
Как разработать свой плагин Apache AirFlow: пошаговое руководство с наглядной демонстрацией. Добавляем свои пункты меню в веб-интерфейс фреймворка и встраиваем пользовательскую HTML-страницу с новым эскизом Flask. Разработка своего плагина для AirFlow Вчера я рассказывала, как расширить функциональные возможности Apache AirFlow с помощью плагинов. Сегодня рассмотрим, как это сделать на практике....
Зачем нужны плагины в Apache AirFlow, как их создать и встроить в пакетный оркестратор для внедрения пользовательских операторов, хуков, датчиков или интерфейсов взаимодействия с внешними системами. Плагины AirFlow Продолжая недавний разговор про добавление пользовательского кода в Apache AirFlow, сегодня разберемся, как расширить функциональные возможности этого ETL-оркестратора с помощью встраиваемых модулей...
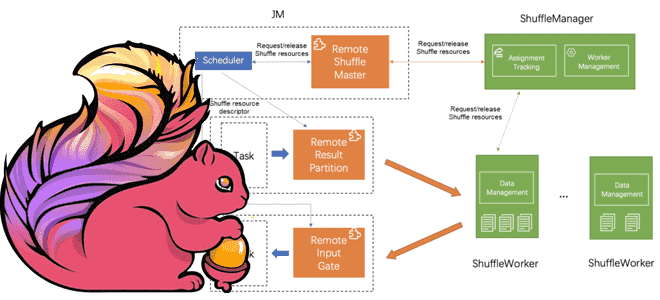
Что такое Remote Shuffle Service в Apache Flink, зачем это нужно и как служба удаленного перемешивания позволяет создавать масштабируемые и надежные приложения для унифицированной потоковой и пакетной обработки больших объемов данных. Что такое Remote Shuffle Service в Apache Flink Apache Flink рассматривает пакетную обработку как частный случай потоковых вычислений. Однако,...

4 октября 2024 года вышел очередной релиз ClickHouse. Знакомимся с его самыми интересными особенностями: добавление строк в обновляемые материализованные представления, агрегатные функции для типов данных JSON и Dynamic, поддержка заголовков HTTP-ответов, автозамена строк с overlay-командами и другие новинки выпуска 24.9. Обновляемые материализованные представления Начнем с наиболее значимой новой функции ClickHouse...

Чем метод applyInPandas() в Spark отличается от apply() в pandas и насколько он быстрее обрабатывает данные: сравнительный тест на датафрейме из 5 миллионов строк. Методы применения пользовательских функций к датафреймам в Spark и pandas Мы уже отмечали здесь и здесь, что Apache Spark позволяет работать с популярной Python-библиотекой pandas, поддерживая...
Как добавить пользовательский код в Apache AirFlow и где его хранить: лучшие практики и рекомендации для дата-инженера с примером создания и импорта своего пакета. Как хранить общий код в AirFlow Недавно мы писали про сложности управления DAG в многопользовательской среде Apache AirFlow. Однако, даже когда речь идет про однопользовательскую работу...
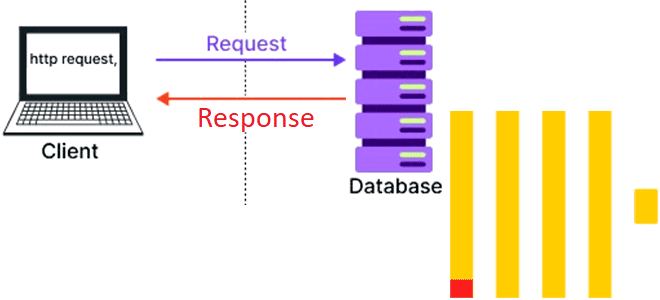
Как реализовать систему с двухзвенной архитектурой на ClickHouse и браузере. Возможности колоночной СУБД для создания одностраничных веб-приложений. Возможности ClickHouse для одностраничных веб-приложений Хотя трехзвенная архитектура (клиент -> бэк-> база данных) уже давно стала стандартом де-факто в разработке веб-приложений, двухзвенная архитектура, когда бизнес-логика переносится в базу данных, до сих пор встречается....
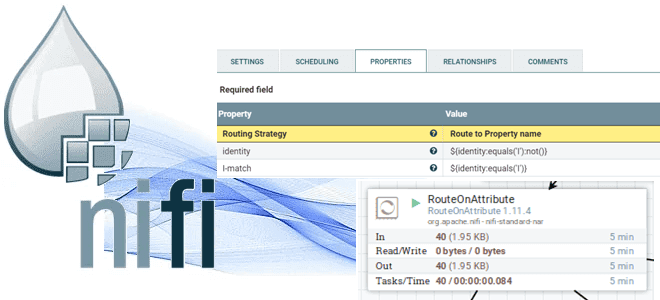
Что такое атрибуты FlowFile, какие процессоры есть в Apache NiFi для работы с ними и как маршрутизировать поток данных на основе пользовательских свойств. Атрибуты FlowFile и процессоры для работы с ними Основной единицей данных, которая перемещается через систему в Apache NiFi является FlowFile. Он представляет собой контейнер для данных и...
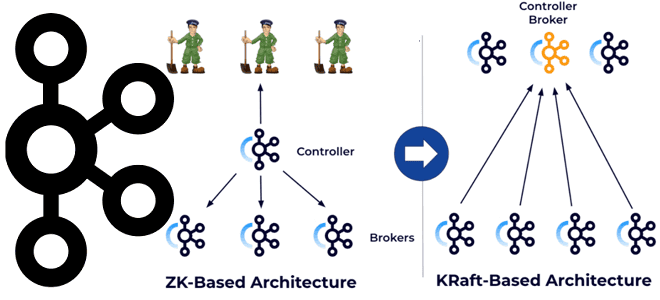
Как перевести кластер Kafka с ZooKeeper на KRaft, чтобы обеспечить управление метаданными с помощью этого протокола консенсуса: последовательность действий и настройки конфигураций. Зачем и как переводить Apache Kafka с Zookeeper на KRaft Напомним, протокол KRaft, который заменяет ZooKeeper для управления метаданными и консенсуса кластера Kafka, был введен еще в версии...

Зачем в Apache Flink 1.20 добавлена новая функция восстановления пакетных заданий после сбоя JobMaster, как она работает и какие параметры надо настроить для повышения ее эффективности. Восстановление пакетных заданий Flink после сбоя JobMaster Как и любой фреймворк стека Big Data, Apache Flink включает множество компонентов, каждый из которых выполняет конкретную...