
Сегодня поговорим про особенности транзакций в Apache Spark, что такое фиксация заданий в этом Big Data фреймворке, как она связано с протоколами экосистемы Hadoop и чем это ограничивает переход в облако с локального кластера. Читайте далее, как найти компромисс между безопасностью и высокой производительностью, а также чем облачные хранилища отличаются...

В этой статье рассмотрим, что такое Apache Spark Structured Streaming и Spark Streaming, чем они отличаются и что общего между этими 2-мя способами обработки потоковых данных в самом популярном фреймворке аналитики больших данных. Читайте далее, как микро-пакетная передача приближается к режиму реального времени и при чем здесь структуры данных для...

Вчера мы говорили про реализацию exactly once семантики доставки сообщений в Apache Spark Structured Streaming. Сегодня рассмотрим, что не так с размером компактных файлов для хранения контрольных точек потоковой передачи, какие параметры конфигурации Spark SQL отвечают за такое логирование и как ускорить микро-пакетную обработку больших данных и чтение результатов выполнения...

Недавно мы рассматривали оптимизацию SQL-запросов и выполнение JOIN-операций в Apache Spark. Сегодня поговорим, что обеспечивает строго однократную семантику доставку сообщений (exactly once) в этом Big Data фреймворке и как на это влияют особенности микро-пакетной обработки больших данных с помощью заданий Spark Structured Streaming. Особенности exactly once доставки сообщений в Apache...
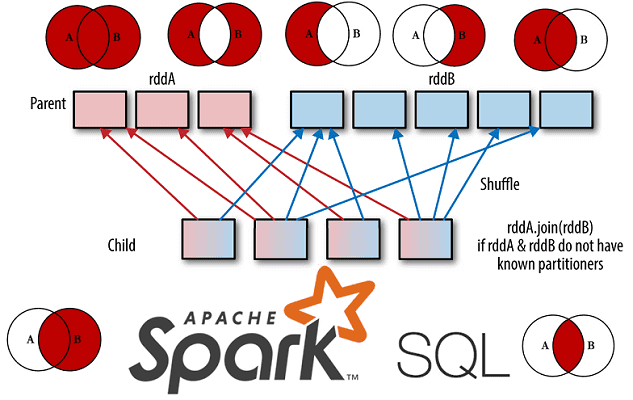
Развивая наши новые курсы по Apache Spark, сегодня мы рассмотрим Join-операции в SQL-модуле этого популярного фреймворка для аналитики больших данных. Читайте далее, чем отличаются разные Join-соединения друг от друга, как они реализуются в Spark SQL, какие существуют механизмы для их выполнения и от чего зависит выбор того или иного способа...

Обучение Apache Spark, Kafka, Hadoop и прочим технологиям Big Data – это не только курсы, теоретические статьи и практические задания, но и проверка полученных знаний. Поэтому сегодня мы предлагаем вам открытый интерактивный тест по основам Спарк для начинающих. Проверьте, насколько хорошо вы знакомы с особенностями администрирования и эксплуатации этого популярного...
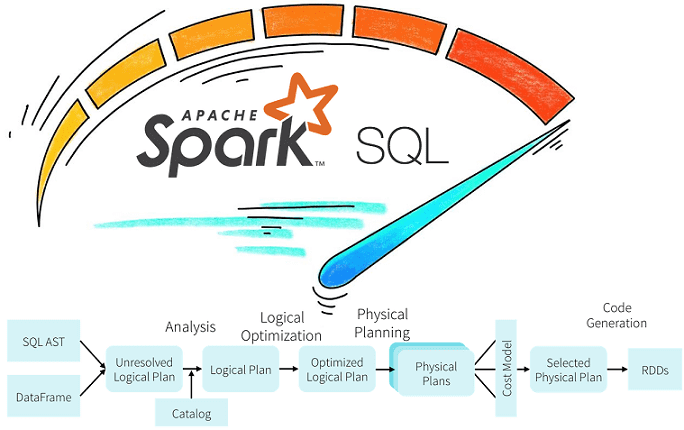
Продолжая разбирать практические особенности аналитики больших данных с Apache Spark, сегодня рассмотрим возможности оптимизации SQL-запросов в этом Big Data фреймворке с помощью механизмов предикатного и проекционного сжатия. Читайте далее про реализацию Predicate Pushdown и Projection Pushdown в Apache Spark 3, а также их связь с форматами Parquet и AVRO. Механизмы...

Продолжая рассказывать про курсы Apache Spark для разработчиков на практических примерах, сегодня рассмотрим, как кэширование данных позволяет оптимизировать распределенные вычисления в этом Big Data фреймворке. Читайте далее, как ускорить выполнение запросов в Spark SQL, чем отличаются функции cache() и persist(), из чего состоит план запроса и каковы альтернативы кэшированию данных...

Поскольку курсы по Apache Spark нужны не только разработчикам распределенных приложений, но и аналитикам больших данных с дата-инженерами, сегодня мы рассмотрим, какие средства этого фреймворка позволяют выполнять очистку данных и повышать их качество. Читайте далее, что такое Cleanframes в Spark SQL, чем полезна эта библиотека и каковы ее ограничения. Apache...
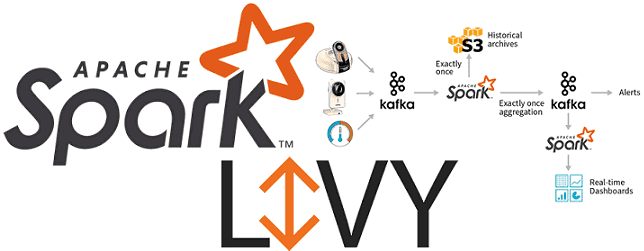
Вчера мы рассказывали про особенности совместного использования Apache Spark с Airflow и достоинства подключения Apache Livy к этой комбинации популярных Big Data фреймворков. Сегодня рассмотрим подробнее, как работает Apache Livy, а также за счет чего этот гибкий API обеспечивает удобство работы с Python-кодом и общие Spark Context’ы для разных операторов...