Продолжая включать интересные практические примеры в наши курсы Apache Kafka для разработчиков, сегодня поговорим о согласованности в распределенных системах с высокой доступностью. Читайте далее, что такое eventual consistency, почему это важно для микросервисной архитектуры, при чем здесь ограничения CAP-теоремы и как решить проблемы обеспечения конечной согласованности с Kafka Streams.
Что такое eventual consistency или как хакнуть CAP-теорему в распределенных микросервисах
Простота реализации микросервисных решений часто оборачивается сложностью их проектирования. В частности, если один из сервисов изменил состояние какого-то объекта, другие сервисы должны знать об этом как можно скорее (в идеале – сразу же), чтобы избежать несогласованности данных. К примеру, работы по сборке и доставке товара начнутся только после того, как заказ оплачен, и желательно, сразу же после наступления этого события. При этом за процессы создания заказа, оплаты, сборки и доставки отвечают разные сервисы.
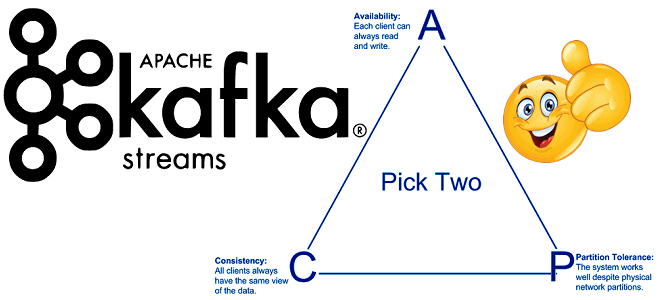
Однако, добиться такой согласованности данных в распределенных системах не так-то просто. Не случайно CAP-теорема для распределенных систем гласит, что из 3 возможных состояний (Consistency — Согласованность, Availability – Доступность и Partition tolerance — Устойчивость к разделению) одновременно возможны лишь 2. При этом для микросервисов достижение максимальной согласованности является наиболее затратным из-за требований к распределенным транзакциям с двухфазной фиксацией (2PC). Такие транзакции имеют низкую производительность, ограниченную масштабируемость и требуют тесной связи сервисов друг с другом. Напомним, согласованность является одним из 4-х ключевых свойств ACID (Atomicity — атомарность, Consistency — консистентность, Isolation — изолированность, Durability – долговечность), характерных для транзакций. В случае микросервисов необходимо гарантировать ACID транзакций в распределенной системе с низкими затратами при сохранении слабосвязанной архитектуры.
Архитектура Данных
Код курса
ARMG
Ближайшая дата курса
19 мая, 2025
Продолжительность
24 ак.часов
Стоимость обучения
72 000 руб.
Чаще всего из всех моделей согласованности для распределенных систем современные микросервисные архитектуры выбирают конечную согласованность (eventual consistency) [2]. Это обеспечивает высокую доступность, гарантируя, что в отсутствии изменений данных, через какой-то промежуток времени после последнего обновления, т.е. в конечном счёте, все запросы будут возвращать последнее обновлённое значение. Например, обновлённая DNS-запись распространится по серверам согласно настройкам интервалов кэширования, в результате чего в конечном счёте все клиенты увидят обновление, хотя и не в то же мгновение. Таким образом, eventual consistency гарантирует асинхронное применение изменений с некоторой задержкой времени [3].
Но главной проблемой асинхронного обмена сообщениями является отсутствие каких-либо гарантий для потребителей относительно логического порядка получения событий от производителей. Например, сообщение об оплате заказа получено перед сообщением о новом заказе, что вызовет попытку обработки как будто не существующего объекта. Это можно решить, сохранив сообщение об оплате и повторно обработать его после получения и обработки сообщения о новом заказе. Реализовать такой подход можно с помощью обмена сообщениями или платформы обработки событий с разделением системы и базы данных (кэша) для отслеживания состояния обработки объектов, а также через приложения Apache Kafka Streams. Почему именно это является наиболее простым, легким в реализации и масштабируемым решением, мы рассмотрим далее.
