 1146
1146 
Содержание
Как организовать упрощенное и продвинутое управление зависимостями между разными ETL-конвейерами, когда нужна централизованная оркестрация рабочих процессов и чем хороша стандартизация активов данных, отчетов и вычислительных процедур. Лучшие практики проектирования конвейеров для дата-инженера.
Проектирование дата-конвейеров с минимальными зависимостями
Для многих компаний, выстроивших процессы обработки данных в виде конвейеров, актуальна проблема управления зависимостей между этими рабочими процессами. В типичной архитектуре хранилища данных или озера данных, использующей ELT/ETL-шаблоны, конвейеры приема планируются с использованием подходящих внутренних событий или времени. Нисходящие конвейеры затем будут использовать эти данные для обогащения, преобразования и агрегирования. Чтобы повысить эффективность эксплуатации этих конвейеров обработки данных, необходимо проектировать их с учетом взаимных зависимостей и лучших практик управления ими.
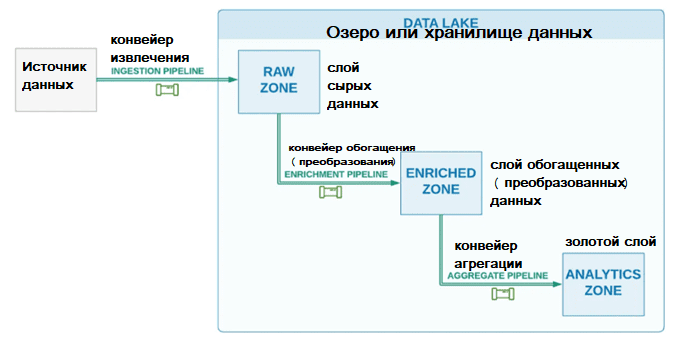
Одним из вариантов управления зависимостями является запуск каждого конвейера по расписанию, автономно, т.е. независимо от других. Например, если восходящий конвейер запускается раз в час и его выполнение занимает около 20 минут, следующий за ним, т.е. нисходящий конвейер можно запланировать также раз в 60 минут, но с получасовым смещением после предыдущего.
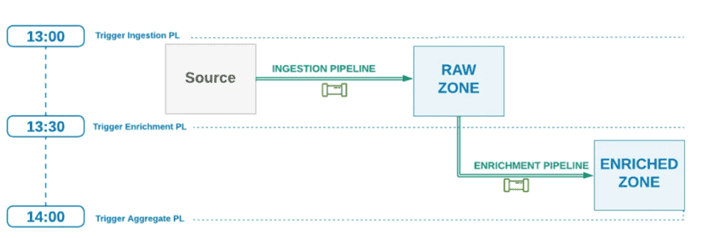
Такой автономный запуск по расписанию исключает сложные алгоритмы управления зависимостями, а также позволяет разделить ответственность за конвейер и наборы данных между разными командами дата-инженеров. Однако, когда конвейеры данных полностью независимы, и запуск восходящего конвейера завершился сбоем или его выполнение заняло больше времени, чем обычно, нисходящий конвейер будет выполняться с неполными данными или вообще без них. Придется отслеживать статус выполнения предыдущих заданий, чтобы повторить последующие. Из-за отсутствия автоматического отслеживания статусов и независимого запуска по расписанию повторные попытки обработки данных требуют ручного вмешательства.
Поэтому лучше выполнять нисходящие конвейеры после того, как восходящие завершились успешно. По сути, нижестоящие конвейеры будут запускаться по сигналу, который можно реализовать с помощью различных механизмов, от правила триггера в AirFlow до считывания события из топика Kafka, таблицы БД или файла. Такой подход задерживает запуск нижестоящих запланированных конвейеров, пока вышестоящие не подадут сигнал об успехе выполнения.
