609
609 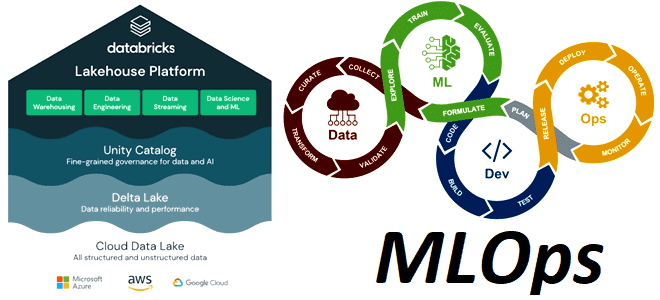
Содержание
Мы уже писали, какие инструменты пригодятся MLOps-инженеру для развертывания моделей машинного обучения в производственных средах. Сегодня рассмотрим, как сделать это, используя MLOps-паттерны и средства платформы Databricks Lakehouse.
MLOps в production: шаблоны развертывания на платформе Databricks
MLOps представляет собой набор лучших практик и инструментов для автоматизации управления кодом, данными и моделями, направленных на устранение организационных и технических разрывов между этапами и участниками процессов создания и развертывания систем Machine Learning. Эта концепция сочетает в себе элементы DevOps, DataOps и ModelOps. Ресурсы машинного обучения, такие как код, данные и модели, разрабатываются поэтапно, с относительно свободной стадии разработки через промежуточную стадию тестирования и конечную стадию производства, которая строго контролируется. Databricks Lakehouse позволяет управлять этими активами на единой платформе с унифицированным контролем доступа. MLOps-инженер может разрабатывать приложения для анализа данных и приложений машинного обучения на одной платформе, что снижает риски и задержки, связанные с перемещением данных.
Важным элементом жизненного цикла ML-модели является среда выполнения – место, где модели и данные создаются или используются кодом. Каждая среда выполнения состоит из вычислительных экземпляров, их сред выполнения и библиотек, а также автоматизированных заданий. Databricks рекомендует создавать отдельные среды для разных этапов кода машинного обучения и разработки моделей с четко определенными переходами между этапами.
В большинстве случаев Databricks рекомендует в процессе разработки машинного обучения перемещать код, а не модели Machine Learning, из одной среды в другую. Такое перемещение ресурсов проекта гарантирует, что весь код в процессе разработки системы машинного обучения проходит одни и те же процессы проверки кода и интеграционного тестирования. Кроме того, именно такой вариант развертывания гарантирует, что производственная версия модели обучена производственному коду.
Однако, возможны два шаблона перемещения артефактов машинного обучения через промежуточную стадию и в рабочую среду. Асинхронный характер изменений моделей и кода означает, что существует несколько альтернативных паттернов, которым может следовать процесс разработки машинного обучения. Модели создаются кодом, но результирующие артефакты модели и создавший их код могут работать асинхронно. Это означает, что новые версии модели и изменения кода могут происходить не одновременно, в зависимости от различных вариантов использования. Например, для обнаружения мошеннических финансовых транзакций ML-конвейер еженедельно переобучает модель. Код меняется не очень часто, но сама модель переобучается каждую неделю для включения новых данных. А в случае классификации документов понадобится большая нейросеть Deep Learning, обучение которой требует значительных вычислительных ресурсов и времени, но переобучение модели происходит нечасто. При этом код, который развертывает, обслуживает и отслеживает эту модель, можно обновить без ее повторного обучения.
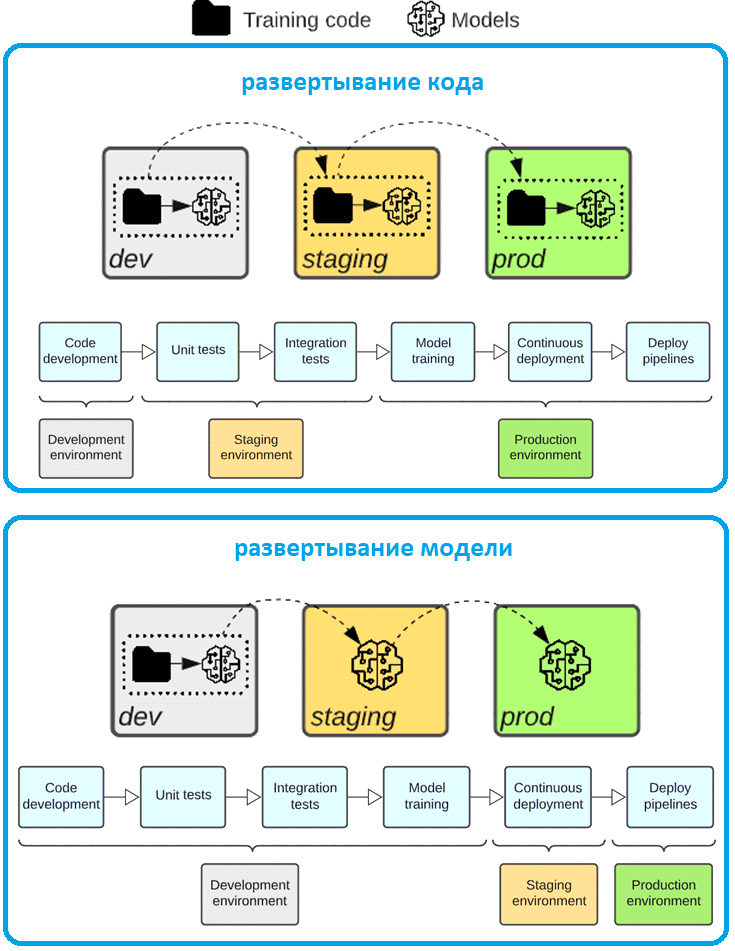
Таким образом, шаблоны развертывания отличаются тем, что перемещается в производственную среду: артефакт модели или обучающий код, создающий этот артефакт модели. Каковы достоинства и недостатки каждого из этих паттернов, рассмотрим далее.