Как Kafka Streams обеспечивает конечную согласованность распределенных микросервисов
Kafka Streams API — это клиентская библиотека для разработки приложений, обрабатывающих записи из топиков в Apache Kafka. Приложение Kafka Streams обрабатывает потоки данных (записи) через топологии процессоров из топиков, хранилищ состояний и узлов процессора. Приложение Kafka Streams потребляет и создает сообщения, которые постоянно хранятся в топиках и хранилищах состояний. Потоки Kafka можно масштабировать, разбивая топики так, чтобы несколько задач и потоков могли обрабатывать данные параллельно, в т.ч. с отслеживанием состояния (stateful), когда записи обрабатываются на основе их исторических состояний. Раздел топика обрабатывается выделенной задачей или потоком. Алгоритм назначения разделов Kafka Streams API гарантирует, что записи с одним и тем же первичным ключом обрабатываются последовательно, а хранилище состояний для раздела используется исключительно назначенной задачей или потоком. Записи с одним и тем же первичным ключом гарантированно попадают в один и тот же раздел, что позволяет обрабатывать их «последовательно» по времени события в Kafka Streams.
Apache Kafka для инженеров данных
Код курса
DEVKI
Ближайшая дата курса
25 июня, 2025
Продолжительность
24 ак.часов
Стоимость обучения
72 000 руб.
Таким образом, Kafka Streams отлично походит для реализации конечной согласованности распределенных микросервисных систем, дополнительно обеспечивая отказоустойчивость, масштабируемость и производительность [1]:
- когда сообщение создается в топике, оно сохраняется в Apache Kafka и может быть гарантированно получено потребителями хотя бы один раз. Это позволяет отделить сервисы-продюсерам, которые создают сообщения, от сервисов-потребителей, которые считывают сообщения, не беспокоясь о сбое потребителя и повторной отправке сообщения.
- сервисы могут обрабатывать сообщения из разных топиков параллельно;
- хранилище состояний, локальное для раздела топика и назначенных ему задач/потоков, позволяет сохранять и отслеживать состояния сообщений по первичному ключу для обработки новых сообщений или повторной обработки предыдущих неудачных сообщений. Такая локализация данных не вызывает сетевых задержек из-за отсутствия внешней СУБД или кэша.
- гарантия последовательной обработки по времени события для сообщений с одним и тем же первичным ключом обеспечивает сериализованный уровень изоляции как в ACID-транзакциях;
- простота разработки обеспечивается мощным API Kafka Streams и наличием множества готовых функций потоковой аналитики больших данных;
- за отказоустойчивость промышленного уровня и отказоустойчивость базовой платформы обмена сообщениями отвечает надежная Apache Kafka.
Именно поэтому разработчики международной финтех-компании BlackRock, о которых мы рассказывали вчера на примере обеспечения расширенной безопасности Apache Kafka, использовали API Kafka Streams для своей веб-платформы управления ликвидностью, одобренной крупными банками и корпорациями по управлению активами. Приложение Cachematrix Cloud Connector для портала Cachematrix Liquidity Trading Portal представляет собой сервис «Интеграция как услуга» в реальном времени, соединяя разные внешние банковские системы и системы Transfer Agent (TA) с мультитенантным порталом Cachematrix. В качестве брокера сообщений и платформы потоковой передачи собыйтий используется Apache Kafka. А необходимые функции сохранения сообщений и их stateful-обработки реализованы с помощью Kafka Streams API, гарантируя конечную согласованность с высокой отказоустойчивостью, стабильностью и производительностью [1]. Читайте в нашей новой статье, как с помощью Apache Kafka можно реализовать архитектурный шаблон с разделением ответственности CQRS.
Администрирование кластера Kafka
Код курса
KAFKA
Ближайшая дата курса
14 апреля, 2025
Продолжительность
24 ак.часов
Стоимость обучения
72 000 руб.
Узнайте все тонкости разработки распределенных приложений потоковой аналитики больших данных и администрирования кластеров Apache Kafka на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

