
Продолжая разговор про Apache Zeppelin, сегодня рассмотрим, как на его основе ведущий разработчик отечественных Big Data решений, компания «Аренадата Софтвер», построила самообслуживаемый сервис (self-service) Data Science и BI-аналитики – Arenadata Analytic Workspace. Читайте далее, как развернуть «с нуля» рабочее место дата-аналитика, где место этого программного решения в конвейере DataOps и при...

В этой статье мы рассмотрим, что такое Apache Zeppelin, как он полезен для интерактивной аналитики и визуализации больших данных (Big Data), а также чем этот инструмент отличается от популярного среди Data Scientist’ов и Python-разработчиков Jupyter Notebook. Что такое Apache Zeppelin и чем он полезен Data Scientist’у Начнем с определения: Apache...
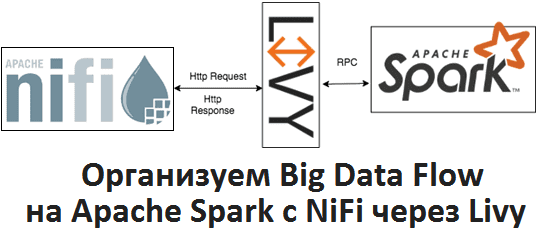
Apache Livy полезен не только при организации конвейеров обработки больших данных (Big Data pipelines) на Spark и Airflow, о чем мы рассказывали здесь. Сегодня рассмотрим, как организовать запланированный запуск пакетных Spark-заданий из Apache NiFi через REST-API Livy, с какими проблемами можно при этом столкнуться и что поможет их решить. Что...

Продолжая разговор про Apache Livy, сегодня мы сравним этот REST API для Spark c другой популярной Big Data системой планирования рабочих процессов для управления заданиями Hadoop – Oozie. Читайте в нашей статье, что такое Apache Oozie, чем он похож на Livy и в чем между ними разница, а также когда...

Сегодня мы расскажем о важности прикладного бизнес-анализа в проектах Big Data, включая цифровизацию частного бизнеса и государственных предприятий. Читайте в нашей статье, как области знаний профессионального руководства по бизнес-анализу BABOK®Guide соответствуют типовым этапам внедрения технологий больших данных в корпоративную деятельность, и почему цифровая трансформация любой компании – это, прежде всего,...

Продолжая разговор про обучение Spark на реальных примерах, сегодня мы рассмотрим, как работает этот Big Data фреймворк на Kubernetes, популярной DevOps-платформе автоматизированного управления контейнеризированными приложениями. Читайте в нашей статье, как запустить приложение Apache Spark в кластере Kubernetes (K8s) с помощью submit-скрипта и оператора, а также при чем здесь Docker-образ. Запуск...

Вчера мы рассказывали об основных сценариях запуска Apache Spark на Kubernetes и преимуществах этого варианта развертывания популярного Big Data фреймворка на DevOps-платформе автоматизированного управления контейнеризированными приложениями. Сегодня поговорим про обратную сторону всех этих преимуществ: читайте в нашей статье, каковы основные ограничения и главные недостатки запуска Apache Spark на Kubernetes (K8s)....

Чтобы сделать курсы по Spark еще более интересными и полезными, сегодня мы расскажем, зачем этот Big Data фреймворк разворачивают на Kubernetes (K8s) – платформе автоматизации развёртывания, масштабирования и управления контейнеризированными приложениями. Читайте в нашей статье про основные варианты использования и достоинства этого подхода к администрированию и эксплуатации Apache Spark. Зачем...

Недавно мы разбирали особенности интеграции Apache Kudu и Spark. В продолжение этой темы, сегодня поговорим про некоторые особенности выполнения SQL-операций с данными при интеграции этих Big Data фреймворков, а также рассмотрим пример записи данных в мульти-мастерный кластер Куду через Impala с помощью API Data Frame на PySpark. Что приносит Kudu...

Сегодня мы рассмотрим практический кейс использования Apache Kudu с Kafka, Storm и Cloudera Impala в крупной китайской корпорации, которая производит смартфоны. На базе этих Big Data технологий компания Xiaomi построила собственную платформу для BI-аналитики больших данных и генерации отчетности в реальном времени. История Kudu-проекта в Xiaomi Корпорация Xiaomi начала использовать...