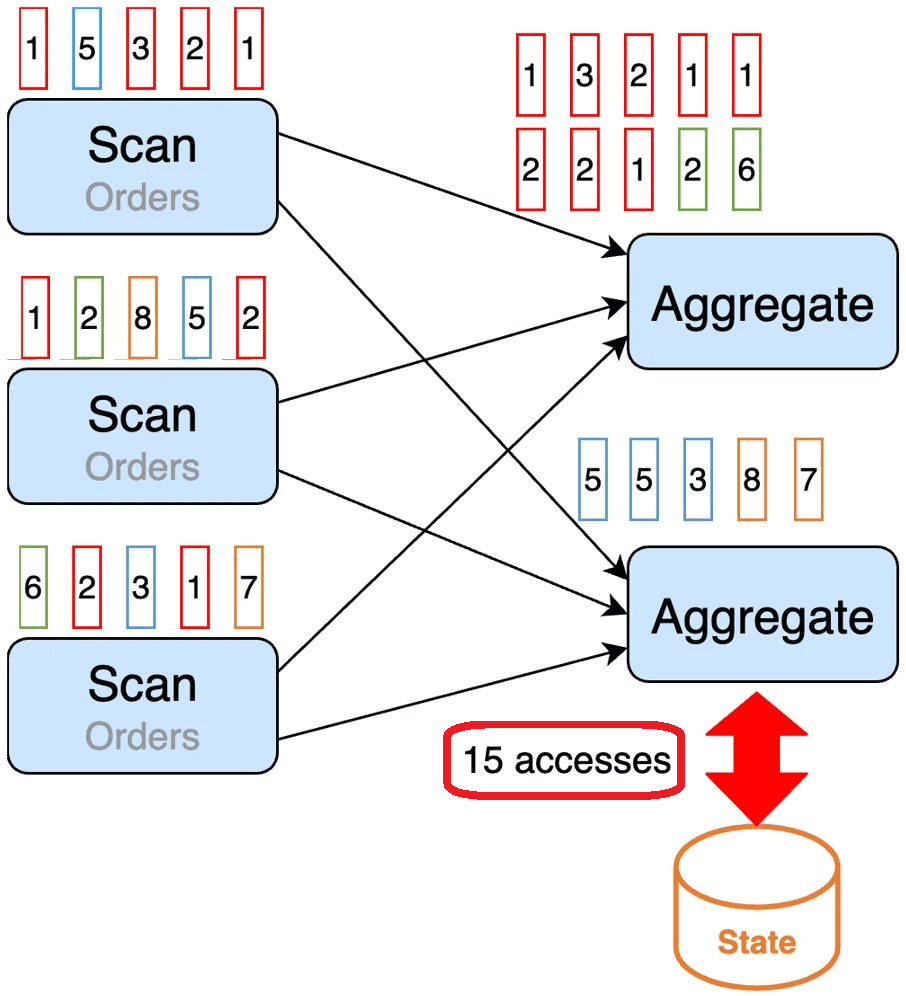
Исправить эту ситуацию поможет такой прием, как мини-пакетная агрегация, смысл которой мы рассмотрим далее.
Как работает мини-пакетная агрегация потоковых таблиц
Мини-пакетная агрегация (MiniBatch) помещает входные записи в буфер и выполняет операцию агрегации после заполнения буфера или через некоторое время. Таким образом, записи с одним и тем же значением ключа в буфере обрабатываются вместе, создавая единственную запись состояния для каждого значения ключа в пакете.
Основная идея мини-пакетной агрегации заключается в кэшировании пакета входных данных в буфере внутри оператора агрегации. Когда набор входных данных запускается для обработки, требуется только одна операция для каждого ключа для доступа к состоянию. Это значительно снижает накладные расходы состояния и повышает пропускную способность. Оптимизация MiniBatch отключена по умолчанию для группового агрегирования. Чтобы включить эту оптимизацию, следует установить параметры table.exec.mini-batch.enabled, table.exec.mini-batch.allow-latency и table.exec.mini-batch.size. Например, в Python-коде это будет выглядеть следующим образом:
# instantiate table environment
t_env = ...
