
Продолжая разговор про Apache Zeppelin, сегодня рассмотрим, как на его основе ведущий разработчик отечественных Big Data решений, компания «Аренадата Софтвер», построила самообслуживаемый сервис (self-service) Data Science и BI-аналитики – Arenadata Analytic Workspace. Читайте далее, как развернуть «с нуля» рабочее место дата-аналитика, где место этого программного решения в конвейере DataOps и при чем здесь цифровизация.
Аналитика больших данных, DataOps и цифровизация: модные слова или необходимость
Напомним, DataOps (от Data Operations) – это концепция непрерывной интеграции данных между процессами, командами и системами для повышения эффективности корпоративного управления за счет распределенного сбора, централизованной аналитики и гибкой политики доступа к информации с учетом ее конфиденциальности, ограничений на использование и соблюдения целостности. Данный термин впервые прозвучал в 2015 году в контексте демократизации Big Data. С тех пор он приобретает все большую популярность благодаря растущему тренду на цифровую трансформацию бизнеса и data-driven управление [1]. Таким образом, цифровизация выступает дополнительным драйвером развития концепции DataOps, требуя непрерывного конвейера операций по работе с данными, включая сбор, агрегацию, очистку, преобразование, обогащение, интеграцию, фильтрацию и предоставление результатов по требованию уполномоченных пользователей в нужном виде (графики, таблицы и прочие виды визуализации). Причем в идеальном случае это должно выполняться в каждом бизнес-процессе компании, обеспечивая сквозное и прозрачное управление на основе актуальных данных.
В 2018 году аналитическое агентство Gartner включило DataOps в свой ежегодный список наиболее перспективных технологий в категории «Управление данными» (Data Management), представив его в стадии роста ажиотажа на своем графике технологической зрелости (Hype Cycle). Прогнозируется, что на плато продуктивности концепция DataOps выйдет через 5-10 лет, т.е. к началу 2030-хх гг. Gartner позиционирует DataOps не как чистую технологию, строгий стандарт или жесткую догму, а обозначают этим понятием набор связанных практик по представлению и обновлению данных для удовлетворения потребностей корпоративных потребителей [2].
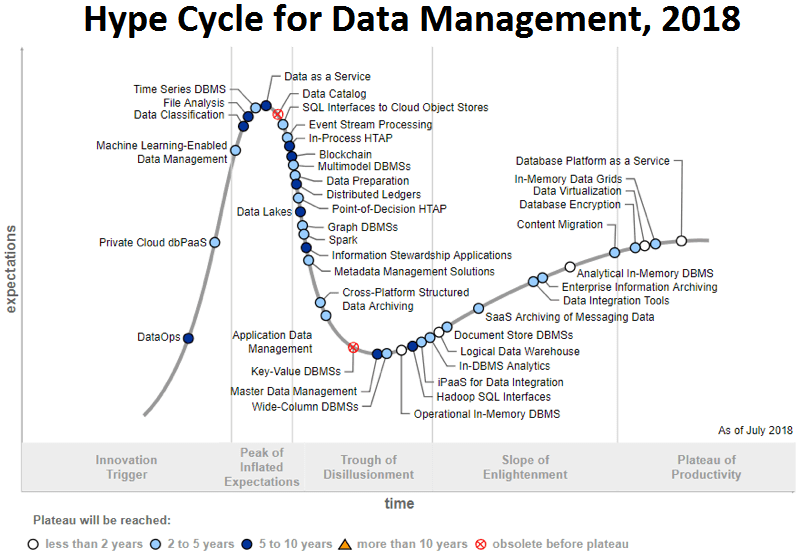
С технологической точки зрения DataOps представляет собой конвейер взаимосвязанных операций с данными, от сбора и агрегации до визализации результатов преобразований, которые нужны для получения ценных бизнес-выводов (инсайтов). Реализация каждого этапа выполняется с использованием одной или сразу нескольких технологий Big Data, среди которых могут быть как проприетарные, так и open-source решения [3].
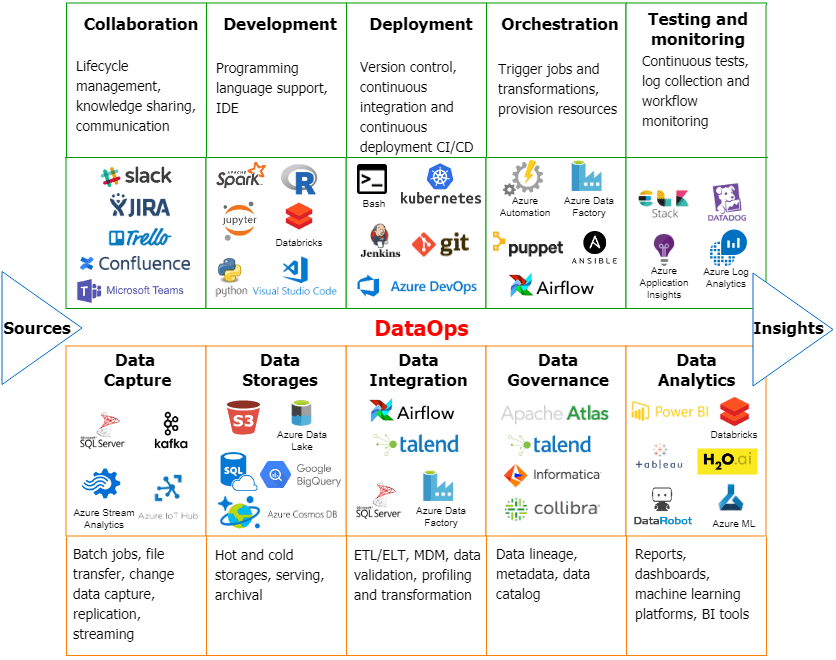
С точки зрения конечного пользователя, аналитика больших данных занимает конечное место в этом конвейере обработки информации (data pipeline), предоставляя полезные прогнозы и рекомендации в визуальном интерфейсе BI-систем и интерактивных дэшбордов. При этом, в отличие от BI-систем прошлого десятилетия, сегодня Data Analyst работает не только с витринами данных реляционного КХД через SQL-запросы, а активно использует алгоритмы машинного обучения (Machine Learning) и прочие методы искусственного интеллекта, встроенные в современные Data Science/BI-сервисы. Как это реализовано в отечественном Big Data продукте, Arenadata Analytic Workspace, мы рассмотрим далее.
