
Чтобы добавить в наши практические курсы по Apache Kafka еще больше интересных примеров, сегодня рассмотрим кейс немецкой ИТ-компании Mobimeo, которая несколько раз перекраивала свою систему аналитики больших данных, чтобы быстро узнавать о событиях клиентских приложений. Читайте далее, зачем дата-инженеры Mobimeo предпочли AVRO формату JSON, почему вместо брокера сообщений ActiveMQ решили использовать Apache Kafka и как организовали интеграцию с AWS-сервисами.
Предыстория: зачем Mobimeo менять архитектуру системы аналитики больших данных
Сперва кратко расскажем о бизнес-контексте: Mobimeo была основана в 2018 году как дочерняя компания основного железнодорожного оператора Германии Deutsche Bahn AG. В 2020 году Mobimeo приобрела часть ИТ-корпорации moovel Group GmbH, став одним из крупнейших в Европе разработчиков платформ travel-приложений «Мобильность как услуга» [1].
Первое аналитическое решение в Mobimeo имело довольно простой дизайн [2]:
- события из клиентских мобильных приложений поадали в сервисы компании через open-source брокер сообщений ActiveMQ или через Rest API в виде JSON;
- поступив в сервис Mobimeo, события загружаются в корзину объектного облачного хранилища Amazon Web Services (AWS) S3;
- аналитика событий в AWS S3 выполняется через AWS Athena – интерактивного сервиса SQL-запросов, интегрированного с каталогом данных AWS Glue. Это позволяет создать единый репозиторий метаданных для различных сервисов, сканировать источники данных для обнаружения схем и наполнять каталог новыми или измененными таблицами и определениями разделов, а также обеспечивать версионность схем [3].
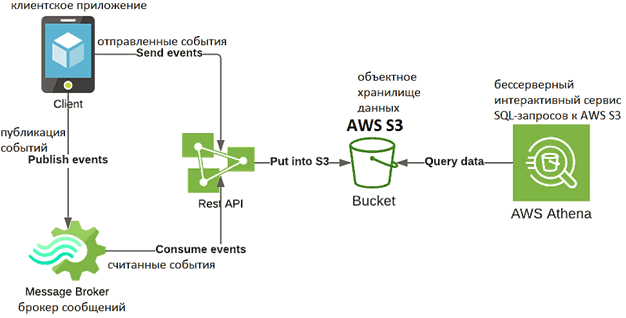
В процессе использования этой архитектуры дата-инженеры специалисты Mobimeo поняли, JSON – не лучший формат данных, т.к. отсутствие четкой структуры вызывает множество несоответствий после изменений в представлении событий. Более того, такая вольность привела к тому, что каждый клиент (iOS, Android и прочие ОС мобильных устройств) самостоятельно определял свои события, предлагая собственные имена и структуры. Это существенно усложняло работу Big Data инженеров, которым приходилось разбираться со множеством данных, приходящих от всех типов клиентов.
Изначально в Mobimeo использовался подход был Code First, согласно которому код для клиентов определял содержание событий. Однако, по мере понимания проблемы стало ясно, что необходимо централизовать и организовать саму работу с событиями. Изменив подход на Contract First, команда разработчиков определила, что сперва пишется контракт, т.е. определение события перед разработкой кода, которому должны следовать клиенты. Такое изменение подхода к разработке повлекло внедрение новой архитектуры, поддерживающей различные схемы описания событий. Что именно было сделано и как, мы рассмотрим далее.
AVRO и Kafka vs JSON и ActiveMQ
Для решения вышеописанных проблем с форматом JSON, дата-инженеры Mobimeo решили перейти на AVRO. В свою очередь, эта схема сериализации/десериализации данных отлично работает с Apache Kafka благодаря реестру Confluent Schema Registry, о котором мы рассказывали здесь. Также AVRO обеспечивает встроенную поддержку при использовании с другими библиотеками и фреймворками этой Big Data платформы потоковой передачи событий: Kafka Connect, Kafka Streams, ksqlDB. Впрочем, это не единственный аргумент перехода на Apache Kafka вместо ранее использовавшегося брокера сообщений ActiveMQ.
ActiveMQ – это классическая система обмена сообщениями, разработанная в 2004 году как реализация спецификации Java Message Service (JMS), чтобы удовлетворить требования к реализации JMS-совместимого обмена сообщениями в проекте Apache Geronimo — сервере приложений J2EE с открытым исходным кодом. ActiveMQ состоит из брокера и клиента, которые общаются между собой по протоколу прикладного уровня. Брокер распределяет сообщения, отправленные клиентом по моделям «Очередь сообщений» и «Издатель-Подписчик», предоставляя гарантии их сохранения, транзакционности и высокой доступности, а также механизмы масштабирования [4].
Однако, производительность очереди сообщений и топиков в ActiveMQ снижается при росте количества потребителей на адресате. Кроме того, в отличие от ActiveMQ, Apache Kafka может гарантировать получение сообщений в том порядке, в котором они были отправлены, на уровне раздела, а также включает механизм контрольных сумм (checksum), для определения поврежденных сообщений в хранилище и имеет полный набор функций безопасности. Наконец, благодаря архитектурным особенностям, кластера Apache Kafka можно масштабировать практически неограниченно простым добавлением новых узлов [5]. Таким образом, с учетом контекста применения, растущих объемов данных и будущих расширений своей Big Data системы, компания Mobimeo приняла решение заменить ActiveMQ на Apache Kafka.
