
11 марта 2020 года ВОЗ объявила о пандемии нового коронавируса (Covid-19), который в декабре 2019 был впервые обнаружен в китайском мегаполисе Ухань. С тех пор вирус стремительно распространяется по всей планете, вызывая острые респираторные заболевания. Сегодня мы расскажем, почему, несмотря на повсеместные карантины и обвал мировых рынков, все не все...
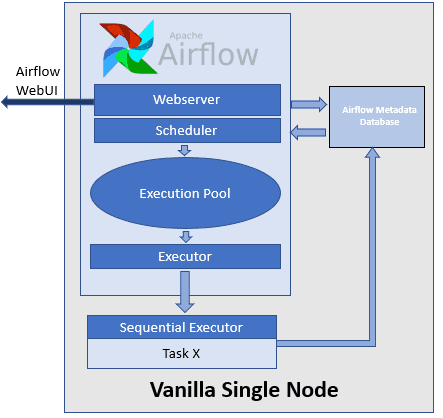
Недавно мы рассказывали про Airflow Kubernetes Executor, который позволяет выполнять задачи DAG-графа Эйрфлоу в среде Kubernetes, развертывая Docker-контейнер на отдельном пользовательском модуле (pod). Сегодня рассмотрим, какие еще есть исполнители задач в Apache Airflow, как они используются при автоматизации batch-процессов обработки больших данных и с какими проблемами можно столкнуться при их...
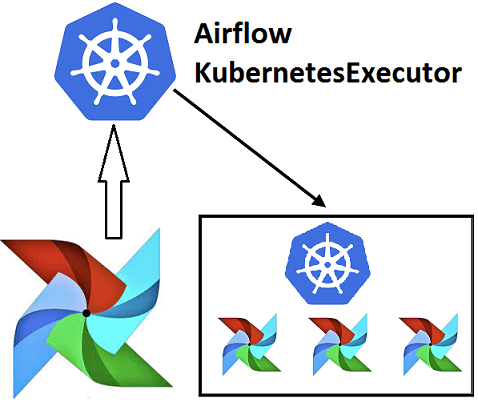
Эффективное обучение AirFlow, также как курсы по Spark, Hadoop, Kafka и другим технологиям больших данных (Big Data) также включают нюансы интеграции этого фреймворка с другими средами. Например, вчера мы рассматривали преимущества DevOps-подхода к разработке Data Flow на примере взаимосвязи Apache Airflow с Kubernetes посредством специальных операторов. Продолжая эту тему, сегодня...

Вчера мы рассказали, почему запускать Airflow на Kubernetes – это эффективно и выгодно для всех участников batch-процессов с большими данными (Big Data): разработчиков Data Flow, Data Scientist’ов, аналитиков и инженеров. Сегодня рассмотрим, что такое Airflow Kubernetes Operator и чем он отличается от подобной разработки компании Google. Как работает AirFlow Kubernetes...

ДАРИМ ПРИЗЫ ЗА ОТЗЫВЫ в 2020 году! Итоги акции "Напиши отзыв и получи шанс выиграть наушники Sony WH-1000XM3 !" В 2020 году «Школа Больших Данных» проводила для своих слушателей Розыгрыш призов: напиши и опубликуй отзыв по прослушанному курсу в Google или Yandex и участвуй в розыгрыше 5 Bluetooth наушников Sony WH-1000XM3....

Чтобы обучение Airflow было максимально приближенным к практике, сегодня мы поговорим про особенности реального внедрения этого фреймворка для разработки, планирования и мониторинга пакетных процессов обработки больших данных (Big Data) с учетом современного DevOps-подхода. Читайте в нашей статье, зачем вообще нужна связка Apache Эйрфлоу с Kubernetes и как это реализовать технически....

Продолжая говорить про обучение Airflow, сегодня мы рассмотрим ключевые преимущества и основные проблемы этой библиотеки для автоматизации часто повторяющихся batch-задач обработки больших данных (Big Data). Также мы собрали для вас пару полезных советов, как обойти некоторые ограничения Airflow на примере кейсов из Mail.ru, IVI и АльфаСтрахования. Чем хорош Apache AirFlow:...
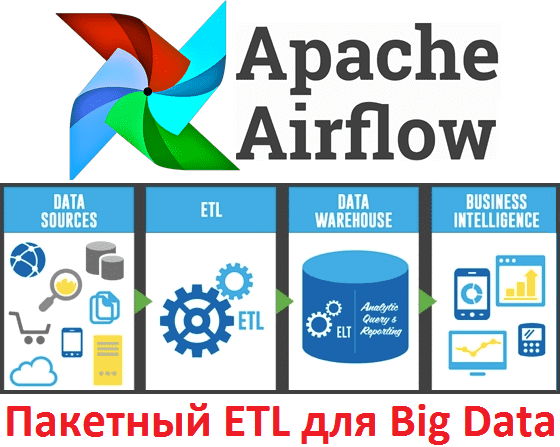
В этой статье мы поговорим про Apache AirFlow - эффективный инструмент для пакетных ETL-задач при работе с большими данными (Big Data): что это такое, как работает и чем полезен для инженера данных (Data Engineer). Также рассмотрим несколько практических примеров реального использования этой библиотеки для разработки, планирования и мониторинга batch-процессов. Что...

В честь Международного женского дня, 8 марта, мы собрали для вас 15 интересных кейсов о том, как большие данные (Big Data) и машинное обучение (Machine Learning, ML) используются в индустрии моды и красоты. Читайте в нашей сегодняшней статье как Zara, H&M, Burberry и другие fashion-гиганты внедряют умные примерочные, виртуальных стилистов,...
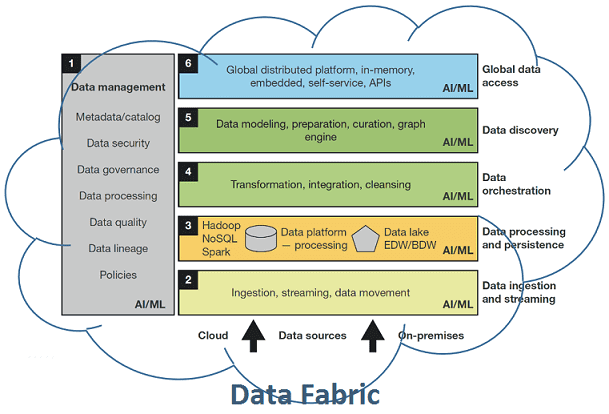
Сегодня мы рассмотрим, что такое Data Fabric, почему этот тренд в аналитике больших данных (Big Data) считается одним из самых перспективных в 2020 году, зачем нужна фабрика данных и как она устроена. Читайте в нашей статье, чем Data Fabric отличается от Data Factory, причем тут цифровизация, DataOps и конвейеры по...