 1335
1335 
Содержание
Продолжая разговор про Apache Livy, сегодня мы сравним этот REST API для Spark c другой популярной Big Data системой планирования рабочих процессов для управления заданиями Hadoop – Oozie. Читайте в нашей статье, что такое Apache Oozie, чем он похож на Livy и в чем между ними разница, а также когда и почему стоит выбрать тот или иной инструмент.
Что такое Apache Oozie и как это работает
Apache Oozie – это серверная система планирования выполнения рабочих процессов и повторяющихся задач в экосистеме Hadoop. Как и в Apache Livy, рабочие процессы в Oozie представлены в виде DAG-цепочки (Directed Acyclic Graph, ориентированный ациклический граф). Ози поддерживает запуск задач Hadoop MapReduce, Apache Hive, Pig, Sqoop, Spark, операций HDFS, UNIX Shell, SSH и электронной почты, а также может быть расширен для поддержки дополнительных действий. Задачи могут быть настроены для регулярного выполнения или разово при возникновении некоторого события. Сам Oozie реализован в виде веб-приложения на Java, которое выполняется в контейнере Java-сервлетов и распространяется под лицензией Apache 2.0. [1].
Oozie позволяет Hadoop-администраторам создавать сложные преобразования данных, объединяя обработку разнообразных задач и потоков работ. Это улучшает контролируемость сложных заданий и облегчает их регулярное выполнение. Примечательно, что инфраструктура Oozie использует собственную реализацию стека Hadoop, которая интегрирована с обычным. Например, Ози инициирует выполнение потока работ, а сами задачи осуществляются с помощью Hadoop, что позволяет использовать существующие в хадуп механизмы для выравнивания нагрузки, переключения при отказе и пр. При запуске задачи Oozie предоставляет ей уникальный HTTP URL для обратного вызова, а после ее завершения отсылает по этому URL-адресу соответствующее уведомление. Если задача не может выполнить обратный вызов, Oozie опрашивает ее на предмет ее завершения. Особенности выполнения потоков работ в Oozie задаются параметрами, которые позволяют, например, выполнять одновременно несколько идентичных заданий DAG-цепочки. Потоки работ Ози представлены в виде XML-файла, описывающего DAG, на языке HDPL (Hadoop Process Definition Language). Отправка заданий выполняется через CLI-интерфейс. Командная строка взаимодействует с Oozie-сервером по REST-протоколу. Для сохранения состояния используется реляционная СУБД [2].
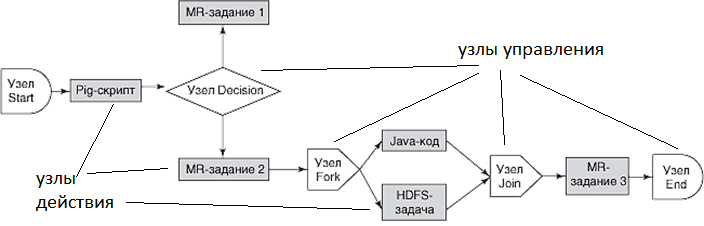
Oozie целесообразно использовать, когда поток обработки включает несколько шагов, каждый из которых зависит от предыдущего. Например, запуск скрипта для проверки наличия ожидаемых входных данных перед их фактической обработкой. При запуске Spark-задания Oozie сначала запускает контейнер Oozie-launcher на центральном узле кластера, который далее и запускает собственно Spark Job. Далее Oozie использует этот контейнер для отслеживания и ожидания обработки задания Spark [3].
5 главных отличий Apache Livy от Oozie при работе со Spark
Напомним, Apache Livy – это REST-интерфейс для кластера Spark, который позволяет запускать и отслеживать отдельные задания Spark, напрямую используя фрагменты кода Spark или предварительно скомпилированные jar-файлы. Livy можно использовать для запуска «асинхронных» заданий Spark, которые могут быть запущены в любое время, и не требуют обязательного отклика. Так можно запустить Spark-задания через Livy и продолжить работу, не дожидаясь ответа о выполнении, например, в следующих случаях [3]:
- задания по составлению отчетов о качестве данных, включая такую статистику, как количество строк, столбцов и пр, которая будет записываться в базу данных, чтобы затем использоваться при создании панели мониторинга;
- конечные задания конвейера обработки Big Data (data pipeline), включая подготовку и экспорт данных во внешнюю систему.
Также, по аналогии с Ози, Apache Livy можно применять для оркестрации рабочих процессов с опросом API для ответа о состоянии задания. Таким образом, ключевым достоинством Oozie, отличающими его от Apache Livy, является его универсальность, позволяющая работать не только со Spark, но и использоваться для управления широким спектром заданий Hadoop, (Pig, Hive, Sqoop, и пр.), обеспечивая координацию и управление рабочим процессом. Обратной стороной этого преимущества являются следующие недостатки, которых лишен Apache Livy [3]:
- Ози использует контейнер oozie-launcher для каждой запускаемой задачи. Когда несколько заданий запускаются одновременно, есть вероятность, что в кластере запущены все oozie-launcher, но ни одно из заданий Spark. Пока все эти контейнеры oozie-launcher ожидают завершения своих соответствующих заданий Spark, фактически ни одно из них не запущено. Это означает, что кластер заполнен oozie-launcher’ами, но практическая работа не выполняется. Apache Livy не загружает кластер подобными контейнерами по причине их отсутствия в самой технологии.
- Поскольку для каждого типа задач (Pig, Hive, Sqoop, Spark и пр.) в Oozie требуются собственные jar-файлы и версии библиотек, это может привести к тому, что разные несовместимые версии jar-библиотеки могут вызывать сбои в заданиях. Проблема решается проверкой совместимости и соответствующими настройками. Как правило, в Apache Livy подобные инциденты не возникают поскольку он заранее связан с необходимыми jar-файлами, и достаточно просто правильно настроить Spark в кластере.
- Поскольку при обновлении неизбежно возникают конфликты версий jar, осложняется процесс миграции между версиями Spark и их обновление. В Apache Livy миграция между версиями Spark выполняется автоматически: если задание выполняется в более новой версии Spark, Livy просто запустит его.
- Наконец, в Oozie нужно писать потоки работ (workflow) для запуска даже самых простых заданий. В Livy не требуется разрабатывать дополнительные workflow-файлы и свойства для запуска заданий, а используется только простой HTTP-интерфейс.
Тем не менее, подчеркнем, что, в отличие от Ози, Apache Livy не является полноценной системой управления потоками работ, а используется исключительно для запуска и отслеживания отдельных заданий Spark. Однако, вокруг Livy может быть построена система управления DAG-цепочками [3]. Завтра мы продолжим разбираться с Apache Livy и рассмотрим, как это REST API используется при совместной работе Spark с NiFi.
А технические подробности настройки и эксплуатации Apache Spark с Livy и другими компонентами экосистемы Hadoop для аналитики больших данных в проектах цифровизации своего бизнеса, а также государственных и муниципальных предприятий, вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Построение эффективных конвейеров обработки данных с Apache Airflow и Arenadata Hadoop
- Анализ данных с Apache Spark
Источники

