 104
104 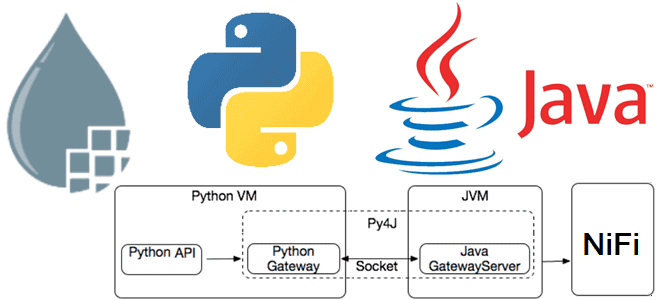
Содержание
Недавно мы писали про Nifi-Python-Api —клиентский SDK, поддерживающий Python для работы с Apache NiFi. Сегодня на примере разработки процессоров более подробно разберем принципы взаимодействия процессов Python с Java, на которой написан Apache NiFi.
Принципы работы Python-кода в Java-среде Apache NiFi
Поскольку Apache NiFi написан на Java, именно этот язык предпочтителен для создания расширений к этому фреймворку. Однако, писать код на Java – не самое простое занятие. Поэтому более легкий в освоении Python стал очень популярным. Поэтому многие Java-приложения допускают использование Python. Например, в Apache Spark, написанном на Java и Scala, есть PySpark, аналогично тому, как в Apache Flink есть PyFlink. Apache NiFi тоже дает возможность расширять фреймворк, позволяя разрабатывать собственные процессоры на Python. Но, чтобы Python-код заработал в Java-приложении, необходимо обеспечить взаимодействие процессов Java и Python. Например, приложение Java отвечает за хранение определения потока типа факта существования какого-либо процессора, его конфигурации и пр. Оно также отвечает за поддержание FlowFiles и их данных. Эта информация должна передаваться через сокет со стороны Java на сторону Python. Как только Python-процессор выполнит свою задачу и захочет направить данный FlowFile к некоторому отношению, эта информация также должна быть передана обратно на сторону Java.
Для обеспечения такого взаимодействия в Apache NiFi при запуске Python-процесса сервер запускается как на стороне Java, так и на стороне Python. Этот сервер прослушивает только локальные сетевые интерфейсы. Это означает, что извне, с другой машины, невозможно подключиться ни к серверу Java, ни к серверу Python: все подключения идут с локального хоста, обеспечивая безопасность.
Для того, чтобы сделать доступными Java-объекты для процессов Python и наоборот, в NiFi API есть прокси-сервера объектов. Каждый раз, когда объект Java должен быть доступен API Python, он становится доступным через прокси-объект. Это означает, что для доступа к объекту Java из Python нужно просто вызвать соответствующий метод на прокси-сервере Python. При вызове этого метода объект Python генерирует сообщение и отправляет его через сокет. Например, есть объект InputFlowFile с именем flowFile и нам нужен его атрибут filename. Получить его можно, вызвав метод getAttribute():
filename = flowFile.getAttribute('filename')
В Java для межпроцессного взаимодействия используется специальный класс — сокет. При вызове метода getAttribute() в его объект (локальный сокет) запишется соответствующее сообщение, что этот метод вызывается для объекта с таким-то идентификатором и со строковым аргументом filename. Процесс Java получает эту команду, вызывает указанный метод для объекта с заданным идентификатором и записывает обратно в сокет результат вызова этого метода. В результате сторона Python получает значение атрибута filename. Таким образом, любой вызов метода в объекте Java, должен быть сериализован, записан через сокет и десериализован, чтобы его можно было вызвать. Затем необходимо выполнить обратные действия: результат команды необходимо сериализовать, записать в сокет и десериализовать на стороне Python. При этом появляются накладные расходы на вызовы методов объектов Java. Поэтому использование Python в Java-фреймворках менее эффективно по сравнению с нативным языком.
