Вчера мы упоминали, как долгожданный KIP-500, реализованный в марте 2021 года, позволяет не только отказаться от Zookeeper в кластере Apache Kafka, но и снимает ограничение числа разделов, чтобы масштабировать брокеры практически до бесконечности. Однако, не все так просто: читайте далее, какие важные функции еще не поддерживаются в этом экспериментальном режиме и почему сами разработчики из Confluent пока не рекомендуют запускать Quorum Controller в высоконагруженном production.
Восстанавливайте кластер в разы быстрее вместе с Quorum Controller
Неограниченное масштабирование кластера путем добавления новых разделов, которое обещает обновление KIP-500, реализованное с марта 2021 года в Apache Kafka 2.8 – это не единственный плюс долгожданного отказа от Zookeeper. Также новый Quorum Controller использует новый протокол KRaft (Kafka Raft) c архитектурой, управляемая событиями, для обеспечения точной репликации метаданных в кворуме.
Контроллер кворума хранит свое состояние, используя событийную модель хранилища, которая гарантирует, что внутренние конечные автоматы всегда могут быть точно воссозданы. Журнал событий, используемый для хранения этого состояния (раздел метаданных), периодически сокращается с помощью моментальных снимков (snapshot’ов), чтобы предотвратить бесконечный рост журнала. Остальные контроллеры кворума следуют за активным контроллером, отвечая на события, которые он создает и сохраняет в своем журнале. Поэтому если один узел приостанавливается, он может быстро отследить любые пропущенные им события, обратившись к журналу при повторном присоединении. Это значительно уменьшает окно недоступности, улучшая время восстановления системы в наихудшем случае.
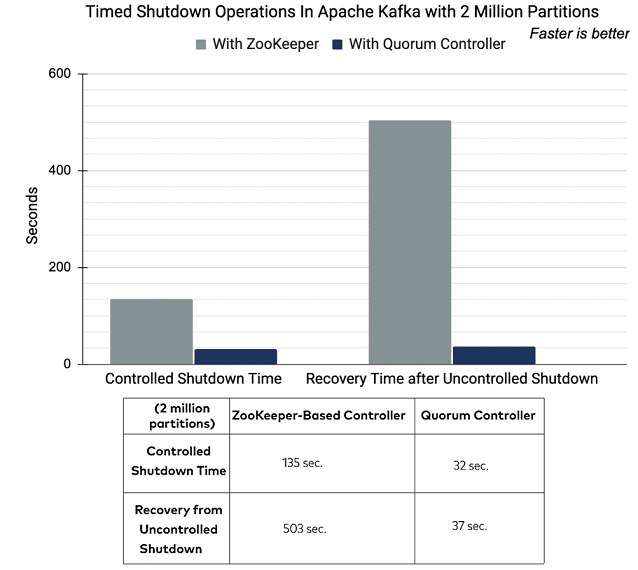
Кроме того, поскольку синхронизация метаданных выполняется в рамках самой Kafka, без привлечения стороннего сервиса, то восстановление после отказа происходит гораздо быстрее. Например, в случае контролируемого завершения работы узла в кластере на 2 миллиона разделов Quorum Controller обеспечил восстановление в 4,2 раза быстрее Zookeeper. А при неконтролируемом отказе цифры впечатляют еще больше [1].
Однако, несмотря на эти и другие преимущества, режим метаданных KRaft с внутренним Quorum Controller вместо Zookeeper не зря называется экспериментальным и пока рекомендуется только для тестирования в релизе Kafka 2.8. Он не поддерживает ряд важных функций, о чем мы поговорим далее.
Что не так в новой Apache Kafka без Zookeeper: 7 отсутствующих функций
Итак, сами разработчики Confluent подчеркивают отсутствие в этом раннем релизе следующих важных функций, что ограничивает использование Kafka 2.8 в production [2]:
- создание или загрузка снимков метаданных – Kafka Raft Snapshot (KIP-630), что означает увеличение времени перезапуска брокера по мере роста данных;
- функции обеспечения информационной безопасности, включая настройку авторизатора, ACL-списки, SCRAM, токены делегирования и пр.;
- поддержка транзакций и строго однократной семантики доставки сообщений (exactly once);
- добавление разделов в существующий топик;
- переназначение разделов;
- поддержка некоторых конфигураций, таких как включение неясного выбора лидера по умолчанию или динамическое изменение конечных точек брокера;
- поддержка JBOD (Just a bunch of disks) – дисковый массив, в котором единое логическое пространство последовательно распределено по жёстким дискам различной ёмкости и скорости. Это JBOD-массив обеспечивает легкое расширение, снижает нагрузку на ЦП и обладает повышенной надежностью, позволяя при отказе одного диска восстановить файлы на остальных, если ни один из их фрагментов не принадлежит повреждённому диску [3]. По сравнению с RAID-массивами, JBOD гораздо экономичнее. Однако, он не рекомендуется для Kafka, т.к. в нем отсутствуют некоторые важные функции. В частности, JBOD в Kafka не предоставляет инструменты управления для переназначения реплик между дисками одного и того же брокера, а также автоматическое перераспределение нагрузки между дисками [4].
Все это существенно ограничивает применение новой Apache Kafka в реальных высоконагруженных Big Data системах потоковой обработки событий. Однако, уже сейчас можно протестировать этот релиз с KIP-500, чтобы понять преимущества отказа от Zookeeper и другие возможности, развивающие фишки предыдущего релиза 2.7. О том, какие инструменты пригодятся администратору Кафка-кластера для мониторинга и управления, читайте в нашей новой статье. Что еще нового, кроме KIP-500, вас ожидает в релизе Apache Kafka 2.8.0, читайте здесь.
Администрирование кластера Kafka
Код курса
KAFKA
Ближайшая дата курса
15 сентября, 2025
Продолжительность
24 ак.часов
Стоимость обучения
72 000
Научиться разрабатывать распределенные приложения потоковой аналитики больших данных и администрировать кластер Apache Kafka, в т.ч. без Zookeeper, вам помогут специализированные курсы в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники
- https://www.confluent.io/blog/kafka-without-zookeeper-a-sneak-peek/
- https://github.com/apache/kafka/blob/6d1d68617ecd023b787f54aafc24a4232663428d/config/kraft/README.md
- https://ru.wikipedia.org/wiki/JBOD
- https://cwiki.apache.org/confluence/display/KAFKA/KIP-112%3A+Handle+disk+failure+for+JBOD