 989
989 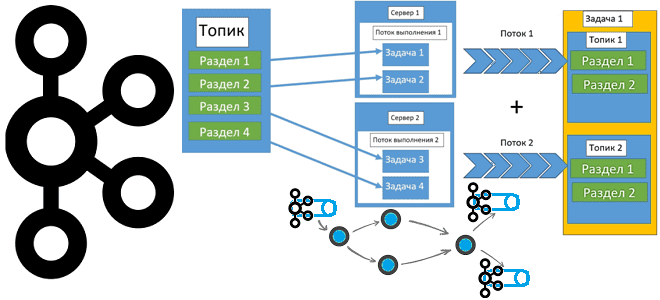
Содержание
Почему нельзя просто взять и соединить потоки Kafka Streams с разным числом разделов, и как это все-таки сделать без изменения конфигурации топика.
Почему нельзя просто взять и соединить потоки Kafka Streams с разным числом разделов
Kafka Streams – это клиентская Java-библиотека для разработки потоковых приложений, которые работают с данными, хранящимися в топиках Apache Kafka. Потоковое приложение реализует логику обработки данных через одну или несколько топологий процессоров, представляющих собой направленные графы из обработчиков (процессоров), соединенных потоками. Потоковый процессор – это этап обработки для преобразования данных в потоках путем однократного приема входной записи и передачи обратно в топик Kafka или внешнюю систему.
Каждый потоковый раздел представляет собой полностью упорядоченную последовательность записей и сопоставляется с разделом топика Kafka. Запись в потоке сопоставляется с сообщением в этом топике. Ключи записей данных определяют распределение данных по разделам в Kafka и в Kafka Streams. Масштабирование и параллельная обработка данных достигается за счет разделения на несколько задач. Kafka Streams создает фиксированное количество задач на основе разделов входного потока, фиксировано назначая каждой задаче список разделов из входных потоков (топиков Kafka). Каждая задача – это фиксированная единица параллелизма в приложении. Задачи могут создавать экземпляры своей собственной топологии процессора на основе назначенных разделов, поддерживая буфер для каждого из назначенных разделов и обрабатывая по одному сообщению. Все потоковые задачи автоматически обрабатываются независимо и параллельно.
На практике потоки Kafka Streams, как и топики Kafka, обычно содержат данные с разным бизнес-контекстом. Например, данные о клиентских заказах интернет-магазина и данные об изменении товарных запасов. Если надо обрабатывать эти потоки совместно, важно убедиться, что количество разделов в них совпадает. Это совпадение частично проверяется самой библиотекой Kafka Streams, которая выдает ошибку, если количество разделов в объединяемых топиках отличается.
Соединения потоков основаны на ключах записей, чтобы записи с одним и тем же столбцом соединения размещались в одной потоковой задаче. Для этого должны соблюдаться 3 условия:
- входные записи в каждом потоке или таблице для объединения должны иметь одинаковую стратегию назначения ключа. Это означает, что тип ключей, по которым выполняется соединение, должен быть одинаковым, например, целочисленный идентификатор INT order_id и INT product Также очень важно, чтобы метод сериализации ключей был одинаковым. Иначе базовые байты не будут совпадать.
- исходные топики должны иметь одинаковое количество разделов. Если это не соблюдается, то из-за последовательного назначения ключей в каждом разделе, нет никакой гарантии, что события в разделе 1 первого топика будут иметь тот же ключ, что и события в том же разделе второго топика. Но когда количество разделов одинаково, хэш-функция от ключа партиционирования гарантирует, что сообщения с одним и тем же ключом будут находиться в одних и тех же разделах в обоих соединяемых топиках. Поэтому соединение потоков будет успешным.
- обе стороны соединения должны иметь одинаковую стратегию разделения с точки метода хеширования, который использует продюсер. Иначе не гарантируется соответствие событий в каждом разделе топика. Это особенно важно, когда приложения-продюсеры написаны на разных языках. В частности, здесь мы рассказывали, что клиенты на основе Java используют алгоритм хэширования murmur2, а приложения, написанные на Python, Go, .NET, C# с библиотекой librdkafka по умолчанию используют по умолчанию другой алгоритм хэширования — CRC32 (32-битная циклическая проверка контрольной суммы, Cyclic Redundancy Check). Разные функции хеширования дают различные результаты. Поэтому сообщения с одним и тем же ключом партиционирования, созданные Java-продюсером могут быть направлены в другие разделы, чем те же самые сообщения, отправленные приложением, написанным на другом языке. В таком случае придется переопределять алгоритм хеширования в клиенте, отличном от Java или писать свой собственный разделитель, чтобы переопределить алгоритм в Java-продюсере.
Быстро проверить, что топики имеют одинаковое количество разделов, можно с помощью утилиты kafka-topics с флагом describe:
kafka-topics --describe
И как все-таки это сделать, если очень хочется
Если выяснилось, что соединяемые топики имеют разное количество разделов, может потребоваться изменить разделение одного из топиков, или даже обоих. Это приведет к потере упорядоченности сообщений, поскольку Kafka гарантирует порядок событий только внутри раздела. Соответственно, подобное изменение структуры топика может повлиять на логику обработки сообщений в приложении-потребителе.
Обойти это можно, используя метод KStream.repartition() в Kafka Streams, который позволяет перераспределить разделение потока без изменения количества разделов в исходном топике Kafka. Применение этого метода позволит соединять потоки, даже если исходные топики Kafka имеют разное число разделов.
Этот метод возвращает KStream, который содержит те же самые перераспределенные записи, что и исходный поток. Под капотом этого метода происходит создание внутреннего топика, который предназначен для использования только текущим экземпляром Kafka Streams. Этот топик будет называться ${applicationId}-<name>-repartition, где applicationId — это указанный пользователем параметр конфигурации потока APPLICATION_ID_CONFIG, name — это внутреннее название, а repartition — фиксированный суффикс, указывающий на факт изменения числа разделов. Время хранения данных в этом топике определяется временем жизни текущего экземпляра Kafka Streams, который его использует.
Узнайте больше про администрирование и эксплуатацию Apache Kafka для потоковой аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Apache Kafka для инженеров данных
- Администрирование кластера Kafka
- Администрирование Arenadata Streaming Kafka
Источники