Когда объект предоставляется в качестве аргумента процессору Python, доступ к этому объекту возможен на стороне Python только, если объект доступен на стороне Java. В свою очередь, Java не хранит все объекты постоянно, запуская очистку сразу после вызова метода. Поэтому если преобразование FlowFileTransform вызывается с объектом ProcessContext, этот объект доступен для использования ТОЛЬКО во время вызова метода. Как только вернется результат вызова, в т.ч. неуспешный, объект становится недоступным для использования. Поэтому объекты, предоставленные при вызове метода, не должны сохраняться для последующего использования, например, для присвоения значения self.processContext. Ссылка на объект, который больше не доступен, приведет к исключению библиотеки Py4J:
py4j.Py4JException: An exception was raised by the Python Proxy. Return Message: Traceback (most recent call last):
File "/Users/mpayne/devel/nifi/nifi-assembly/target/nifi-2.0.0-SNAPSHOT-bin/nifi-2.0.0-SNAPSHOT/python/framework/py4j/java_gateway.py", line 2466, in _call_proxy
return_value = getattr(self.pool[obj_id], method)(*params)
File "/Users/mpayne/devel/nifi/nifi-assembly/target/nifi-2.0.0-SNAPSHOT-bin/nifi-2.0.0-SNAPSHOT/./python/extensions/SetRecordField.py", line 22, in transform
<Your Line of Python Code>
File "/Users/mpayne/devel/nifi/nifi-assembly/target/nifi-2.0.0-SNAPSHOT-bin/nifi-2.0.0-SNAPSHOT/python/framework/py4j/java_gateway.py", line 1460, in __str__
return self.toString()
File "/Users/mpayne/devel/nifi/nifi-assembly/target/nifi-2.0.0-SNAPSHOT-bin/nifi-2.0.0-SNAPSHOT/python/framework/py4j/java_gateway.py", line 1322, in __call__
return_value = get_return_value(
File "/Users/mpayne/devel/nifi/nifi-assembly/target/nifi-2.0.0-SNAPSHOT-bin/nifi-2.0.0-SNAPSHOT/python/framework/py4j/protocol.py", line 330, in get_return_value
raise Py4JError(
py4j.protocol.Py4JError: An error occurred while calling o15380.toString. Trace:
py4j.Py4JException: Target Object ID does not exist for this gateway :o15380
at py4j.Gateway.invoke(Gateway.java:279)
at py4j.commands.AbstractCommand.invokeMethod(AbstractCommand.java:132)
at py4j.commands.CallCommand.execute(CallCommand.java:79)
at py4j.GatewayConnection.run(GatewayConnection.java:238)
at org.apache.nifi.py4j.server.NiFiGatewayConnection.run(NiFiGatewayConnection.java:91)
at java.lang.Thread.run(Thread.java:750)
Сообщение Идентификатор целевого объекта не существует для этого шлюза (Target Object ID does not exist for this gateway…) указывает на то, что код Python пытается получить доступ к объекту Java, который больше не доступен.
Напомним, именно библиотека Py4J играет роль моста между Python и Java, позволяя программам Python, работающим в интерпретаторе Python, динамически получать доступ к объектам Java в JVM. Методы вызываются так, будто объекты Java находятся в интерпретаторе Python, а к коллекциям Java можно получить доступ через стандартные методы коллекций Python. Py4J также работает в обратную сторону, позволяя Java-программам вызывать объекты Python. API Python в Apache Spark и Flink тоже используют эту библиотеку, о чем мы писали здесь и здесь.
Поскольку вызовы из Python в Java и наоборот обходятся намного дороже, чем использование нативного языка, пока API Python в Apache NiFi включает только пару классов процессоров: FlowFileTransform и RecordTransform. Как их реализовать на Python, подробно рассмотрим в следующий раз, а далее разберем, общие особенности разработки, отладки и развертывания.
Особенности разработки, отладки и развертывания Python-процессоров
Поскольку даже при использовании Python для разработки собственных процессоров, происходит взаимодействие с внутренними классами Java. Эти внутренние Java-классы должны быть определены на всех процессорах и включать элемент с именем implements, представляющим собой список интерфейсов Java, которые реализует класс. Благодаря этому протокол Py4J может понять, как взаимодействовать с этим объектом со стороны Java.
