 1363
1363 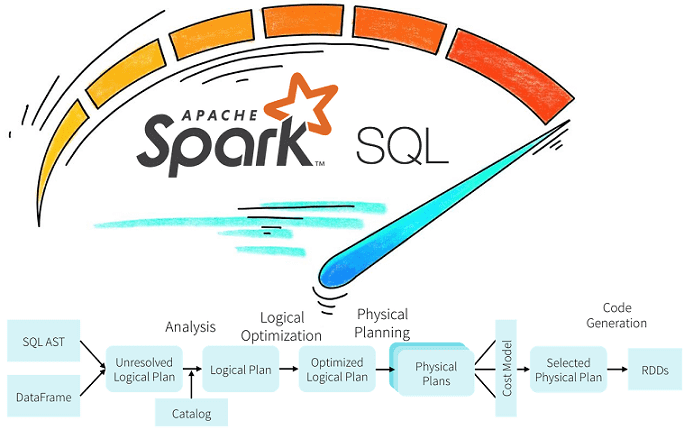
Содержание
Продолжая разбирать практические особенности аналитики больших данных с Apache Spark, сегодня рассмотрим возможности оптимизации SQL-запросов в этом Big Data фреймворке с помощью механизмов предикатного и проекционного сжатия. Читайте далее про реализацию Predicate Pushdown и Projection Pushdown в Apache Spark 3, а также их связь с форматами Parquet и AVRO.
Механизмы оптимизации SQL-запросов или что такое Predicate Pushdown и Projection Pushdown
Напомним, при выполнении SQL-запроса, прежде всего происходит его анализ и логическая оптимизация, когда к логическому плану запроса применяются типовые правила. Одним из них является Predicate pushdown – оптимизация, которая применяет условия (предикаты) как можно раньше, предотвращая загрузку ненужных строк.
Этот механизм связан с предикатами, которые являются частью SQL-оператора, фильтрующего данные. Предикаты в математической логике аналогичны логическим условиям (clause) в SQL – утверждениям, которые могут иметь значение ИСТИНА (True) или ЛОЖЬ (False) для разных значений переменных или данных. Применение Predicate pushdown ограничено некоторыми особенностями, например, join-предикаты нельзя поместить после первого join-соединения, на которое они влияют. Но предикаты можно передать через группировку (group by) и оконные функции, если они находятся среди ключей группирования или разделения. Predicate pushdown повышает эффективность работы индексов [1].
В случае обработки больших объемов данных (Big Data) этот механизм может улучшить производительность запросов за счет уменьшения считываний из хранилища и сокращения передаваемого трафика. К примеру, процесс СУБД оценивает предикаты фильтра в запросе по метаданным, хранящимся в файлах хранилища, чтобы считывать только те данные, которые нужны. Для успешного применения этого механизма на практике хранилище данных должно отвечать следующим условия [2]:
- сбалансированность, т.е. размер файлов метаданных меньше фактических файлов данных;
- наличие метаданных и индексов.
Еще одним механизмом оптимизации SQL-запроса является сжатие проекций или исключение столбцов. Projection Pushdown направлено на то, чтобы как можно раньше удалить ненужные столбцы или не извлекать их вообще. При наличии индекса в удаленном столбце база данных может удовлетворить запрос только из индекса (сканирование только по индексу), не извлекая остальные столбцы из самой таблицы. Это может на порядок повысить скорость выполнения запросов [1]. Projection Pushdown хранит данные в столбцах, поэтому, когда проекция ограничивает запрос определенными столбцами, будут возвращены только они [3].
Как устроены Pushdown-механизмы оптимизации в Apache Spark SQL
В Apache Spark Predicate Pushdown позволяет оптимизировать запросы Spark SQL, фильтруя данные в запросе к СУБД и уменьшая количество извлекаемых записей. По умолчанию Spark Dataset API автоматически передает действительные WHERE-условия в базу данных. Поэтому при создании запросов Spark SQL, использующих операторы сравнения, проверка правильности передачи предикатов в базу данных критически важна для получения корректных данных с максимальной производительностью [4].
В частности, при работе с условными операторами WHERE или FILTER сразу после загрузки датасета, Spark SQL будет пытаться передать эти предикаты источнику данных, используя соответствующий запрос SQL с условием предложением WHERE. Таким образом, фильтрация опускается до источника данных. и выполняется на очень низком уровне, а не работает со всем датасетом после его загрузки в память Spark, чтобы избежать проблем с ней. Predicate Pushdown также применяется к SQL-запросам с фильтрами после проекций или фильтрацией по разделам временного окна.