# access flink configuration
configuration = t_env.get_config()
# set low-level key-value options
configuration.set("table.exec.mini-batch.enabled", "true") # enable mini-batch optimization
configuration.set("table.exec.mini-batch.allow-latency", "5 s") # use 5 seconds to buffer input records
configuration.set("table.exec.mini-batch.size", "5000") # the maximum number of records can be buffered by each aggregate operator task
Важно отметить, что оптимизация MiniBatch всегда включена для Window TVF Aggregation независимо от приведенной выше конфигурации. Буфер агрегации Window TVF записывает в управляемую память, а не в кучу JVM, поэтому нет риска перегрузки сборщика мусора (Garbage Collector) или проблем с нехваткой памяти (OOM, Out of Memory).
В общем случае, агрегация MiniBatch повышает пропускную способность, поскольку операторы агрегации имеют меньше доступа к состоянию и выводят меньше записей. Особенно это заметно, когда есть сообщения об отклике, а производительность нижестоящих операторов не очень высока.
В частности, для вышерассмотренного примера количество обращений к базе данных, где хранятся состояния, сократится почти в 4 раза за счет буферизации в мини-пакетной агрегации.
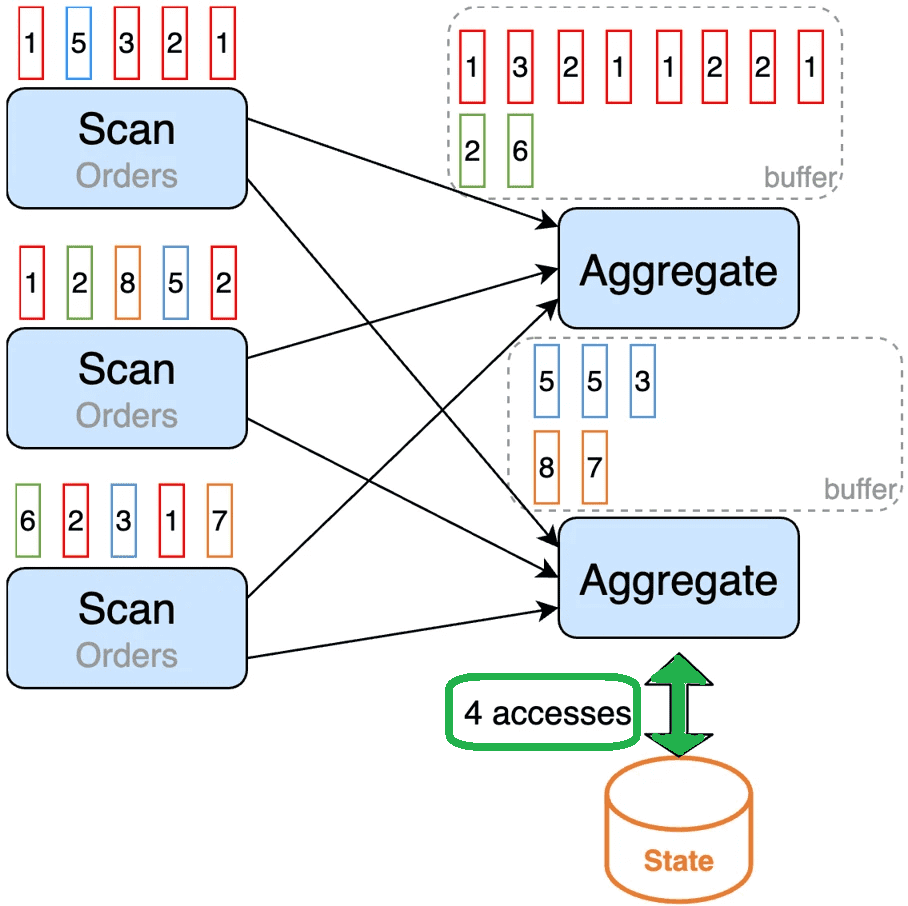
В заключение отметим, что обратной стороной мини-пакетной агрегации является возможное увеличение задержки обработки данных, поскольку операторы агрегации начинают обрабатывать записи тогда, когда буфер заполняется или истекает время его ожидания вместо мгновенной обработки. Получается, снова возникает вечный компромисс потоковых приложений между пропускной способностью и задержкой, решение которого зависит от приоритизации нефункциональных требований и бизнес-контекста.
Узнайте больше про использование Apache Flink для потоковой обработки событий в распределенных приложениях аналитики больших данных и машинного обучения на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
[elementor-template id=»13619″]
Источники