Класс ProcessorDetails сообщает NiFi о процессоре, чтобы можно было легко настроить процессор через пользовательский интерфейс NiFi. Кроме того, в нем содержится подробная информация о том, что необходимо для использования Процессора. Класс ProcessorDetails может описывать включать версию реализации процессора (version), описание в пользовательском интерфейсе (description), теги или ключевые слова (tags), зависимости PyPI (dependencies), представленные в виде строк как в команде установки пакетов через pip-менеджер (pip install). Каждый Процессор может иметь свой список требований/зависимостей. Они становятся доступными для процессора путем создания отдельной среды для каждой реализации процессора, а не для каждого экземпляра процессора на холсте рабочей области NiFi. Затем PyPI используется для установки этих зависимостей в этой среде. Также API Python в Apache NiFi требует, чтобы Python 3.9+ был доступен на компьютере, на котором размещен NiFi.
Процессоры на основе Python могут представлять собой один модуль или могут быть объединены в пакет Python. Способ указания сторонних зависимостей зависит от того, как упакован процессор:
- на уровне пакета — если в пакете Python определены один или несколько процессоров, надо определить файл requirements.txt, в котором объявляются все сторонние зависимости, необходимые для любого процессора в пакете.
- на уровне внутреннего класса ProcessorDetails — если процессор не является частью Python-пакета, его зависимости можно объявить с использованием dependencies. Это список строк, указывающих модули PyPI, от которых зависит процессор. Так можно объявить сторонние зависимости без необходимости объединения процессоров в пакет.
При запуске NiFi создаст отдельную виртуальную среду Python (venv) для каждой реализации процессора и будет использовать ее pip-менеджер для установки указанных зависимостей из PyPI. Поэтому зависимости одного процессора не доступны для другого, включая другую версию этого же процессора.
После разработки процессора его можно сделать доступным в NiFi, скопировав исходный код расширения Python в специальный каталог расширений. По умолчанию это $NIFI_HOME/python/extensions. Фактический каталог для поиска расширений можно настроить с помощью свойств конфигурационном файле nifi.properties с префиксом nifi.python.extensions.source.directory. Например, по умолчанию для nifi.python.extensions.source.directory.default установлено значение ./python/extensions. Однако можно добавить дополнительные пути, заменив defaul-свойства другими значениями. Любой .py-файл, найденный в каталоге, будет проанализирован и проверен, чтобы определить, является ли он действительным процессором NiFi. Чтобы его можно было найти, процессор должен иметь действительный родительский элемент (FlowFileTransform или RecordTransform) и внутренний класс Java с именем
implements = ['org.apache.nifi.python.processor.FlowFileTransform']
или
implements = ['org.apache.nifi.python.processor.RecordFileTransform']
Это позволит NiFi автоматически обнаружить процессор.
Если реализация процессора разбита на несколько модулей Python, они не будут доступны по умолчанию. Чтобы упаковать процессор вместе с его модулями, их надо добавить в каталог, который находится непосредственно в каталоге расширений. Поскольку NiFi позволяет развертывать несколько каталогов расширений, при разработке нового расширения полезно добавить каталог его разработки в качестве исходного каталога расширения NiFi. Так разработчик сможет писать процессоры с использованием своей IDE, а NiFi будет беспрепятственно воспринимать любые изменения сразу после запуска процессора.
С точки зрения разработчика очень удобно, что внести изменения в исходный код Python-процессора в NiFi повторно запустить его можно без перезагрузки. После обнаружения и загрузки процессора любые изменения в его исходном коде вступают в силу при каждом повторном запуске. Но если процессор не удалось успешно загрузить с первого раза, NiFi может не отслеживать его изменения. В таком случае придется перезапустить NiFi, чтобы обнаружить процессор и загрузить его снова.
В целях устранения неполадок можно удалить каталог среды, просто остановив и перезапустив NiFi. При этом последующий запуск NiFi займет значительно больше времени, поскольку ему придется получать все зависимости расширений из PyPI, а также расширять NAR-файлы всех расширений Java.
Узнайте больше про администрирование и использование Apache NiFi для построения эффективных ETL-конвейеров потоковой аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