Поскольку Predicate Pushdown работает с WHERE или FILTER, его можно назвать строковым, т.к. эти условия влияют на количество возвращаемых строк. Совмещение предикатного сжатия с сокращением разделов (Partition Pruning) повышает производительность чтения каталогов и файлов из файловой системы, позволяя читать только нужные файлы в указанном разделе. Таким образом, фильтрация данных смещается еще ближе к их источнику, предотвращая сохранение ненужных данных в памяти с целью уменьшения дискового ввода-вывода. К примеру, файлы в столбцовом формате Parquet содержат различные статистические показатели для каждого столбца, включая минимальное и максимальное значения. Predicate Pushdown помогает пропустить нерелевантные данные и работать только с нужными [3].
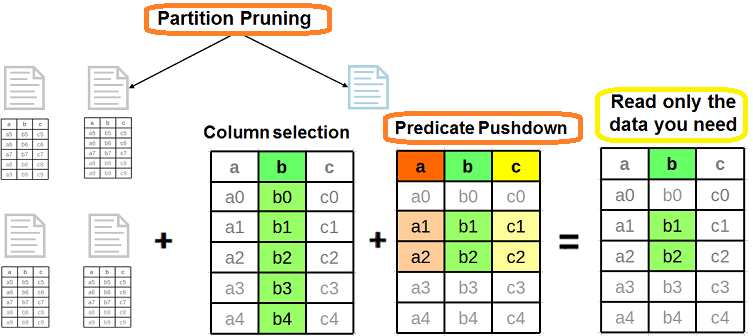
В отличие от сжатия предикатов, сжатие проекций можно назвать столбцовым, поскольку оно ориентировано на сокращение количества передаваемых столбцов, а не строк. Например, если фильтр Predicate Pushdown пропускает только 5% строк, то лишь 5% таблицы будет передано из хранилища в Spark вместо полного набора данных. А если Projection Pushdown выбирает только 3 столбца из 10, то именно они будут переданы из хранилища в Spark. В случае столбцового формата файлов (Parquet, а не AVRO) невыбранные столбцы даже не будут частью фильтра и их не придется читать [5].
Таким образом, Projection Pushdown позволяет свести к минимуму передачу данных между файловой системой или СУБД и движком Spark, удаляя ненужные поля из процесса сканирования таблицы. Это полезно, когда набор данных содержит слишком много столбцов. В свою очередь, Predicate Pushdown повышает производительность за счет уменьшения объема данных, передаваемых между файловой системой или СУБД и механизмом Apache Spark при фильтрации. Pushdown Filtering работает с разделенными столбцами аналогично файлам в формате Parquet. Чтобы это было максимально эффективно, столбцы разделов должны содержать значения меньшего размера с соответствующими данными для разброса нужных файлов по каталогам. Следует избегать слишком большого количества файлов небольшого размера, которые могут снизить эффективность сканирования из-за чрезмерного параллелизма. А малое число файлов большого размера может нарушить параллелизм распределения PySpark-заданий по кластеру, о чем мы рассказывали здесь. О других особенностях оптимизации структурированных запросов в Apache Spark SQL с помощью оптимизатора Catalyst читайте в нашей отдельной статье. В этом материале мы разбираем тонкости соединения двух наборов через SQL-операцию JOIN. А про построение конвейеров машинного обучения в Apache Spark MlLib с использованием структуры данных из SQL, Dataframe, мы поговорим в следующий раз.
Разобраться с особенностями оптимизации SQL-запросов в Apache Spark SQL для эффективной разработки распределенных приложений для аналитики больших данных вы сможете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Основы Apache Spark для разработчиков
- Потоковая обработка в Apache Spark
- Анализ данных с Apache Spark
- Машинное обучение в Apache Spark
- Графовые алгоритмы в Apache Spark
Источники
- https://modern-sql.com/feature/with/performance
- https://medium.com/microsoftazure/data-at-scale-learn-how-predicate-pushdown-will-save-you-money-7063b80878d7
- https://towardsdatascience.com/predicate-vs-projection-pushdown-in-spark-3-ac24c4d11855
- https://docs.datastax.com/en/dse/6.0/dse-dev/datastax_enterprise/spark/sparkPredicatePushdown/
- https://stackoverflow.com/questions/58235076/what-is-the-difference-between-predicate-pushdown-and-projection-pushdown

