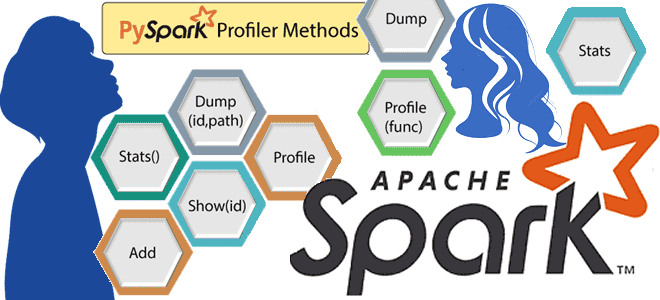
Что такое профилирование кода, зачем это нужно и как работают Python-профилировщики в приложениях Apache Spark. Пример профилирования PySpark-программы. Что такое профилирование и почему это важно для PySpark-приложений Будучи написанном на java и Scala, Apache Spark также поддерживает декларативные API-интерфейсы Python, которые позволяют разработчику писать и запускать код на этом более...

Что такое словарь в ClickHouse, какие бывают словари, как их создать и каким командами к ним обращаться. Пара примеров со словарями в самой популярной колоночной аналитической СУБД. Что такое словарь в ClickHouse Как колоночная база данных, ClickHouse предназначена для аналитической обработки огромных объемов данных в реальном времени. Аналитические сценарии предполагают...
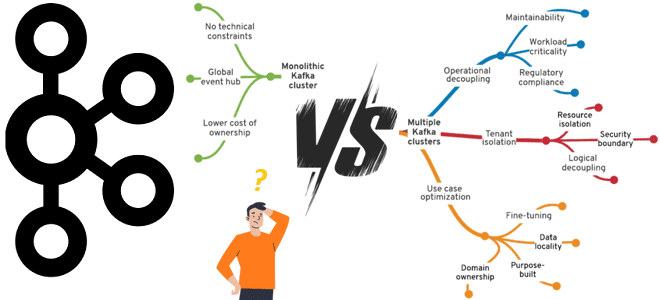
Что выбрать для эффективного управления корпоративным кластером Apache Kafka, от чего зависит уровень централизации и какие факторы влияют на принятие решений. Стратегии управления корпоративным кластером Apache Kafka Типовой вариант использования Apache Kafka – это потоковая интеграция корпоративных приложений. Чтобы эффективно использовать эту платформу потоковой передачи событий в масштабах предприятия, необходимо...
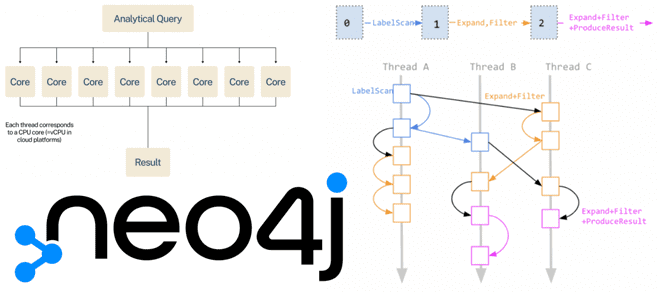
Как разработчики Neo4j улучшают производительность этой графовой СУБД с помощью нового блочного формата хранения данных и параллельной среды выполнения Cypher-запросов. Блочный формат хранения данных Наиболее важной новинкой Neo4j в релизе 5.14, вышедшего в конце ноября 2023 года, стал новый формат хранения данных – блочный, который размещает данные на диске в...
Как выполнить миграцию данных: лучшие практики и рекомендации на примере Greenplum. Особенности и принципы работы утилит gpbackup, gprestore и gpcopy. Миграция данных из Greenplum на 7 с утилитами gpbackup и gprestore Независимо от причины миграции данных из прикладной системы или корпоративного хранилища данных на новую технологию, эта процедура всегда остается...
