 1123
1123 
Содержание
Как работает Flink-приложение, из каких компонентов состоит распределенный кластер и как сделать его отказоустойчивым. Архитектура и принципы работы высокой доступности Apache Flink.
Архитектура Flink-приложения: ключевые компоненты и связь между ними
Перед тем, как погружаться в средства обеспечения высокой доступности Flink-приложения, вспомним базовые принципы его работы. Сам по себе Apache Flink представляет собой фреймворк для создания распределенных потоковых приложений. Он интегрируется со всеми распространенными менеджерами ресурсов кластера, такими как Hadoop YARN и Kubernetes, но также может использоваться в качестве автономного кластера или даже как библиотека.
Среда выполнения фреймворка состоит из двух типов процессов: диспетчера заданий JobManager и одного или нескольких диспетчеров задач TaskManager. Эти процессы можно запускать разными способами: непосредственно на машинах в виде автономного кластера, в контейнерах или под управлением ресурсных фреймворков, таких как Hadoop YARN. Диспетчеры задач подключаются к JobManager, объявляя себя доступными и получают задачу.
Клиент не является частью среды выполнения Flink-программы, а используется для подготовки и отправки потока данных в диспетчер заданий. После этого клиент может отключиться или оставаться на связи для получения отчетов о ходе работы. Клиент запускается как часть Java/Scala-программы, запускающей среду выполнения в CLI-процессе через команду
./bin/flink run ....
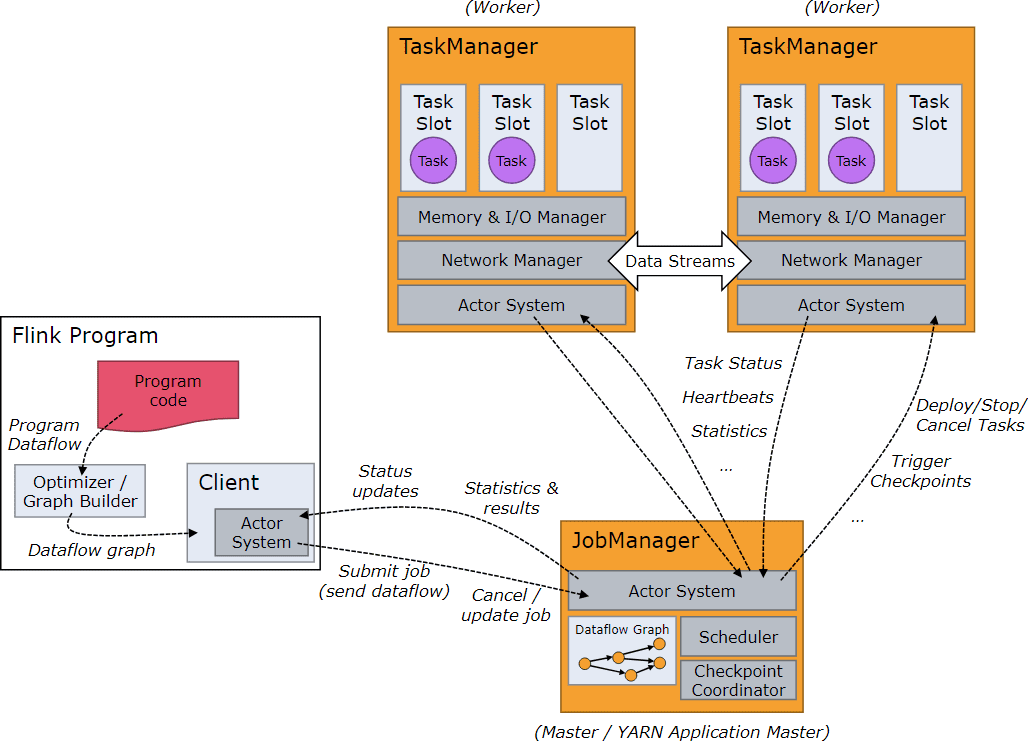
Задание Flink представляет собой логический граф (граф потока данных), который создается и отправляется в кластер путем вызова метода execute() в приложении. После преобразования этого логического графа в физический, задание трансформируется в набор задач — базовых единиц работы, которая выполняется средой выполнения Flink. Задачи инкапсулируют только один параллельный экземпляр оператора или цепочки операторов из двух или более последовательных операторов без перераспределения данных между ними. Операторы внутри одной цепочки пересылают записи друг другу напрямую без сериализации и передачи по сети.
Диспетчер заданий отвечает за координацию распределенного выполнения приложений: решает, когда планировать следующую задачу или набор задач, реагирует на завершенные задачи или сбои выполнения, координирует контрольные точки и координирует восстановление в случае сбоев. Диспетчер заданий состоит из трех различных компонентов:
- Менеджер ресурсов ResourceManager отвечает за выделение/распределение и предоставление ресурсов в кластере Flink. Он управляет слотами задач, которые являются единицей планирования ресурсов в кластере Flink. Flink реализует несколько менеджеров ресурсов для разных сред и провайдеров, таких как YARN, Kubernetes и автономные развертывания. В автономной настройке ResourceManager может только распределять слоты доступных диспетчеров задач, но не может запускать новые диспетчеры задач самостоятельно.
- Диспетчер предоставляет REST-интерфейс для отправки приложений Flink на выполнение и запускает новый мастер заданий JobMaster для каждого отправленного задания, а также запускает веб-интерфейс Flink для предоставления информации о выполнении заданий.
- Мастер заданий JobMaster отвечает за управление выполнение одного графа заданий JobGraph. В кластере Flink могут одновременно выполняться несколько заданий, каждое из которых имеет свой собственный мастер заданий.