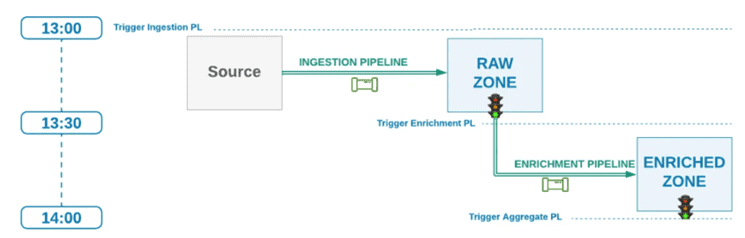
Преимуществами такого подхода, сочетающего запуск конвейера по расписанию с триггерным сигналом, является экономия вычислительных ресурсов. Это особенно важно при облачном развертывании с оплатой за каждый вызов. Поскольку нисходящий конвейер запускается только после успешного завершения восходящего, то при возникновении задержки и/или неверного выполнения, вычислительные ресурсы не будут расходоваться на работу с неполными или старыми данными. Кроме того, в таком подходе нет ограничений по временным окнам продолжительности выполнения и моментов запуска для разных конвейеров. А, благодаря минимальной зависимости, отвечать за разработку и сопровождение различных конвейеров могут по-прежнему отдельные команды дата-инженеров.
Однако, повторные попытки запуска восходящего конвейера, которые уже однажды успешно завершились, не координируются автоматически с нижестоящими конвейерами, поскольку те уже выполняются после получения зеленого сигнала. Поэтому требуется ручное вмешательство или создание автоматических триггеров на событие повторного запуска.
Продвинутое проектирование зависимостей
Если дополнить предыдущий метод единым оркестратором для централизованной координации потока работы, получим полноценный инструмент управления рабочими процессами. В качестве него может использоваться Apache AirFlow, Dagster, Luigi и другие подобные фреймворки, о чем мы писали здесь и здесь. Например, в Apache AirFlow есть сенсоры или датчики – специальный тип операторов, которые ожидают завершения вышестоящей задачи или целого DAG. Также можно настроить запуск, используя ExternalTaskSensor, который может обнаруживать и сигнализировать о завершении задачи из другого конвейера в DAG. Подробнее о работе этого датчика мы рассказывали в этом материале.
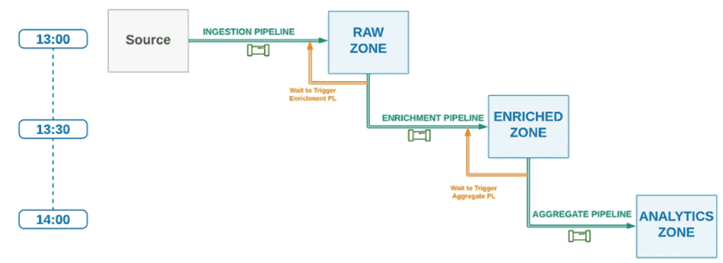
Плюсом этого подхода будет запуск нисходящего конвейера только после успешного завершения восходящего конвейера, что экономит вычислительные ресурсы, исключая обработку старых или неполных данных. Однако, зависимость между разными конвейерами становится сильнее: изменения в восходящих конвейерах влияют на нисходящий, который тоже обновиться. Такой подход лучше всего работает, когда конвейеры работают в одном и том же временном интервале. Например, если родительский конвейер запускается раз в час, то нижестоящий также должен работать ежечасно. Иначе координация зависимости между конвейерами усложняется и представляет собой реализацию следующего подхода, когда каждый восходящий конвейер вызывает или запускает нисходящие после своего успешного своего завершения.
