
В рамках обучения дата-инженеров и ML-специалистов лучшим практикам MLOps, сегодня рассмотрим практический пример построения конвейера машинного обучения на Airflow, MLFlow, SageMaker и других сервисах Amazon. А также как Apache Spark версии 3 сократил расходы на облачный EMR-кластер почти в 2 раза. MLOps с AirFlow и MLFlow в облаке AWS Ранее...
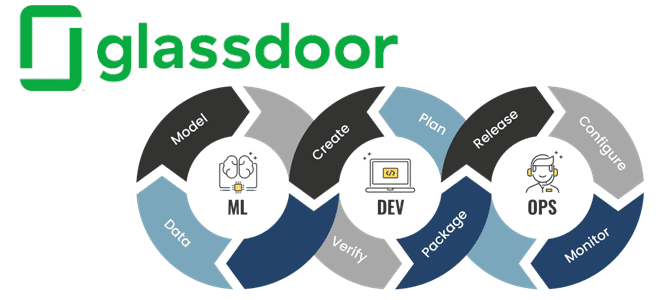
Практическая реализация MLOps-концепции на примере международной рекрутинговой компании Glassdoor. Как построить самоуправляемую автоматизированную систему разработки и сопровождения ML-моделей с MLFlow, Apache Spark и AirFlow, Kubernetes, GitLab, SageMaker Feature Store, Whylogs, Jenkins, Spinnaker и Prometheus с Grafana. Предыстория: зачем MLOps в Glassdoor Glassdoor с 2008 года помогает соискателям по всему миру...

MLOps и построение конвейеров машинного обучения – одни из самых актуальных задач современной Data Science. Сегодня рассмотрим, чем совместное использование Apache Airflow и Ray полезно для дата-инженера и ML-разработчика. Читайте далее про кластерное развертывание Python-кода ML-моделей и упрощение ETL-процессов с Apache Airflow и Ray. Apache AirFlow для ML: возможности и...

Продолжая вчерашний разговор про Delta Lake на базе Apache Spark от Databricks, сегодня мы расскажем одну из последних новостей о запуске этого решения на Google Cloud с середины февраля 2021 года. Читайте далее, чем хороша эта проприетарная Big Data платформа для аналитики больших данных на Spark, инструментах визуализации и MLOps,...
Сегодня поговорим про особенности построения конвейеров машинного обучения в Apache Spark. Читайте далее, как Spark MLLib реализует идеи MLOps, что такое трансформеры и оценщики, из чего еще состоит Machine Learning pipeline, как он работает с кодом на Scala, Java, Python и R, а также каковы условия практического использования методов fit(),...
Вчера мы говорили про промышленный Machine Learning в больших данных и рассматривали проблемы микросервисной архитектуры в системах машинного обучения. Продолжая разбирать, как Feature Store повышает эффективность MLOps-процессов, сокращая цикл разработки согласно Agile-идеям, сегодня мы приготовили для вас краткий обзор хранилища признаков StreamSQL. Читайте далее, что такое StreamSQL, как оно устроено,...
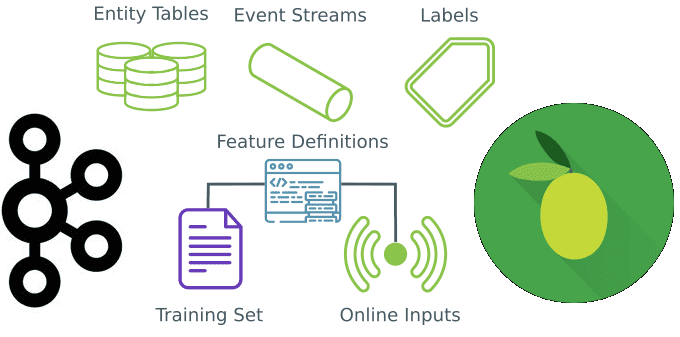
Сегодня рассмотрим, когда микросервисные архитектуры не подходят для систем машинного обучения и какие технологии Big Data следует использовать в этом случае. В этой статье мы расскажем, что такое Feature Store, как это хранилище признаков для моделей Machine Learning повышает эффективность MLOps-процессов и сокращает цикл разработки ML-систем, а также при чем...
Чтобы максимально приблизить обучение Airflow к практической работе дата-инженера, сегодня мы рассмотрим, какие еще есть альтернативы для оркестрации ETL-процессов и конвейеров обработки больших данных. Читайте далее, что такое Luigi, Argo, MLFlow и KubeFlow, где и как они используются, а также почему Apache Airflow все равно остается лучшим инструментом для оркестрации...

При всех своих достоинствах Delta Lake, включая коммерческую реализацию этой Big Data технологии от Databricks, оно обладает рядом особенностей, которые могут расцениваться как недостатки. Сегодня мы рассмотрим, чего не стоит ожидать от этого быстрого облачного хранилище для больших данных на Apache Spark и как можно обойти эти ограничения. Читайте далее,...

Продолжая разговор про Delta Lake, сегодня мы рассмотрим, чем это быстрое облачное хранилище для больших данных в реализации компании Databricks отличается от классического озера данных (Data Lake) на Apache Hadoop HDFS. Читайте далее, как коммерческое Cloud-решение на Apache Spark облегчает профессиональную деятельность аналитиков, разработчиков и администраторов Big Data. Больше, чем...