 816
816 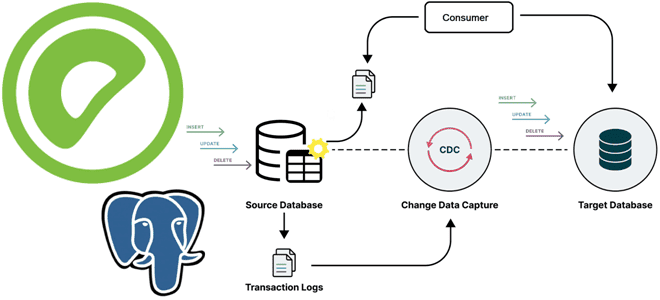
Методы отслеживания изменений в реляционных базах данных: столбцы аудиты, триггеры DDL-событий и WAL-журналы. Плюсы и минусы этих подходов, а также примеры реализации в Greenplum и PostgreSQL.
3 подхода к извлечению данных из реляционных баз
Извлечение данных из реляционных баз является наиболее распространенной операцией в ETL-процессах. Поэтому при проектировании конвейеров обработки данных дата-инженеру надо выбрать наилучший подход к построению ETL-конвейеров для загрузки данных в корпоративное хранилище или озеро. Выбор подходящего метода зависит от следующих факторов:
- тип набора данных, т.е. чем являются извлекаемые данные — фактом, измерением, неизменяемым логом;
- размер извлекаемых данных – количество таблиц, число строк и столбцов в каждой таблице и их объем;
- доступность метаданных, включая специальные столбцы, такие как идентификаторы, отметка времени создания и изменения записи;
- частота изменения, т.е. вставки и обновления данных;
- требования бизнеса к задержке обработки и свежести данных;
- доступность и стоимость хранилищ, а также вычислительных ресурсов;
- доступность ресурсов ядра исходной базы данных.
Разумеется, проще всего извлекать неизменяемые данные, предназначенные только для вставки (факты в терминологии DWH), такие как записи транзакций, события реального мира и пр. Логика извлечения таких данных проще, поскольку не нужно беспокоиться об обновлениях и удалениях, необходимо лишь обеспечить обнаружение новых вставок. Примеры таких паттернов извлечения данных из реляционных баз мы разбираем в новой статье. Работа с изменяемыми данными, (измерениями в терминологии DWH) сложнее, поскольку нужно обнаруживать изменение записей, включая их обновления и удаления. Для такого обнаружения измененных данных (CDC, Change Data Capture) в реляционных базах есть следующие подходы:
- CDC с помощью запросов к специальным столбцам, которые маркируют изменение. Эти столбцы называют столбцами аудита. Ими являются, например, инкрементные идентификаторы, поля create_dateи modified_timestamp. Обратившись к таким столбцам с помощью простого SQL-запроса, можно сразу определить изменения данных. Они обычно заполняются автоматически внешними системами или триггерами базы данных. Если столбцы обновляются внешней системой, а не триггерами базы данных, есть риск, что записи будут изменены вручную разработчиками или администраторами СУБД без обновления столбцов аудита. Этот метод довольно прост с точки зрения технической реализации, но он позволяет работать только с операциями вставки и обновления, не фиксируя физические удаления данных. Также могут не зафиксироваться изменения, когда запись обновляется вручную на уровне базы данных без обновления отметок времени. А использование триггеров увеличивает нагрузку на ядро СУБД и снижает производительность.
- использование триггеров в базе данных и запись изменений в таблицу или лог-файл. Если столбцы аудита недоступны, можно реализовать CDC на серверной части базы данных, захватывая вставки и обновления записей с помощью триггеров для набора таблиц. Затем эти события надо записать в таблицу или файл журнала изменений. Таким образом можно зафиксировать все изменения, включая удаление данных, а не только вставку и обновления. Однако, триггеры придется определить для всех таблиц, изменения в которых надо отслеживать, что приведет к дополнительным затратам на обработку и хранение данных. Также запросы к таблице журнала изменений увеличивают нагрузку на БД.
- регистрация изменений данных на основе журналов самой СУБД или сторонних библиотек и CDC-инструментов. Такой метод обычно используется в шаблонах рабочих процессов, управляемых событиями и потоковой передаче. Он фиксирует все изменения: вставки, обновления и удаления данных, не создавая дополнительной нагрузки на ядро СУБД. Однако, не все СУБД поддерживают CDC на основе журналов. Поэтому на практике приходится часто использовать дополнительные сторонние CDC-инструменты, такие как Debezium и брокер сообщений, например, Apache Kafka. В свою очередь, добавление таких дополнительных элементов увеличивает расходы на сопровождение и обслуживание всей системы обработки данных.
Как эти подходы реализуются в MPP-СУБД Greenplum, основанной на PostgreSQL, рассмотрим далее.
Реализация CDC в Greenplum и PostgreSQL
Поскольку Greenplum основана на PostgreSQL с механизмами массово-паралелльной загрузки данных, она использует многие механизмы этой объектно-реляционной СУБД. Однако, в особенностях реализации есть некоторые различия. В частности, в отличие от PostgreSQL, Greenplum не поддерживает пользовательские триггеры, а работает только с DDL-событиями. Подробнее об этом мы писали здесь. Впрочем, для захвата измененных данных триггеров на DDL-события (INSERT, UPDATE или DELETE) вполне достаточно.
