
Постоянно добавляя в наши курсы Apache Kafka для разработчиков интересные и практические примеры, сегодня мы разберем кейс тревел-площадки Trainline, которая агрегирует данные от 270 железнодорожных и автобусных компаний в 45 странах, предлагая выгодные билеты на европейские поезда и автобусы. Читайте далее, почему пакетный режим работы озера данных перестал отвечать требованиям билетного агрегатора, и как Apache Kafka помогла ускорить весь Big Data конвейер и перевести его в real-time.
Постановка задачи: зачем пакетному Data Lake переход в потоковый режим
Trainline – это независимая платформа для железнодорожных и автобусных путешествий, продающая билеты миллионам путешественников по всему миру, позволяющая легко находить, бронировать и управлять поездками в одном месте через веб-сайт и мобильное приложение. Одним из ключевых преимуществ, которые предоставляет компания своим клиентам, является оперативная доставка самых выгодных тревел-предложений из разных источников [1]. Поэтому быстрота агрегации данных и надежность их аналитической обработки – это критичные бизнес-требования для любого ИТ-решения Trainline.
Изначально в компании был пакетный подход к созданию озера данных (Data Lake), который предусматривал ежедневные обновления. Однако он не позволял в реальном времени получать от поставщиков исходные данные и предоставлять результаты их аналитической обработки клиентам. Поэтому дата-инженеры компании решили изменить конвейер данных, заменив большую часть пакетной обработки на потоковую с помощью Apache Kafka. Как именно это было сделано, мы рассмотрим далее.
Big Data pipeline в Trainline
Многие из Big Data сервисов Trainline развернуты в облаке Amazon Web Services (AWS), включая различные учетные записи AWS: production, staging, тестовые, а также отдельные аккаунты для обслуживания озера данных. Вся эта информация агрегирована в одной учетной записи, чтобы упростить процессы поддержки корпоративных политик доступа к данным и разрешения на их использование. Сам конвейер аналитической обработки данных выглядит следующим образом [1]:
- первым сервисом является HTTP API, называемый Vortex, для получения событий от других команд. Он проверяет событие JSON записывает его в AWS Kinesis Stream, если схема события соответствует заданному образцу. Для этого Vortex использует отдельную службу под названием Schema Registry, где хранятся допустимые схемы JSON. Для обновления реестра схем используется pull request в репозиторий Git;
- далее выполняется отправка данных в учетную запись через AWS Kinesis Streams, что позволяет легко настроить перекрестные разрешения для нескольких аккаунтов, чтобы читать потоки данных из разных учетных записей AWS.
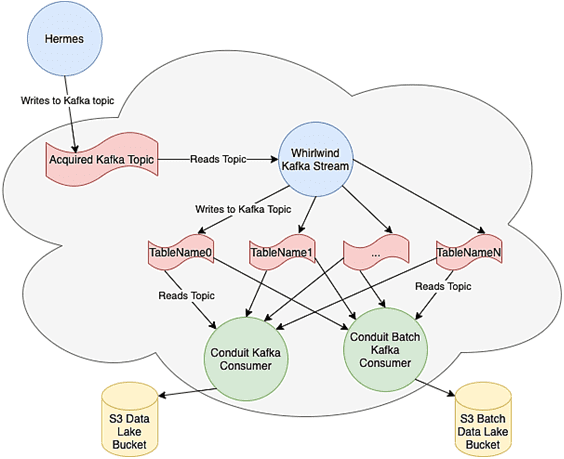
- затем служба маршрутизации Hermes считывает потоки данных из AWS Kinesis и отправляет данные в несколько настраиваемых пунктов назначения – SQS-очереди, чтобы группы потребителей могли получать данные в режиме реального времени, AWS S3, где все события записываются как необработанные сжатые файлы JSON, и Apache Kafka.
