Вчера мы упоминали, как долгожданный KIP-500, реализованный в марте 2021 года, позволяет не только отказаться от Zookeeper в кластере Apache Kafka, но и снимает ограничение числа разделов, чтобы масштабировать брокеры практически до бесконечности. Однако, не все так просто: читайте далее, какие важные функции еще не поддерживаются в этом экспериментальном режиме...
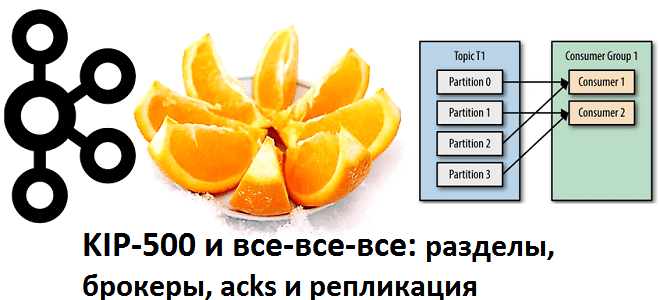
Сегодня рассмотрим важную практическую задачу из курсов Kafka для разработчиков и администраторов кластера – разделение топиков по брокерам. Читайте далее, как пропускная способность всей Big Data системы зависит от числа разделов, коэффициента репликации и ответного ack-параметра, а также при чем здесь KIP-500, позволяющий отказаться от Zookeeper. Что такое партиционирование в...
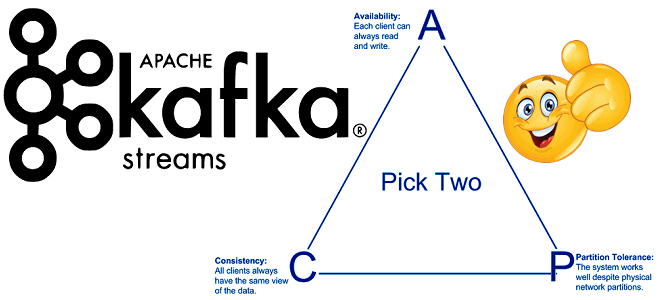
Продолжая включать интересные практические примеры в наши курсы Apache Kafka для разработчиков, сегодня поговорим о согласованности в распределенных системах с высокой доступностью. Читайте далее, что такое eventual consistency, почему это важно для микросервисной архитектуры, при чем здесь ограничения CAP-теоремы и как решить проблемы обеспечения конечной согласованности с Kafka Streams. ...
Чтобы сделать наши курсы по Apache Kafka еще более полезными, сегодня мы поговорим про базовые и расширенные возможности обеспечения информационной безопасности этой Big Data платформы. А в качестве практического примера разберем кейс международной финтех-компании BlackRock, которая разработала собственное security-решение для Kafka на базе протокола OAuth и серверов единого доступа KeyCloak....

В феврале 2021 года разработчики корпоративной версии Apache Kafka с коммерческой поддержкой, компания Confluent, выпустили премиум-коннектор к Oracle – одной из главных реляционных баз данных мира enterprise. Разбираемся, кому и зачем это нужно, а также как устроена такая интеграция SQL-СУБД и потоковой аналитики Big Data с применением CDC-подхода. Реляционный монолит...

Постоянно добавляя в наши курсы Apache Kafka для разработчиков интересные и практические примеры, сегодня мы разберем кейс тревел-площадки Trainline, которая агрегирует данные от 270 железнодорожных и автобусных компаний в 45 странах, предлагая выгодные билеты на европейские поезда и автобусы. Читайте далее, почему пакетный режим работы озера данных перестал отвечать требованиям...

Сегодня рассмотрим пример построения системы аналитики больших данных для мониторинга финансовых транзакций в реальном времени на базе облачного Delta Lake и конвейера распределенных приложений Apache Kafka, Spark Structured Streaming и других технологий Big Data. Читайте далее о преимуществах облачного Delta Lake от Databricks над традиционным Data Lake. Постановка задачи: финансовая...

В этой статье рассмотрим типичные проблемы топиков Apache Kafka, с которыми сталкивается каждый администратор Big Data кластера. Читайте далее, почему топики чрезмерно разрастаются, как работает очистка логов, когда старые сообщения могут остаться в почищенных сегментах и какие параметры конфигураций помогут справиться со всем этим. Брокеры и разделы: как устроены топики...

Чтобы дополнить наши курсы по Spark для разработчиков распределенных приложений и инженеров данных практическими примерами, сегодня рассмотрим кейс американской ИТ-компании ThousandEyes, которая разрабатывает программное обеспечение для анализа производительности локальных и глобальных сетей. Читайте далее, как создать надежный конвейер и устойчивое озеро данных (Data Lake) для быстрой аналитики Big Data в...

Спустя пару месяцев с выпуска Apache Kafka 2.7.0, Confluent анонсировал новый релиз этой платформы потоковой передачи событий, в котором, наконец, случится долгожданный отказ от Zookeeper. Читайте далее, как это облегчит жизнь администратору Kafka-кластера и разработчику распределенных приложений потоковой аналитики больших данных, а также как подготовить свою Big Data инфраструктуру к...