 823
823 
Содержание
Продолжая рассказывать про курсы Apache Spark для разработчиков на практических примерах, сегодня рассмотрим, как кэширование данных позволяет оптимизировать распределенные вычисления в этом Big Data фреймворке. Читайте далее, как ускорить выполнение запросов в Spark SQL, чем отличаются функции cache() и persist(), из чего состоит план запроса и каковы альтернативы кэшированию данных для повторного использования вычислений.
Как устроено кэширование данных в Spark SQL
Кэширование данных в Apache Spark SQL — это весьма популярный способ повышения производительности приложения за счет повторного использования некоторых вычислений. Однако, чтобы эффективно использовать его, следует помнить о некоторых особенностях настройки Spark-приложений. Часть этих рекомендаций мы разбирали вчера, на примере перехода от локальных Pyhon-скриптов к распределенным заданиям PySpark. Подобные лучшие практики (best practices) существуют и для Spark SQL.
Напомним, в API DataFrame есть две функции, которые можно использовать для кеширования этой структуры данных [1]:
- cache() – cохраняет DataFrame с уровнем хранения по умолчанию (MEMORY_AND_DISK) в соответствии со Scala 0 [2];
- persist() – устанавливает уровень хранения для содержимого DataFrame между операциями после первого вычисления. Это можно использовать только для назначения нового уровня хранения, если он еще не установлен для датафрейма [2].
Разница между cache() и persist() в том, что последний может принимать необязательный аргумент storageLevel, с помощью можно указать, где именно данные будут сохраняться. По умолчанию значение storageLevel для обеих функций — MEMORY_AND_DISK, т.е. данные будут храниться в памяти, если там есть для них есть место. Иначе данные будут сохранены на диске [1]. Вообще PySpark-класс StorageLevel(useDisk, useMemory, useOffHeap, deserialized, replication=1) содержит флаги для управления хранением RDD: следует ли использовать память, сбрасывать ли RDD на диск при нехватке RAM, хранить данные в памяти в сериализованном JAVA-формате и реплицировать ли разделы RDD на нескольких узлах. Также StorageLevel содержит статические константы для некоторых часто используемых уровней хранения, таких как MEMORY_ONLY, OFF_HEAP, MEMORY_AND_DISK, DISK_ONLY. Поскольку данные всегда сериализуются на стороне Python, все константы используют сериализованные форматы [2].
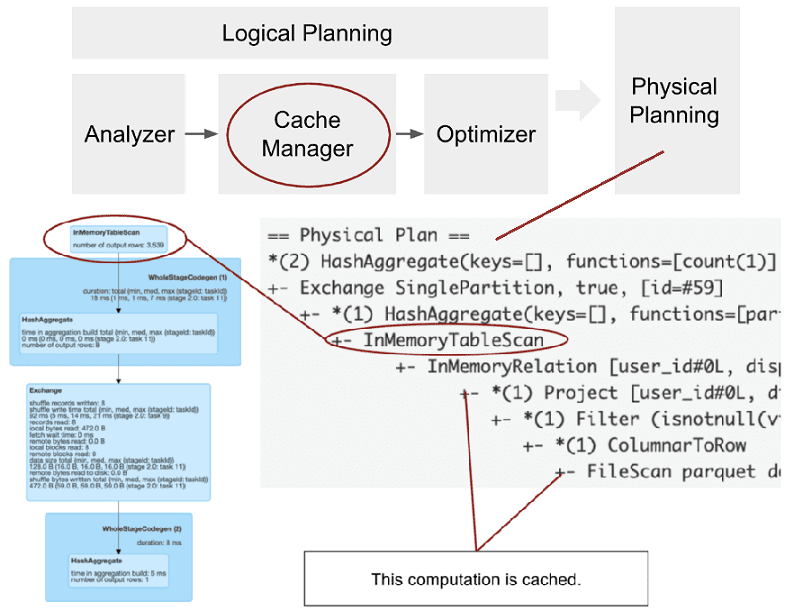
Поскольку кэширование — это ленивое (отложенное) преобразование, то сразу после вызова функции с данными ничего не происходит. План запроса обновляется диспетчером кеширования путем добавления нового оператора — InMemoryRelation. Эта информация будет использоваться во время выполнения запроса позже, после вызова какого-либо действия. Apache Spark будет искать данные на уровне кэширования и считывать их оттуда, если они доступны. Если данные не найдены на уровне кэширования, что наверняка произойдет при первом запуске запроса, то уровень кэширования становится ответственным за получение данных и сразу же после этого использует их.
Менеджер кэша (Cache Manager) отвечает за отслеживание того, какие вычисления уже были кэшированы с точки зрения плана запроса. При вызове функции кэширования автоматически вызывается Cache Manager, который извлекает проанализированный логический план датафрейма и сохраняет его в индексированной последовательности (cachedData). Это является частью логического планирования и проходит после анализатора и до оптимизатора SQL-запроса.
При запуске SQL-запроса с действием, план запроса будет обработан и преобразован. На этапе Cache Manager (непосредственно перед оптимизатором) Spark проверит каждое поддерево анализируемого плана, если оно хранится в последовательности cachedData. Если совпадения найдены, это означает, что тот же план, т.е. то же самое вычисление уже было кэшировано, возможно, в каком-то предыдущем запросе. Поэтому Apache Spark может его использовать снова и добавляет эту информацию в план запроса с помощью оператора InMemoryRelation. InMemoryRelation содержит информацию о кэшированном плане и используется на этапе физического планирования для создания физического оператора — InMemoryTableScan.