Централизовав схемы событий в корпоративном репозитории, разработчики Mobimeo создавали код для клиентов так, чтобы они могли использовать его для обеспечения необходимой структуры данных. Таким образом, с появлением AVRO архитектура всей Big Data системы изменилась [2]:
- вместо брокера сообщений ActiveMQ используется Apache Kafka;
- эффективность работы мобильных клиентов поддерживает интеграция REST API;
- сообщения, полученные в формате JSON, публикуются в топике Kafka, когда события соответствуют схеме AVRO;
- коннектор S3 Sink помещает события в AVRO в новую корзину AWS S3, экспортируя данные из топиков Apache Kafka в объекты S3 и гарантируя строго однократную семантику доставки их потребителям. Размер каждого блока данных определяется количеством записей, записанных в S3, и совместимостью схемы.
- Чтобы текущие SQL-запросы AWS Athena продолжали работать, из предыдущей архитектуры наследуется процесс отправки событий JSON в корзину AWS
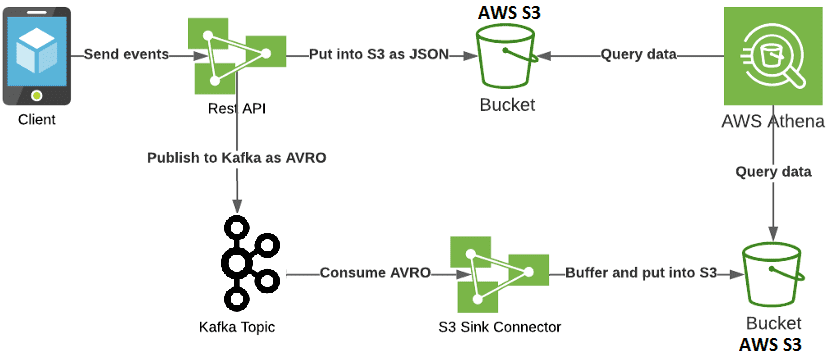
Обновленная архитектура отлично справлялась с запросами структурированных данных, поддерживая схемы AVRO, но имела следующие проблемы [2]:
- зависимость REST API от AWS S3 и от Kafka;
- слишком плотная функциональность REST API: помимо отправки данных в S3, здесь также выполнялось сопоставление каждого события JSON со схемой AVRO с последующей публикацией в топике;
- низкая производительность AWS Athena при запросе событий из корзины JSON, т.к. каждый файл S3 содержит только одно событие JSON. Поэтому сервису SQL-запросов требовалось читать много файлов, что значительно тормозило работу всей системы аналитики больших данных.
Чтобы исправить эти недостатки, Big Data специалисты компании Mobimeo пришли к следующему решению [2]:
- исключена зависимость REST API от AWS S3 и ограничена его функциональность. Теперь он отвечает только за получение событий в формате JSON, проверку их работоспособности и публикацию их в топике Kafka;
- события JSON помещаются в корзину S3 с помощью Sink-коннектора, будучи сгруппированы в один файл, чтобы ускорить выполнение SQL-запросов от Athena;
- добавлен новый компонент системы – приложение Kafka Streams для сопоставления событий JSON от Kafka со схемой AVRO и их публикации в новый топик;
- непосредственно за помещение событий AVRO в корзину S3 отвечает отдельный коннектор S3 Sink.
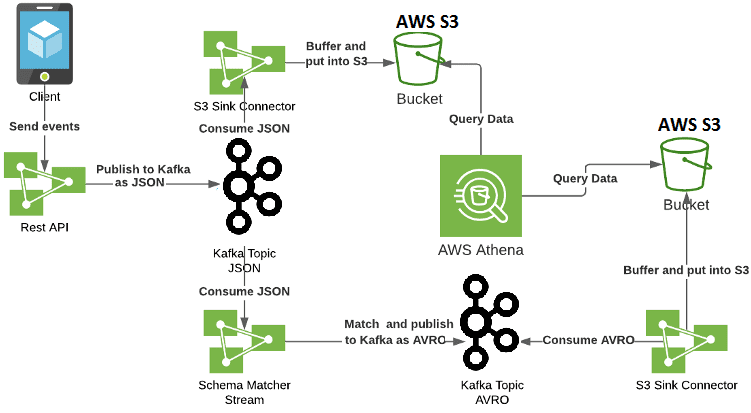
Таким образом, новая архитектура на базе Apache Kafka позволила исправить предыдущие проблемы с зависимостью сервисов и производительностью запросов, а также дала ряд преимуществ [2]:
- простота отладки и воспроизведения ошибок – благодаря наличию всех необработанных события в виде JSON внутри Kafka, можно проверить, почему некоторые события не соответствуют какой-либо схеме AVRO, а также повторить попытку их сопоставления;
- гибкость – если нужно отправить события в какой-то внешний инструмент для дальнейшего анализа, можно использовать другой Sink Connector из топика JSON/AVRO или реализовать нового потребителя Kafka.
Еще больше интересных примеров разработки распределенных приложений потоковой аналитики больших данных с Apache Kafka и кейсов администрирования кластеров вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники
- https://mobimeo.com/en/about-us/
- https://medium.com/mobimeo-technology/how-kafka-helped-us-to-restructure-our-analytics-solution-2f2ee7efeec2
- https://aws.amazon.com/ru/athena/
- https://habr.com/ru/post/471268/
- https://www.educba.com/activemq-vs-kafka/

