 1206
1206 
Сегодня мы рассмотрим практический кейс использования Apache Kudu с Kafka, Storm и Cloudera Impala в крупной китайской корпорации, которая производит смартфоны. На базе этих Big Data технологий компания Xiaomi построила собственную платформу для BI-аналитики больших данных и генерации отчетности в реальном времени.
История Kudu-проекта в Xiaomi
Корпорация Xiaomi начала использовать Kudu еще в 2016 году, вместе с Cloudera Impala, которая на тот момент еще находилась в стадии инкубации open-source проектов фонда Apache Software Foundation [1]. До применения Kudu архитектура аналитической Big Data системы выглядела следующим образом [2]:
- данные из различных источников (более 20 миллиардов записей в день) сохранялись в HBase и в отдельной базе файлов последовательности в формате Sequence;
- далее эти данные обрабатывались с помощью Apache Hive, классического Hadoop MapReduce и Spark, разделяясь на 2 потока согласно лямбда-архитектуре, о которой мы рассказывали здесь;
- Impala, как средство класса SQL-on-Hadoop, использовалось для интерактивного доступа к данным, хранящимся в HDFS в формате Parquet;
- исторические данные из HBase напрямую передавались в конечные BI-сервисы.
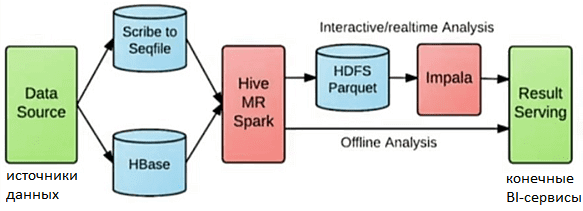
Основными недостатками этой BI-системы были низкая скорость и высокая сложность обработки данных. На практике для получения результатов анализа требовалось от 1 часа до целого дня, что неприемлемо для современного бизнеса. Более того, порядок поступления логов в хранилище не соответствовал логической последовательности происхождения событий. Из-за этого требовалось считывать данные за предыдущие периоды (2-3 дня), чтобы получить все события одного дня. Поэтому было принято решение о построении ETL-конвейера обработки данных (data pipeline), который позволит быстрее и проще отслеживать и анализировать данные о событиях RPC-вызовов мобильных приложений и других серверных служб. Для этого в Xiaomi был внедрены Apache Kudu, Kafka и Storm, обеспечивающие быструю аналитику больших данных в near real-time режиме [2].
Результаты внедрения BI-системы аналитики Big Data
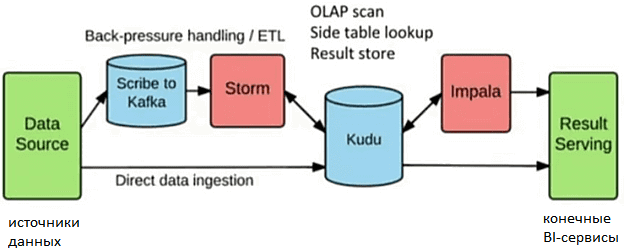
Новая архитектура Bi-системы аналитики больших данных о событиях RPC-вызовов мобильных приложений и других серверных служб в Xiaomi построена следующим образом [2]:
- данные из различных источников агрегируются в топиках Apache Kafka;
- приложения на базе Apache Storm отвечают за потоковую обработку этих данных в реальном времени;
- Apache Kudu выполняет роль хранилища для исходных данных из источников и результатов OLAP-сканирования обработанных данных из Storm-приложений;
- Impala применяется для интерактивного доступа к данным в Kudu через инструментарий SQL-запросов;
- конечные BI-сервисы принимают данные как через Impala, так и непосредственно через прямой доступ к Kudu.
Обновленная архитектура BI-системы аналитики больших данных на базе Apache Kudu, Kafka и Storm показала успешные результаты уже в первые полгода production-использования в Xiaomi позволила улучшить ключевые показатели надежности и производительности [1].
Благодаря Kudu канал обработки данных существенно упростился, в т.ч. за счет поддержки операций произвольного чтения и записи. Также стал возможным интерактивный анализ данных непосредственно в Kudu с максимальной временной задержкой не более 10 секунд [2].
Видео по этому кейсу было представлено в докладе Майка Перси, software-инженера компании Cloudera на ежегодной конференции Spark Summit Europe в 2016 году. Сам доклад посвящен применению Apache Kudu и Spark SQL для быстрой аналитики быстро меняющихся данных (Apache Kudu and Spark SQL for Fast Analytics on Fast Data) [3]. Некоторые аспекты интеграции Apache Kudu и Spark SQL мы уже разбирали здесь. Завтра мы рассмотрим еще один пример практического использования этих технологий для расширенной аналитики больших данных, разобрав кейс банка «Открытие». А в другой статье мы рассмотрим доклад сотрудника Cloudera подробнее, фокусируясь на ключевых преимуществах, которые Kudu приносит в Spark.
Как использовать Apache Kudu и другие компоненты экосистемы Hadoop на практике для аналитики больших данных в проектах цифровизации своего бизнеса, вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

