 287
287 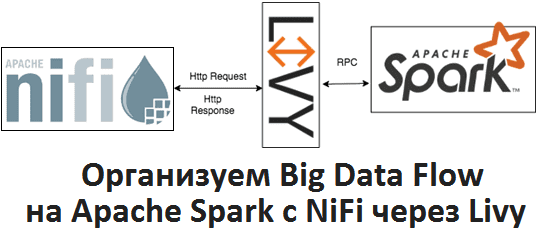
Содержание
Apache Livy полезен не только при организации конвейеров обработки больших данных (Big Data pipelines) на Spark и Airflow, о чем мы рассказывали здесь. Сегодня рассмотрим, как организовать запланированный запуск пакетных Spark-заданий из Apache NiFi через REST-API Livy, с какими проблемами можно при этом столкнуться и что поможет их решить.
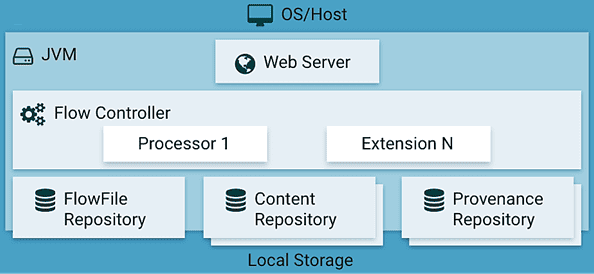
Что внутри Apache NiFi или как связаны потоковые файлы, процессоры и контроллеры
Напомним, Apache NiFi – это популярный инструмент стека Big Data для маршрутизации потоков данных (Data Flow) и организации ETL-процессов. Его дополнительным преимуществом является наличие наглядного веб-GUI, в котором конечные пользователи могут добавлять новых пунктов назначения и источники данных с возможностью воспроизведения в любое время. Основными понятиями NiFi являются следующие [1]:
- файл потока данных (FlowFile) – единый фрагмент информации из заголовка и содержимого, подобно HTTP-запросу. Атрибуты в заголовке описывают метаданные содержимого: тип данных, время создания и уникальный идентификатор (uuid), а также пользовательские свойства. Содержимое потокового файла — это просто необработанные данные, которые передаются: простой текст, JSON, байт-коды и пр.
- Обработчик или процессор потокового файла (FlowFile Processor) – отдельный фрагмент кода для выполнения конкретной операции с потоковыми файлами: создание, чтение/запись и изменение содержимого или атрибутов, а также маршрутизация.
- Контроллер потока (Flow Controller) для поддержки знаний о соединении процессоров, управления потоками и их маршрутизации. Flow Controller выступает в качестве посредника, облегчающего обмен потоковыми файлами между процессорами.
- Соединение (Connection), которое обеспечивает подключение и передачу потокового файла между процессорами, помещая его в очередь и передавая далее по цепочке.
- Группа процессоров (Process Group)для организации множества компонентов в единую логическую структуру.
- Репозиторий потоковых файлов (FlowFile Repository), где хранится информация (метаданные) о каждом существующем FlowFile в Apache NiFi.
- Репозиторий содержимого (Content Repository), где находится содержимое всех потоковых файлов, т.е. сами передаваемые данные.
- Репозиторий происхождения (Provenance Repository), который хранит историю о каждом потоковом файле и операциях с ним (создание, изменение и пр.).
- Веб-сервер (Web Server), который предоставляет веб-интерфейс и REST API.
Поскольку обе рассматриваемые Big Data системы (Apache Spark и NiFi) имеют REST API, то целесообразно организовать их взаимодействие через него, которым и является Apache Livy. Как это реализуется на практике, мы рассмотрим далее.
Запуск Spark-заданий из NiFi через Apache Livy: практический пример Data Flow
Apache NiFi по умолчанию включает множество процессоров, в т.ч. ExecuteSparkInteractive для запуска интерактивных сессий в Spark-кластере через контроллер сессии Livy (LivySessionController) [2]. Напомним, интерактивная сессия (Interactive Session) – это один из 2-х возможных режимов взаимодействия с интерфейсом Livy, который запускает сеанс для отправки операторов. При наличии ресурсов они будут выполнены, и можно будет получить выходные данные. Этот режим подходит для экспериментов с данными или для быстрых вычислений [3].