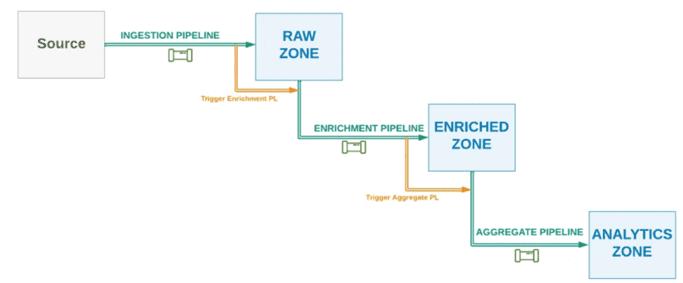
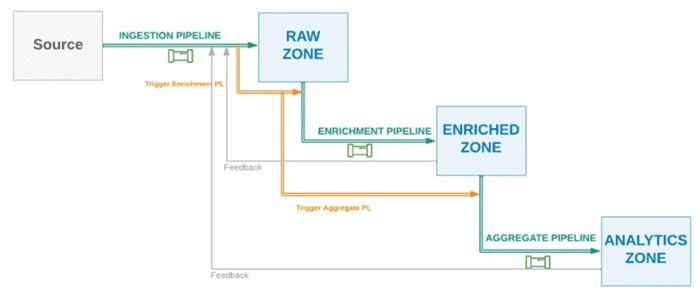
В этом случае нисходящий конвейер также запускается только после успешного завершения восходящего конвейера, что экономит вычислительные ресурсы и сокращает затраты на кластер. Сквозная оркестровка рабочего процесса данных особенно удобна, когда всеми конвейерами управляет одна команда дата-инженеров. Это важно, поскольку рассматриваемый способ предполагает, что восходящий конвейер должен знать о нисходящих, которые зависят от него, и как их вызывать. Зависимость между конвейерами увеличивается: при добавлении новых нижестоящих конвейеров необходимо обновить восходящий. Дополнительным ограничением становится привязка зависимых конвейеров к одному временному интервалу запуска. Кроме того, чтобы определить состояние последующих заданий, могут потребоваться циклы обратной связи. Поэтому дополнительно к последовательной оркестрации можно добавить петлю обратной связи, которая сигнализирует вышестоящему конвейеру о результатах выполнения нижестоящих.
Польза стандартизации для управления конвейерами обработки данных
В заключение отметим важность стандартизации подходов и инструментов при проектировании конвейеров обработки данных. Прежде всего, нужна стандартизация активов данных, которая предполагает их целенаправленную консолидацию и устранение избыточности, включая дублирование отчетов, процессов и хранилищ. Стандартизация активов данных снижает вероятность отказов, снижает разногласия и конкуренцию за вычислительные ресурсы и хранилище, а также сокращает затраты на их обслуживание.
Хотя отчеты тоже относятся к активам данных, про их стандартизацию следует сказать отдельно. Чтобы стандартизировать генерацию отчетов, необходимо, прежде всего, определить, какие данные и в каком виде нужны для принятия управленческих решений. Например, недельная сводка по продажам по каждому продукту в разных регионах. Чтобы сократить затраты на операции генерации этих отчетов, важно отслеживать их использования. Если какие-то отчеты перестали быть актуальными, их следует привести в соответствие с потребностями бизнес-пользователей или исключить вообще.
При отказе от какого-то отчета следует заблаговременно проинформировать потребителей данных об этом. Чтобы иметь возможность откатить изменение, вместо полного исключения операций формирования отчетов лучше подойдет их заморозка (архивация). Впрочем, архивации подлежат не только отчеты, но и источники этих данных: хранилища и базы данных. В большинстве случаев можно выделить «горячие данные», которые нужны в оперативном доступе в течение какого-то периода времени, например, активные заказы и выполненные за предыдущие 3 месяца. А данные прошлого квартала и более ранние можно перенести в архивное хранилище, разгрузив основную базу. Сокращение объема данных в оперативной базе ускоряет ее работу. Пример того, как это можно реализовать для PostgreSQL с Apache AirFlow я описывала здесь.
Наконец, поскольку перемещение устаревших данных в архивное хранилище, как и генерация отчетов, представляют собой конвейеры обработки данных, они тоже должны быть стандартизованы. Стандартизация рабочих процессов предполагает выявление зависимостей между ними, что было рассмотрено выше, а также эффективное проектирование их взаимодействия. При этом надо обратить особое внимание на конвейеры, которые чаще других терпят сбой, являются наиболее критичными для бизнеса, обновляются чаще других и потребляют больше ресурсов.
Больше полезных приемов по проектированию и реализации аналитических конвейеров обработки больших данных вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