При таком подходе к реализации CDC захваченные события изменения данных сохраняются только внутри самой базы. Если надо синхронизировать события изменений с другими системами данных, например, корпоративным хранилищем, придется периодически запрашивать таблицу Greenplum, содержащую события изменений, что повышает сложность реализации CDC-конвейера.
Начиная с версии 9.4, PostgreSQL предлагает логическую репликацию для эффективной и безопасной репликации данных между разными экземплярами базы данных. Технически это реализуется с помощью журнала упреждающей записи (WAL, Write Ahead Log) на диске, в котором хранятся все события изменения данных, например, INSERT, UPDATE и DELETE. Greenplum и PostgreSQL используют модель подписки с издателями и подписчиками для реализации логической репликации. Для реализации CDC можно использовать нужную базу данных в качестве издателя и подписаться на ее журнал. Чтобы включить логическую репликацию, надо внести изменения в файл конфигурации postgresql.conf:
wal_level = logical
Хотя журналы транзакций обычно используются для резервного копирования и восстановления данных, их также можно применять для репликации изменений. WAL-журнал – это последовательный лог всех изменений, внесенных в базу данных. Каждый раз, когда транзакция изменяет базу данных, изменения сперва записываются в WAL, а затем применяются к реальным файлам данных. Такое журналирование с упреждающей записью обеспечивает надежность и аварийное восстановление транзакций базы данных. Однако, в своем собственном формате этот лог не оптимизирован для внешних процессов, и его сложно использовать. Логическое декодирование в PostgreSQL и Greenplum декодирует содержимое WAL в последовательный и простой для понимания формат, например, в поток кортежей или операторов SQL. При этом используются слоты репликации, которые представляют собой поток упорядоченных изменений, обычно используемых для воспроизведения событий между клиентом и сервером для обычной репликации. Эти слоты репликации обеспечивают доставку изменений в том порядке, в котором они были применены к исходной базе данных. Порядок основан на внутреннем порядковом номере журнала (LSN), который является указателем на позицию в журнале WAL. Этот процесс устойчив к сбоям и использует контрольные точки для продвижения позиции.
При реализации CDC с использованием WAL очень важно, чтобы потребитель мог обрабатывать дубли из-за перезапуска между контрольными точками, поскольку СУБД возвращается к более ранней позиции LSN. Процесс декодирования, выполняемый методом логического декодирования, и последующий формат сообщений в слоте репликации можно контролировать с помощью плагина. Например, в PostgreSQL, начиная с версии 10, включен стандартный плагин логического декодирования pgoutput, который не требует установки дополнительных библиотек и используется для внутренней репликации.
Рассмотренные методы захвата измененных данных в Greenplum и PostgreSQL имеет пакетный характер. Для потоковой репликации изменений необходим брокер сообщений с высокой пропускной способностью, например, Apache Kafka. При этом часто используется Debezium — набор сервисов для отслеживания изменений в базе данных, который записывает все изменения на уровне строк в таблице базы данных как упорядоченный поток событий, отправляя их в другие системы, например, ту же Kafka. С помощью библиотеки коннекторов Debezium может создавать сообщения в формате, независимом от исходной СУБД, позволяя работать с различными потребителями событий независимо от их происхождения.
Kafka используется как система обмена сообщениями, которая может хранить CDC-события в течение длительного периода времени. Это снижает нагрузку на WAL-журнал Greenplum и PostgreSQL и позволяет избежать потенциальных проблем с ростом журнала упреждающей записи, поскольку его нельзя восстановить. Разработанный с использованием платформы Kafka Connect , Debezium отлично работает с Apache Kafka и подходит для реализации потокового сценария CDC. Практический пример, как это можно реализовать на serverless-платформе Upstash читайте в нашей новой статье.
Впрочем, Debezium с Apache Kafka не единственные инструменты для захвата измененных данных в режиме реального времени. Также подобные возможности предоставляет BryteFlow – low-code платформа репликации данных в реальном времени. BryteFlow использует автоматизированный CDC на основе журналов транзакций в реальном времени, позволяя перемещать около 1 000 000 строк всего за 30 секунд. Есть и другие аналоги, например, Hevo Data, Qlik Replication (ранее Attunity Replication), Talen CDC, Oracle GoldenGate, IBM InfoSphere и пр.
Узнайте больше про Greenplum и другие СУБД для хранения и аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники
- https://medium.com/@alirezasadeghi1/techniques-for-periodically-extracting-data-from-relational-databases-323d97cac326
- https://datacater.io/blog/2021-09-02/postgresql-cdc-complete-guide/
- https://bryteflow.com/postgres-cdc-6-easy-methods-capture-data-changes/
- https://clickhouse.com/blog/clickhouse-postgresql-change-data-capture-cdc-part-1
- https://hevodata.com/learn/7-best-cdc-tools/