Процессор ExecuteSparkInteractive отправляет Spark-задания в Livy, выполняя код, предоставленный в свойстве или в содержимом потокового файла. Однако, на практике этого недостаточно, чтобы запланировать запуск собственных пакетных Spark-заданий из Nifi, включая различные действия в зависимости от результата их выполнения, успех (success) или неудача (failure). Для этого можно использовать ExecuteProcess, который запускает команду spark-submit. Сначала следует воспользоваться процессором GenerateFlowFile для планирования, а затем подключить его к процессору ExecuteProcess, который и запустит команду spark-submit. Однако, этот use case является не столько вариантом управления DataFlow, а представляет собой диспетчирование потока работ, с чем лучше справятся специально предназначенные для этого инструменты Big Data, например, Apache Airflow или Oozie [4]. Что общего у Apache Livy с Oozie и чем они отличаются, мы разбирали здесь.
Возвращаясь к запуску Spark-заданий из NiFi через Livy, рассмотрим типовой Data Flow, где чтение файлов из папки выполняется с помощью процессора GetFile. Он подключается к процессору ExecuteSparkInteractive через отношение «успех» [2].
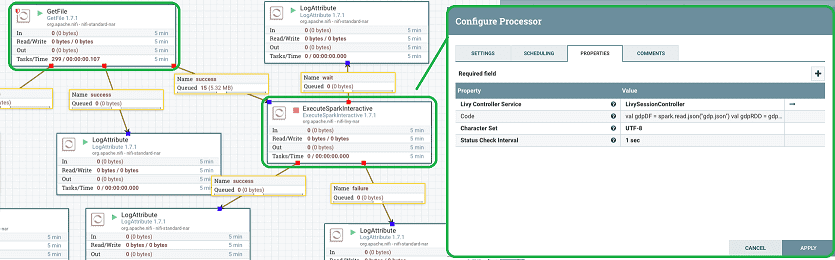
В свойстве процессора «Код» (Code) размещаются инструкции, которые будут выполняться в интерактивной оболочке Spark (shell). Для рассматриваемого примера по чтению json-файлов и возвращению количества записей используется следующие строки:
val gdpDF = spark.read.json («gdp.json»)
val gdpRDD = gdpDF.rdd
gdpRDD.count ()
При конфигурировании процессора ExecuteSparkInteractive следует также настроить параметры LivySessionController: хост (Host), порт (Port) и тип сеанса (Session Type). Новые открытые сеансы отобразятся в Livy GUI. В рассматриваемом примере открываются 2 сеанса PySpark, т.к. размер пула сеансов равен 2. Можно еще проверить журналы сеансов Livy на предмет вывода [2].
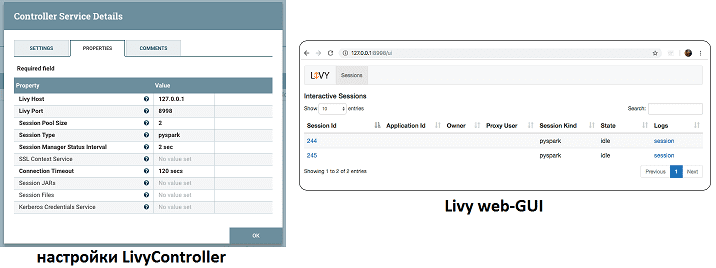
Таким образом, функциональные возможности Apache NiFi отлично позволяют работать со Spark через Livy в рамках наглядного веб-GUI. Завтра мы продолжим разговор про прикладную работу с Apache Spark и рассмотрим, что такое Zeppelin и как это помогает в аналитике больших данных и разработке Спарк-приложений.
А как на практике использовать Apache NiFi со Spark, Livy и другими компонентами экосистемы Hadoop для аналитики больших данных в проектах цифровизации своего бизнеса, а также государственных и муниципальных предприятий, вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Построение эффективных конвейеров обработки данных с Apache Airflow и Arenadata Hadoop
- Анализ данных с Apache Spark
- Эксплуатация Apache NIFI
Источники
- https://habr.com/ru/company/rostelecom/blog/432166/
- https://medium.com/@evanescence1106/in-this-article-we-will-use-apache-nifi-to-schedule-batch-jobs-in-spark-cluster-abb41d112042
- https://www.statworx.com/de/blog/access-your-spark-cluster-from-everywhere-with-apache-livy/
- https://stackoverflow.com/questions/51392442/apache-nifi-submitting-spark-batch-jobs-through-apache-livy

