
Продолжая тему прикладного использования искусственного интеллекта в различных бизнес-кейсах, сегодня мы расскажем о том, как устроены чат-боты, при чем здесь большие данные (Big Data) и машинное обучение (Machine Learning), системы распознавания речи и понимания естественного языка. Какие бывают чат-боты Все многообразие чат-ботов можно разделить на 2 большие категории [1]: работающие...

Выбирая курсы по Spark, Hadoop, Kafka и другим технологиям больших данных, легко запутаться во многочисленных предложениях от различных учебных центров и платформах онлайн-обучения. Сегодня мы расскажем, что должна включать программа курса по Big Data, чтобы результат обучения оправдал ваши ожидания и даже превзошел их. 4 главных свойства эффективного курса по...

Обычно курсы по Spark подробно рассказывают, чем хорош этот Big Data фреймворк для распределённой пакетной и потоковой обработки неструктурированных и слабоструктурированных данных. Но, чтобы обучение Apache Spark было максимально полезным, стоит знать и о недостатках этого многофункционального инструмента обработки больших данных. Сегодня мы рассмотрим некоторые проблемы, которые возникают при практическом...

Вчера мы рассказывали о рынке чат-ботов, голосовых помощников и виртуальных ассистентов на базе больших данных (Big Data) и машинного обучения (Machine Learning) . Напомним, на 2020 год они признаны аналитическим бюро Gartner одной из самых перспективных и наиболее эффективных технологий искусственного интеллекта. Сегодня поговорим о том, где именно они используются...

В этой статье мы представим для вас краткий обзор рынка чат-ботов и голосовых помощников. А также расскажем, где используются эти решения на базе технологий больших данных (Big Data) и машинного обучения (Machine Learning) и чего ждать от них в будущем. Чат-боты в России и за рубежом: обзор рынка Прежде всего,...
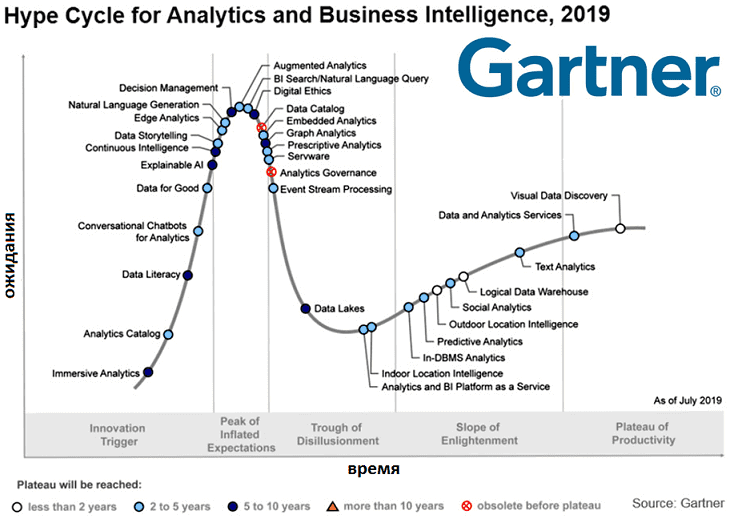
Сегодня мы поговорим, что такое Hype Cycle от самого известного аналитического агентства Gartner и как будут развиваться наиболее популярные сегодня ИТ-тренды в области больших данных (Big Data), управления данными (Data Management), машинного обучения (Machine Learning) и искусственного интеллекта (Artificial Intelligence). Что такое цикл зрелости технологий – Hype Cycle от Gartner...

Однажды мы уже рассматривали, зачем Apache Kafka, Hadoop, HBase и другие Big Data системы используют Zookeeper, почему он необходим в распределенных проектах и чем можно заменить его заменить. Сегодня поговорим о том, как работает этот популярный централизованный сервис для поддержки информации о конфигурации, именования, обеспечения синхронизации распределенных приложений и предоставления...

В продолжение темы, от чего большие данные, машинное обучение и другие методы искусственного интеллекта смогут защитить человечество, сегодня мы поговорим, почему эти технологии не заменят человека везде и полностью. В этой статье мы собрали доводы против абсолютной автоматизации принятия управленческих решений с помощью Big Data и Machine Learning. Когда Big...

К 23 февраля мы собрали для вас 5 кейсов, где выступать в роли защитника будет искусственный интеллект. Смертельные болезни, внешние угрозы, преступники, экологические проблемы и чрезмерные траты ресурсов – читайте в нашей сегодняшней статье, как цифровизация на базе больших данных (Big Data) и машинного обучения (Machine Learning, ML) защитит нас...

Чтобы повысить мотивацию студентов к обучению, преподаватели активно применяют различные подходы к организации образовательного процесса, в т.ч. используемые в HR. Сегодня мы покажем, как, по аналогии с управлением человеческими ресурсами, аналитика больших данных (Big Data) и методы машинного обучения (Machine Learning) помогают увеличить вовлеченность учеников и улучшить качество образования. От...