Arenadata Analytic Workspace: как это устроено и чем полезно бизнесу
Arenadata Analytic Workspace – это рабочее место аналитика Big Data в виде самообслуживаемого сервиса Data Science и BI. Как и другие продукты компании Arenadata, это решение основано на open-source технологиях, адаптированных к корпоративным потребностям, таких как интеграция со сторонними системами и разработка кастомных модулей Python [4].
О том, что такое self-service BI-аналитика больших данных, мы рассказывали здесь. Подчеркнем, что ключевыми достоинствами этого подхода считаются следующие [5]:
- сокращение времени поставки и подготовки данных для анализа;
- консолидация данных, кода и визуализации в одной системе;
- дополнение традиционных BI-систем средствами расширенной аналитики (Augmented Analytics), такими как алгоритмы машинного обучения (Machine Learning) и другие методы искусственного интеллекта, а также облачная обработка больших данных во внешних кластерах в рамках DaaS-сервисов;
- сокращение затрат на ИТ-инфраструктуру;
- снижение порога входа в аналитику больших данных;
- минимизация vendor-lock риска при использовании проприетарных BI-систем;
- защита данных, кода и визуализации результатов от несанкционированного доступа.
Реализацию всех этих преимуществ Arenadata Analytic Workspace выполнила на основе Apache Zeppelin – интерактивного веб-блокнота, который полностью соответствует концепции DataOps, поддерживая все этапы работы с данными в Data Science, от извлечения до визуализации, включая интерактивный анализ и совместное использование документов. Непрерывность data pipeline’а между различными бизнес-процессами обеспечивается за счет бесшовной интеграции с Apache Spark, Flink, Hadoop, множеством реляционных и NoSQL-СУБД (Cassandra, HBase, Hive, PostgreSQL, Elasticsearch, Google Big Query, Mysql, MariaDB, Redshift). Также, с помощью соответствующих интерпретаторов (плагинов) Zeppelin поддерживает разные языки программирования для Big Data: Python, PySpark, R, Scala и SQL. Таким образом, Apache Zeppelin отлично подходит для аналитики больших данных в экосистеме Hadoop, в т.ч. с помощью собственных Spark-приложений. А защита данных и кода от несанкционированного доступа достигается благодаря LDAP и управление разрешениями в многопользовательском режиме [6]. Подробнее о том, что такое Apache Zeppelin и чем он отличается от Jupyter Notebook, мы писали здесь.
Возвращаясь к DataOps и цифровизации, отметим, что Arenadata Analytic Workspace на базе Apache Zeppelin также поддерживает тренд на демократизацию данных и процедур работы с ними, в т.ч. операций по установке и конфигурированию рабочих ИТ-инструментов. В частности, установка, настройка, расширение и обновление Arenadata Analytic Workspace сводится к загрузке Docker-образа из репозитория разработчика и создании на его основе нового контейнера [7]. Это очень удобно и в полной мере соответствует принципам self-service подхода.
В заключение стоит сказать, что Arenadata Analytic Workspace – это не единственный self-service Data Science и BI-аналитики. В плани функциональных возможностей к нему наиболее близок продукт одного из самых крупных зарубежных вендоров Big Data решений – Cloudera Data Science Workbench. Что собой представляет эта платформа и чем она отличается от Arenadata Analytic Workspace, мы рассмотрим завтра.
А как внедрить самообслуживаемую аналитику больших данных и другие элементы DataOps в проекты цифровизации своего бизнеса, а также государственных и муниципальных предприятий, вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Аналитика больших данных для руководителей
- Построение эффективных конвейеров обработки данных с Apache Airflow и Arenadata Hadoop
- Анализ данных с Apache Spark
- Использование Apache Zeppelin
Источники
- https://www.osp.ru/os/2018/2/13054175
- https://www.gartner.com/en/newsroom/press-releases/2018-09-11-gartner-hype-cycle-for-data-management-positions-three-technologies-in-the-innovation-trigger-phase-in-2018
- https://www.valdas.blog/2019/04/17/data-ops
- https://arenadata.tech/support/arenadata-analytic-workspace/
- https://docs.arenadata.io/aaw/index.html
- https://docs.arenadata.io/aaw/Zeppelin/Overview.html
- https://docs.arenadata.io/aaw/admin/install.html

