
Как улучшить интеграцию LLM в бизнес-процессы и информационные системы через стандартизированную передачу контекстной информации: текстовый MCP-протокол для LLM. Что контекстный протокол модели и почему он важен для LLM Одно из ключевых отличий популярных ИИ-инструментов, больших языковых моделей (LLM, Large Language Model) – это их способность генерировать ответы с учетом контекста....

Как LLM упрощают работу дата-инженера: новые декораторы TaskFlow API в Apache Airflow для внедрения больших языковых моделей в DAG. Обзор Airflow AI SDK на основе Pydantic AI с практическим примером про анализ отзывов. ИИ в инженерии данных Мультимодальность современных инструментов машинного обучения, когда одна ML-модель может принимать на вход данные...
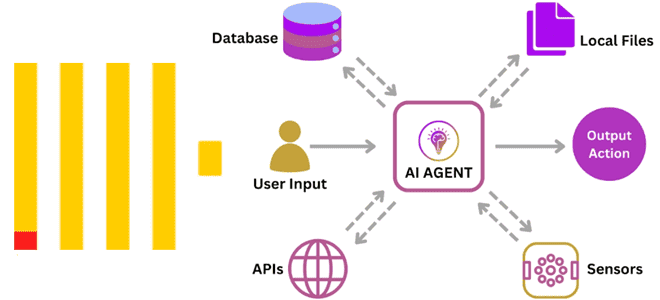
Зачем использовать ClickHouse для аналитики в реальном времени с агентами ИИ и как это сделать: современные вызовы внедрения LLM. Как реализовать ML-систему агентского ИИ с ClickHouse Продолжим разговор про агентский ИИ на основе LLM, когда ML-система не просто реагирует на запросы пользователя, а работает автономно, интеллектуально решая задачи без прямого...
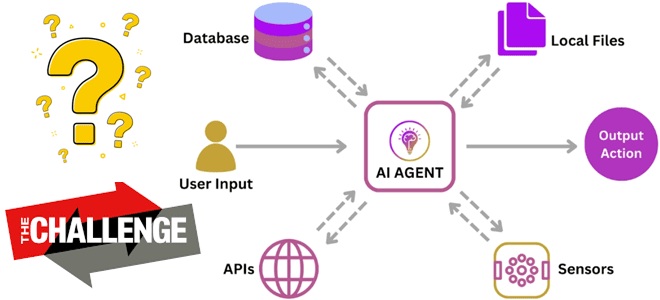
Чем хорош агентский ИИ, какие риски и проблемы с ним связаны, и как их избежать: технические и организационные меры внедрения ML-систем в реальный бизнес. Что сдерживает внедрение агентского ИИ Мы уже писали об агентском ИИ, когда ML-система не просто реагирует на запросы пользователя, а работает автономно, интеллектуально решая задачи без...

Почему генеративный ИИ основан на потоковой обработке данных и EDA-архитектуре, для чего оценивать качество LLM-модели и как построить такую систему мониторинга: подходы и технологии. О важности потоковой обработки данных и EDA-архитектуры для LLM-систем Все больше современных бизнес-приложений включают в себя большие языковые модели (LLM, Large Language Model), чтобы автоматизировать поддержку...

Зачем управлять трансферным обучением больших языковых моделей и что входит в это управление: знакомимся с расширением MLOps для LLM под названием LLMOps. Что такое LLMOps Большие языковые модели, воплощенные в генеративных нейросетях (ChatGPT и прочие аналоги), стали главной технологией уходящего года, которая уже активно используется на практике как частными лицами,...
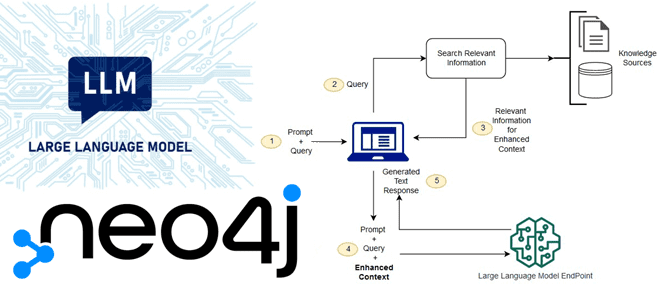
Что не так с большими языковыми моделями, как RAG-приложения расширяют возможности LLM и зачем в графовой СУБД Neo4j добавлена поддержка векторного индекса. Зачем нужны RAG-приложения: ограничения базовых LLM-сетей С появлением ChatGPT и других генеративных нейросетей, большие языковые модели (LLM, Large Language Models) стали активно применяться для решения множества бизнес-задач, связанных...

Как получать результаты обработки данных с помощью Apache Spark, адресуя ИИ бизнес-запросы на английском языке: знакомимся с English SDK от Databricks. Настоящий Low Code с PySpark-AI. English SDK for Apache Spark и PySpark-AI: как это работает Большие языковые модели (LLM, Large Language Model), основанные на генеративных нейросетях, применимы не только...
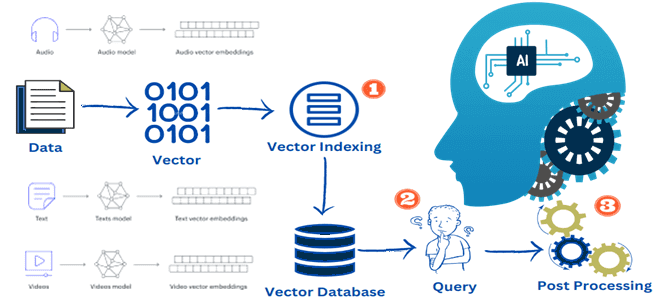
Как устроены векторные базы данных и почему они стали так популярны с распространением ИИ. Архитектура, алгоритмы, принципы работы и примеры векторных СУБД. Что такое векторная СУБД и при чем здесь ИИ Как и следует из названия, векторная база хранит данные в виде векторов. Это понятие из математики означает специализированное представление...
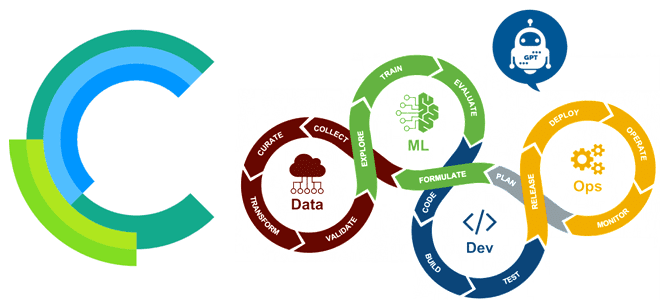
Чтобы сделать наши курсы для специалистов по Data Science и ML-инженеров еще более полезными, сегодня познакомимся с очень мощным инструментом MLOps – open-source платформой ClearML. Что это такое, как работает, насколько упрощает разработку продуктов Machine Learning, а также зачем бизнесу ClearGPT. Что такое ClearML и как это поможет MLOps-инженеру Концепция...