Развертывание кода
В большинстве случаев Databricks рекомендует применять подход с развертыванием кода, когда код для обучения моделей разрабатывается в среде разработки. Тот же код перемещается в промежуточную (тестовую), а затем в рабочую среду. Модель обучается в каждой среде: сначала в среде разработки, затем в тестовой среде на ограниченном подмножестве данных в рамках интеграционных тестов, и, наконец, в производственной среде на полных производственных данных для создания окончательной модели.
Основными преимуществами этого подхода являются следующие:
- возможность обучать модель на рабочих данных в производственной среде, что особенно важно для компаний, где доступ к производственным данным ограничен;
- безопасное автоматическое переобучение модели, поскольку обучающий код проверяется, тестируется и утверждается для производства;
- одинаковая схема кода обучения модели, включая этап интеграционного тестирования.
Однако, этот подход предполагает высокий порог входа для специалистов по данным и наличие предопределенных шаблонов для проектов и рабочих процессов. Кроме того, такой паттерн развертывания основан на необходимости предварительного просмотра результатов обучения в производственной среде специалистами по Data Science, поскольку они обладают знаниями для выявления и устранения проблем, связанных с машинным обучением. Поэтому если необходимо, чтобы модель была обучена на всем производственном наборе данных, можно использовать гибридный подход, развернув код в промежуточной среде, обучив модель, а затем развернув ее в рабочей среде. Такой подход снижает затраты на обучение в производственной среде, но увеличивает эксплуатационные расходы на этапе подготовки. Альтернативой является подход с развертыванием моделей, который мы разберем далее.
Развертывание ML-модели
В этом шаблоне развертывания артефакт модели создается обучающим кодом в среде разработки, затем тестируется в промежуточной среде перед развертыванием в производственной. Этот вариант подходит, когда обучение ML-модели очень дорого или трудно воспроизводимо, вся работа выполняется в единой рабочей области Databricks и нет внешних репозиториев или процессов непрерывной интеграции и поставки (CI/CD). Такой подход проще для специалистов по данным и требует однократного обучения модели. Что особенно важно при высокой стоимости этого процесса.
Однако, если производственные данные недоступны из среды разработки, например, по соображениям безопасности, эта архитектура может оказаться нежизнеспособной. Кроме того, автоматическое переобучение модели в этом шаблоне затруднительно: можно автоматизировать переобучение в среде разработки, но команда, ответственная за развертывание модели в производственной среде, может не принять полученную ML-модель как готовую к эксплуатации. Наконец, этот шаблон требует дополнительных усилий, поскольку вспомогательный код, такой как конвейеры, используемые для разработки фичей, логических выводов и мониторинга, необходимо развертывать в рабочей среде отдельно.
Таким образом, в шаблоне развертывания моделей окончательное модульное и интеграционное тестирование выполняется в среде разработки. А в паттерне развертывания кода модульные тесты и интеграционные тесты выполняются в средах разработки, тогда как окончательное модульное и интеграционное тестирование выполняется в промежуточной среде.
Впрочем, следует еще раз подчеркнуть, что выбор окончательного варианта развертывания зависит от нескольких условий:
- сценарий использования системы Machine Learning, включая частоту обновления модели, данных и кода;
- компетенции команды, в т.ч. специалистов по Data Science и MLOps-инженеров;
- строгость правил обеспечения информационной безопасности, действующих в компании;
- использование внешних сервисов и репозиториев за пределами единой платформы Databricks Lakehouse.
Освойте лучшие практики и инструменты MLOps для применения в системах аналитики больших данных и машинного обучения на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники