
В продолжение вчерашней статьи по нашему новому курсу «Greenplum для инженеров данных», сегодня рассмотрим особенности индексации и сжатия данных в этой MPP-СУБД. Читайте далее, почему в Greenplum можно обойтись без индексов, когда выбирать RLE-сжатие вместо zlib, зачем сжимать рабочие файлы при выполнении SQL-запросов и что такое селективность индекса. ТОП-10 советов по...

Продвигая наш новый курс «Greenplum для инженеров данных», сегодня мы рассмотрим особенности организации таблиц в этой MPP-СУБД, типы данных и оптимальное расположение столбцов. Читайте далее, чем heap storage отличается от append-optimized, когда выбирать колоночную, а когда – строковую модель хранения данных для таблицы, почему BIGINT с TIMESTAMP следует размещать перед...

Продолжая разговор про обучение Apache Spark для инженеров данных на практических примерах, сегодня разберем, как организовать интеграцию этого Big Data фреймворка с MPP-СУБД Greenplum. В этой статье мы расскажем о коннекторе Greenplum-Spark, который позволяет эффективно связывать эти средства работы с большими данными, выстраивая аналитический конвейер их обработки (data pipeline). Типовые...

Говоря про практическое обучение Apache Spark для дата-инженеров, сегодня рассмотрим особенности разработки собственного коннектора для этого фреймворка на примере его интеграции с BI-системой Tableau. Читайте далее, как конвертировать Spark RDD в нужный формат и сделать свой коннектор удобным для пользователей. Интеграция Spark с внешними источниками данных через коннекторы Apache Spark...

Чтобы наглядно показать, как аналитика больших данных и машинное обучение помогают быстро решить актуальные бизнес-проблемы, сегодня мы рассмотрим кейс компании Леруа Мерлен. Читайте в нашей статье про нахождение аномалий в сведениях об остатках товара на складах и в магазинах с помощью моделей Machine Learning, а также про прикладное использование Apache...

Мы уже рассказывали про интеграцию Tarantool с Apache Kafka на примере Arenadata Grid. Сегодня рассмотрим, как интегрировать Кафка с MPP-СУБД Greenplum и каковы ограничения каждого из существующих способов. Читайте в сегодняшнем материале, что такое GPSS, PXF и при чем тут Docker-контейнер с коннектором Кафка для Arenadata DB. IoT и не...

Сегодня рассмотрим ключевые достоинства и недостатки резидентных СУБД для больших данных на примере Tarantool. Читайте в нашей статье про основные сценарии использования In-Memory Database (IMDB) в области Big Data с конкретными кейсами из реального бизнеса от Альфа-Банка, Аэрофлота, Тинькофф-Банка и Мегафона. Где и как используются In-Memory в Big Data: 4...

Вчера мы разбирали In-Memory СУБД на примере Tarantool. Сегодня поговорим про Arenadata Grid: что это такое, чем хороша эта база данных, каким образом она связана с Тарантул и чем от него отличается. Также рассмотрим, как Arenadata Grid интегрируется с внешними Big Data системами, в т.ч. основными компонентами инфраструктуры Apache Hadoop...
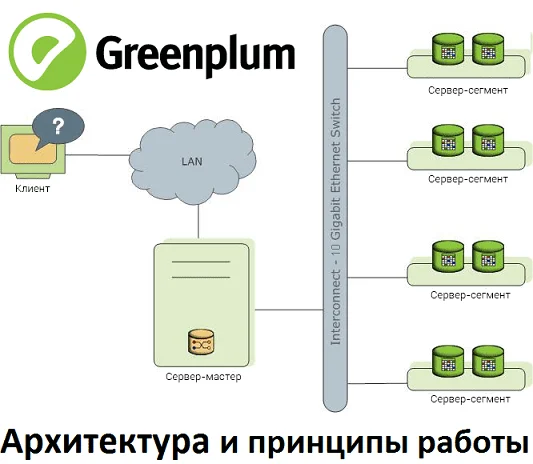
В этом материале рассмотрим реализацию массово-параллельной архитектуры для хранения и аналитической обработки больших данных на примере популярной Big Data СУБД Greenplum. Прочитав эту статью, вы поймете, почему MPP-базы потребляют много ресурсов и как связано число сегментов со скоростью работы кластера. MPP, Greenplum и PostgreSQL Напомним, СУБД Greenplum – это типичный представитель...

Сегодня поговорим про достоинства и недостатки массово-параллельной архитектуры для хранения и аналитической обработки больших данных, рассмотрев Greenplum и Arenadata DB. Читайте в нашей статье, что такое MPP-СУБД, где и как это применяется, чем полезны эти Big Data решения и с какими проблемами можно столкнуться при их практическом использовании. Что MPP-СУБД...