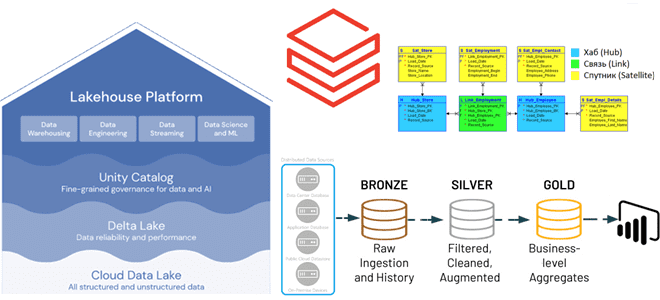
Преимущества методологии Data Vault для проектирования архитектуры данных Lakehouse, а также лучшие практики ее использования с максимальной эффективностью для корпоративного хранилища. Принципы методологии Data Vault и их применение к проектированию DWH Существует множество различных методологий проектирования данных, которые можно использовать при разработке аналитической системы, например, модели звезды и снежинки, подходы...
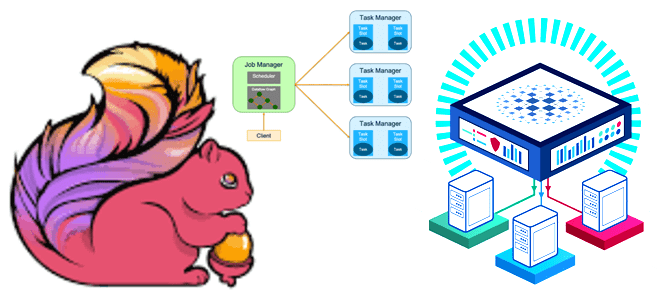
Как работает Flink-приложение, из каких компонентов состоит распределенный кластер и как сделать его отказоустойчивым. Архитектура и принципы работы высокой доступности Apache Flink. Архитектура Flink-приложения: ключевые компоненты и связь между ними Перед тем, как погружаться в средства обеспечения высокой доступности Flink-приложения, вспомним базовые принципы его работы. Сам по себе Apache Flink...
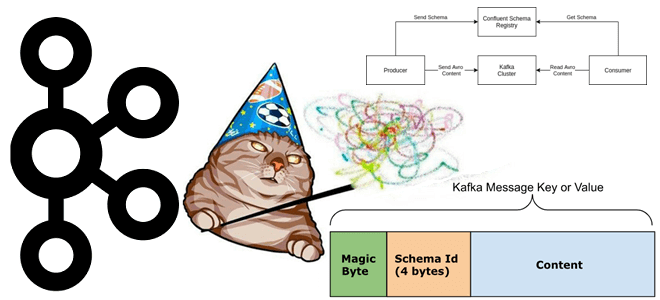
Что такое неизвестный магический байт, почему возникает эта ошибка и как предупредить такое исключение сериализации при работе с Kafka Streams, клиентами Apache Kafka и реестром схем. Что такое магический байт в сообщении Чтобы корректно обработать на стороне потребителя сообщение, считанное из Kafka, необходимо знать его формат, поскольку данные, публикуемые приложением-продюсером...

Ранее мы уже писали об уязвимостях Apache NiFi, выявленных и устраненных в 1-ой половине 2023 года. Сегодня рассмотрим еще 3 ошибки, которые были обнаружены и исправлены в последние 6 месяцев уже уходящего года. Последние 3 уязвимости Apache NiFi во второй половине 2023 года Помимо ранее рассмотренных уязвимостей, в 2023 году...
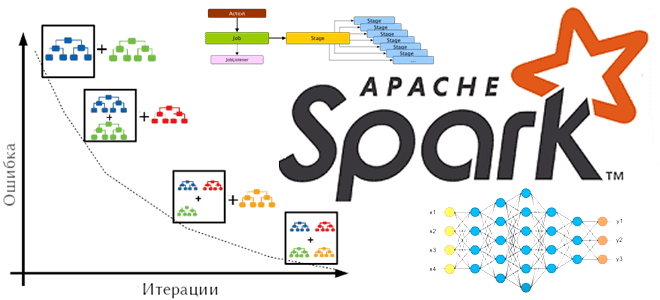
Что такое барьерный режим выполнения в Apache Spark, чем он отличается от вычислительной модели MapReduce, как связан с глубоким машинным обучением и где используется на практике. Что такое барьерный режим выполнения в Apache Spark Способ выполнения заданий Spark определяется режимом выполнения приложения, заданным на уровне фреймворка. На платформе. Именно от...