ТОП-5 рекомендаций по кэшированию Big Data в Apache Spark
Освежив знания по теории кэширования данных в Apache Spark, далее рассмотрим советы, которые помогут повысить эффективность этого способа оптимизации распределенных приложений [1]:
- при кэшировании датафрейма создайте для него новую переменную cachedDF= cache(). Это позволит всякий раз при вызове cachedDF.select(…) использовать кэшированные данные.
- Если DataFrame больше не нужен, используйте cachedDF.unpersist(). Когда уровень кэширования заполнится, Spark начнет вытеснять данные из памяти, которые использовались давно по стратегии LRU (Least Recently Used). Unpersist() позволит контролировать, что именно следует вытеснить. Чем больше места в памяти, тем более эффективно будут работать Spark-приложения.
- Перед кешированием убедитесь, что вы кешируете только то, что снова понадобится в SQL-запросах. Например, если один запрос будет использовать (col1, col2, col3), а второй запрос будет использовать (col2, col3, col4), выберите надмножество этих столбцов: cachedDF=df.select(col1, col2, col3, col4).cache(). Вызывать cachedDF= df.cache() не стоит, если датафрейм содержит много столбцов, из которых в последующих запросах будет использовать только небольшая часть.
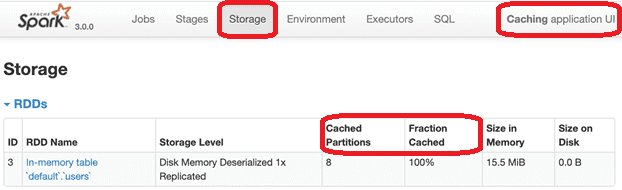
- Пользуйтесь UI, чтобы посмотреть сведения об уже кэшированных данных. Например, в веб-GUI Spark для каждого кэшированного набора данных можно увидеть, сколько места он занимает в памяти или на диске с детализацией по каждому разделу. Подробнее, о том, что еще можно просмотреть в веб-GUI этого Big Data фреймворка, читайте в нашей новой статье.
Чтобы проверить, кэширована ли вся таблица, можно использовать API каталога:
spark.catalog.isCached(«table_name»)
Через API каталога также можно удалить все данных из кэша: spark.catalog.clearCache ().
В Scala API можно использовать внутренний API Cache Manager, который предоставляет некоторые дополнительные функции. В частности, можно проверить, пуст ли Cache Manager:
val cm = spark.sharedState.cacheManager
cm.isEmpty
Можно использовать Spark SQL вместо DataFrame DSL для кэширования данных: spark.sql(«cache table table_name»). При этом кэширование по умолчанию выполняется немедленно, Spark-задание запускается сразу же и помещает данные на уровень кэширования. Чтобы сделать его отложенным (ленивым), как в DSL DataFrame, следует явно использовать ключевое слово lazy: spark.sql(«cache lazy table table_name»). Для удаления данных из кэша используется spark.sql(«uncache table table_name»). Если не сделать это вовремя, то может возникнуть казус при изменении кэшированного датафрейма, который мы описываем здесь.
- Помните, что при всех своих достоинствах, кэширование также имеет накладные расходы, связанные с размещением данных в памяти. Поэтому в некоторых случаях повторное вычисление может оказаться быстрее, чем работа с кэшем. Например, если идет обработка запросов на больших наборах данных, хранящихся в колоночных файлах в формате, который поддерживает обрезку столбцов и изменение предикатов, в частности, Parquet. В Parquet запросы выполняются быстро сами по себе: при чтении Spark считывает только метаданные, без сканирования всего набора данных. Для конкретного запроса будет сканироваться только нужный столбец. А при чтении данных из кеша Spark прочитает весь набор данных, что потребует больше времени. Кроме того, в случае большого датасета он просто не умещается полностью в RAM. Часть данных хранится на диске, считывание откуда выполняется намного медленнее, чем из оперативной памяти.
В заключение подчеркнем, что кэширование – не единственный способ для повторного использования некоторых вычислений. Также есть механизм контрольных точек (checkpointing) и обмен с повторным использованием (exchange-reuse).
Контрольные точки полезны, например, в ситуациях, когда нужно изменить план запроса, потому что он слишком велик. Большой план запроса может стать узким местом в драйвере, где он обрабатывается, т.к. обработка займет слишком много времени. Контрольная точка нарушит план и материализует запрос, а Spark построит новый план для следующих преобразований. Контрольная точка связана с функциями checkpoint() и localCheckpoint(), которые отличаются хранилищем, используемым для данных. Почему механизмом контрольных точек следует пользоваться с осторожностью, мы рассказываем здесь.
Exchange-reuse, при котором Spark сохраняет выходные данные перемешивания на диске, представляет собой метод, которым нельзя напрямую управлять с помощью какой-либо функции API. Но вместо этого есть внутренняя функция, которую Spark обрабатывает самостоятельно. В некоторых особых ситуациях им можно управлять косвенно, переписав запрос, чтобы получить идентичные ветви обмена [1].
Понять все тонкости администрирования и разработки Apache Spark для аналитики больших данных вы сможете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Основы Apache Spark для разработчиков
- Анализ данных с Apache Spark
- Потоковая обработка в Apache Spark
Источники
- https://towardsdatascience.com/best-practices-for-caching-in-spark-sql-b22fb0f02d34
- https://spark.apache.org/docs/latest/api/python/pyspark.sql/