В пакетном режиме основная ответственность сервиса Hermes заключалась в записи данных в нужную корзину озера данных на AWS S3 с использованием ежедневных запусков Airflow. Однако, Apache Kafka позволяет сделать все данные доступными в режиме реального времени внутри Kafka-кластера, позволяя использовать их для других случаев, и также отправляет данные в Data Lake.
Потоковый конвейер с Apache Kafka
Чтобы сократить объем работы DevOps, дата-инженеры Trainline решили использовать Kafka MSK под управлением AWS, изменив pipeline следующим образом [1]:
- Hermes записывает все события в топик Kafka;
- Потоковое приложение Kafka Streams, называемое Whirlwind, читает из этого топика все входящие события и применяет к ним преобразования – простое сопоставление входящего события JSON для вывода плоской структуры или более сложное преобразование с настраиваемыми агрегатами для снижения затрат на вычисления в последующих заданиях или уменьшения размера выходного хранилища;
- служба реестра схем, которая хранит схемы Vortex JSON, также хранит файлы, которые описывают преобразование, выполненное в Whirlwind, и сопоставления ними и схемой JSON;
- результатом обработки Whirlwind является набор топиков Kafka, названных по аналогии с таблицами, ingested.private.TableName;
- потребитель Conduit считывает все эти топики по шаблону.
Логика приложения состоит в том, чтобы читать события из всех топиков, помещая их в файлы локально, пока его размер не превысит установленный предел в мегабайтах или время хранения на диске. При загрузке файл преобразуется из AVRO в Parquet и помещается в S3, а последнее обработанное смещение в этом разделе топика Kafka фиксируется. Благодаря согласованное шаблону имени файлов и фиксации смещений Kafka только после завершения загрузки, реализуется гарантия строго однократной доставки (exactly once). Таким образом, в случае ошибки потребитель начинает с ранее зафиксированного смещения, не теряя данные. А если некоторые файлы уже записаны в S3, они будут просто перезаписаны, чтобы исключить дублирование.
Таким образом, в главном озере данных есть разделы по времени события (event_time), которое является частью схемы JSON. Но, из-за отсутствия контроля за этим рабочим временем события, новые данные могут быть записаны в любой момент, например, когда кто-то отправляет исторические данные в Vortex. Проблема в том, что некоторые потребители данных заинтересованы только в свежих данных из Data Lake. Поэтому было решено создать локальную версию озера данных, которое хранит информацию в течение месяца и очищается политикой хранения AWS S3 с разделением по нужным временным периодам вместо event_time. Таким образом, благодаря временной метке записи (timestamp) Apache Kafka и гарантиях этой Big Data платформы потоковой обработки событий, можно сказать, что если данные записываются в час X из раздела P топика Kafka, то все данные за предыдущий час (X-1) уже находятся в озере.
Наконец, данные из озера доступны для конечных пользователей через AWS Athena, интерактивный сервис запросов, который позволяет просто анализировать данные в хранилище Amazon S3 с помощью стандартного SQL. Этот бессерверный инструмент интегрирован с каталогом данных AWS Glue, что дает возможность создать единый репозиторий метаданных для различных сервисов, сканировать источники данных для обнаружения схем и наполнять каталог новыми или измененными таблицами и определениями разделов, а также обеспечивать версионность схем [2].
Trainline использует краулеры Glue для обнаружения таблиц и обновления разделов, а Athena является конечным пунктом всего конвейера, предоставляя нужные данные конечным пользователям и приложениям. Поскольку каждое событие отражено в своем топике Kafka, можно писать надежные приложения аналитики больших данных в реальном времени и масштабировать их по мере необходимости [1]. Другой интересный кейс потоковой аналитики событий с Apache Kafka и сервисами AWS от еще одной тревел-компании читайте в нашей новой статье.
Освойте все тонкости разработки и администрирования кластера Apache Kafka на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники
- https://engineering.thetrainline.com/building-a-data-lake-from-batch-to-real-time-using-kafka-67272041b124
- https://aws.amazon.com/ru/athena/