Приложение Flink — это пользовательская Java-программа, которая создает одно или несколько заданий, используя метод main(). Выполнение этих заданий может происходить в локальной (LocalEnvironment) или при удаленной JVM-среде удаленной в кластере с несколькими машинами (RemoteEnvironment). Для каждой программы ExecutionEnvironment предусмотрены методы управления выполнением заданий, например, установка параллелизма, и взаимодействия с внешними программами и пользователями.
Задания Flink-приложения могут быть отправлены либо в различные кластера:
- кластер сеансов, который долго работает и может принимать несколько отправок заданий. Даже после завершения всех заданий кластер и диспетчер заданий будут работать до ручной остановки сеанса. Время работу кластера сеансов Flink не привязано к сроку существования какого-либо задания Flink. Слоты диспетчера задач выделяются менеджером ресурсов при отправке задания и освобождаются после завершения задания. Поскольку все задания используют один и тот же кластер, существует некоторая конкуренция за ресурсы кластера, например, за пропускную способность сети на этапе отправки задания. Также при сбое одного диспетчера задач все задания, задачи которых выполняются в этом диспетчере задач, завершатся ошибкой. Аналогично, если в JobManager произойдет какая-то фатальная ошибка, это повлияет на все задания, выполняемые в кластере. Этот режим запуска подходит для сценариев с интерактивным анализом коротких запросов, где время выполнения заданий очень короткое, а большое время запуска может отрицательно повлиять на сквозное взаимодействие с пользователем
- выделенный кластер заданий – режим, который считается устаревшим с версии 1.15. В этом режиме доступный диспетчер кластера, например, YARN, используется для развертывания кластера для каждого отправленного задания, а сам кластер доступен только для этого задания. Клиент сначала запрашивает ресурсы у менеджера кластера для запуска диспетчера заданий и отправляет задание диспетчеру, работающему внутри этого процесса. Затем диспетчеры задач в отложено выделяются в зависимости от требований к ресурсам задания. После завершения задания кластер заданий Flink отключается. Сбой диспетчера заданий влияет только на одно задание, выполняющееся в этом кластере заданий Flink. Этот режим подходит для крупных заданий, которые выполняются в течение длительного времени, имеют высокие требования к стабильности и не чувствительны к длительному времени запуска.
- кластер приложений – выделенный кластер, который выполняет задания только из одного приложения. Метод main() выполняется в кластере, а не на клиенте. Отправка задания представляет собой одноэтапный процесс: не нужно сначала запускать кластер, а затем отправлять задание в существующий сеанс кластера. Достаточно упаковать логику и зависимости приложения в исполняемый JAR-файл задания, а точка входа в кластер (ApplicationClusterEntryPoint) отвечает за вызов main() метода для извлечения графа заданий. Так можно развернуть Flink-приложение как любое другое приложение в Kubernetes. Время жизни кластера приложений привязано к времени жизни самого приложения. В кластере приложений ResourceManager и Dispatcher привязаны к одному приложению Flink, что обеспечивает лучшее разделение задач, чем кластер сеансов.
Подробнее про режимы развертывания Flink-приложения мы писали здесь. Разобравшись с ключевыми компонентами архитектуры кластера Flink, далее рассмотрим, как обеспечить его высокую доступность.
Высокая доступность Flink-приложения
Согласно вышерассмотренным принципам архитектуры Flink-приложения, при его выполнении всегда существует хотя бы один диспетчер заданий. Для обеспечения высокой доступности может быть несколько JobManager, один из которых всегда является ведущим, а остальные — резервными. Высокая доступность означает способность процесса диспетчера заданий восстанавливаться после сбоев. JobManager обеспечивает согласованность во время восстановления между диспетчерами задач.
Чтобы обеспечить высокую доступность необходимо всегда иметь один ведущий диспетчер заданий и несколько резервных, которые заместят ведущий в случае его сбоя. Это гарантирует отсутствие единой точки сбоя и безотказную работу программ.
Чтобы сам JobManager мог последовательно восстанавливаться, внешний сервис должен хранить минимальный объем метаданных восстановления, например, идентификатор последней зафиксированной контрольной точки, а также помогать выбирать и фиксировать, какой именно диспетчер заданий является лидером в кластере. В качестве такого внешнего (по отношению к Flink) сервису синхронизации метаданных используется Apache Zookeeper или Kubernetes.
Flink использует ZooKeeper для распределенной координации между всеми запущенными экземплярами диспетчера заданий. Apache ZooKeeper обеспечивает высоконадежную распределенную координацию посредством выборов лидера и быстрое согласованное хранилище состояний. ZooKeeper можно использовать при каждом развертывании кластера Flink с работающим кворумом экземпляров ZooKeeper.
Использование Kubernetes возможно только при развертывании в Kubernetes, т.е. при использовании автономного Flink-кластера в Kubernetes или встроенной интеграции с этой платформу управления контейнерами.
Чтобы восстановить отправленные задания, Flink сохраняет метаданные и артефакты заданий. Для обеспечения высокой доступности эти данные будут храниться в файловой системе до тех пор, пока соответствующее задание не будет выполнено успешно, не будет отменено или не завершится окончательным сбоем. Как только это произойдет, все данные высокой доступности, включая метаданные, хранящиеся в службах высокой доступности, будут удалены. Читайте в нашей новой статье, как облегчить отладку заданий Flink с помощью обогатителей сбоев.
Узнайте больше про использование Apache Flink для потоковой обработки событий в распределенных приложениях аналитики больших данных и машинного обучения на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

