Продолжая разговор про обучение Apache Spark для инженеров данных на практических примерах, сегодня разберем, как организовать интеграцию этого Big Data фреймворка с MPP-СУБД Greenplum. В этой статье мы расскажем о коннекторе Greenplum-Spark, который позволяет эффективно связывать эти средства работы с большими данными, выстраивая аналитический конвейер их обработки (data pipeline).
Типовые сценарии интеграции Apache Spark с Greenplum
Напомним, Apache Spark позволяет быстро обрабатывать большие объемы данных, которые поступают из внешних источников, каких как топики Kafka, распределенные файловые системы (Hadoop HDFS или Amazon S3), а также СУБД, в частности, Greenplum (GP), которая лежит в основе отечественного Big Data решения Arenadata DB. Интеграция Спарк с внешними хранилищами организуется через специальные коннекторы в виде интерфейсов для одной из основных структур данных этого фреймворка — RDD (Resilient Distributed Dataset, надежная распределенная коллекция данных типа таблицы). Подробнее об этом мы рассказывали здесь.
Представим типовой pipeline, в котором преобразования над данными, хранящимися в Greenplum, выполняются с помощью Spark-приложений. Такой вариант использования имеет место, например, при необходимости совместить гибкость и масштабирование Apache Spark с надежностью MPP-подхода к хранению и аналитике больших данных Greenplum.
Greenplum для инженеров данных и аналитиков данных
Код курса
GPDE
Ближайшая дата курса
27 января, 2025
Продолжительность
24 ак.часов
Стоимость обучения
72 000 руб.
Наиболее популярными кейсами использования Greenplum-Spark Connector являются исследования больших данных и их интерактивная аналитика. Например, с помощью этого коннектора можно быстро загружать данные из GP в Spark, используя интерактивную оболочку этого фреймворка, исследовать массивы Big Data и визуализировать результаты. Кроме того, благодаря коннектору возможен доступ к библиотекам Спарк для обработки данных, включая Scala, Java, Python и R. Если Greenplum предоставляет интегрированную аналитику в единой горизонтально масштабируемой среде, то Спарк ускоряет обработку данных до режима реального времени за счет использования оперативной памяти. Наконец, еще одним распространенным примером применения коннектора Greenplum-Spark является построение ETL-процессов, когда дата-инженер строит конвейер загрузки\выгрузки в Greenplum поверх Spark [1].
Особенности и ограничения интеграции с помощью коннектора
До появления специального коннектора Greenplum-Spark интеграция между этими Big Data системами выполнялась через JDBC-драйвер Спарк для загрузки и выгрузки данных из MPP-СУБД. Ограничением этого решения является то, что такой JDBC-драйвер передает данные из кластера GP через главный узел, который является бутылочным горлышком всей системы и ограничивает ее производительность. Для устранения этих ограничений в 2018 году компания разработчик Greenplum, корпорация Pivotal Software, выпустила первую версию коннектора к Spark, который использует технологию параллельной передачи данных этой СУБД [1].
В октябре 2020 года вышел релиз Greenplum-Spark Connector 2.0, который включает следующие новые возможности [2]:
- сертифицирован по версиям драйверов Scala, Спарк и JDBC для GP выше 5.x, а также Spark 3, 2,4, 3.0, Scala 2.11 и 2.12, PostgreSQL JDBC-драйвер 42.2.14;
- упакован в файл .tar.gz, который включает лицензию open-source продукта, и файл JAR Connector, например, greenplum-connector-apache-spark-scala12-2.0.0.tar.gz
- тайм-аут подключения к серверу gpfdist по умолчанию теперь 5 минут вместо 30 секунд, что решает проблему истечения времени ожидания с исключением сериализации при записи агрегированных результатов в базу данных GP;
- новая опция server.timeout, которую разработчик может использовать для указания тайм-аута активности соединения с сервером gpfdist;
- повышение производительности чтения из СУБД Greenplum за счет использования внутреннего столбца таблицы Greenplum с именем gp_segment_id в качестве столбца partitionColumn по умолчанию, когда разработчик не указывает этот параметр;
- решена проблема с некорректным раскрытием предикатов, когда при их объединении не использовались круглые скобки при построении строки фильтра.
При этом в Greenplum-Spark Connector 2.0.0 остаются следующие ограничения:
- коннектор не поддерживает чтение или запись в базу данных Greenplum, если кластер Спарк развернут в Kubernetes;
- коннектор не поддерживает сложные типы данных Спарк, позволяя работать только с основными (Float, Integer, String и Date/Time).
Администрирование Greenplum / Arenadata DB
Код курса
GRAD
Ближайшая дата курса
2 декабря, 2024
Продолжительность
40 ак.часов
Стоимость обучения
120 000 руб.
Как устроен Greenplum-Spark Connector: архитектура и принцип действия
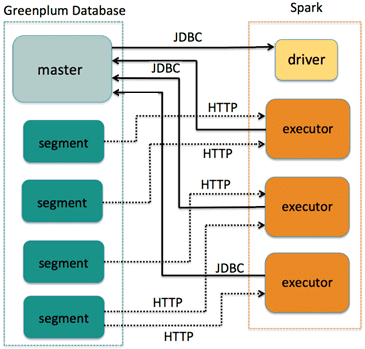
Когда приложение использует Greenplum-Spark Connector для загрузки таблицы базы данных GP в Спарк, драйвер (driver) инициирует обмен данными с главным узлом (master) этой MPP-СУБД через JDBC для запроса метаданных. Эта информация помогает коннектору определить, где данные таблицы хранятся в СУБД Greenplum, и как эффективно разделить данные и задания по их обработке между доступными рабочими узлами кластера Спарк. СУБД GP хранит табличные данные по сегментам (segment).
Приложение Спарк, использующее коннектор для интеграции с GP, идентифицирует определенный столбец таблицы базы данных GP как столбец раздела. Коннектор использует значения данных в этом столбце, чтобы назначить определенные строки таблицы в каждом сегменте GP одному или нескольким разделам Спарк. В рабочем узле Спарк каждое приложение запускает свой собственный процесс-исполнитель (executor), который порождает задачу для каждого раздела. Эта задача связывается с главным сервером GP через JDBC, чтобы создать и заполнить внешнюю таблицу строками данных, управляемыми соответствующим разделом Спарк. Затем каждый сегмент GP передает эти табличные данные через HTTP-протокол непосредственно своей задаче Спарк.
Такой обмен данными происходит во всех сегментах параллельно, ускоряя аналитическую обработку Big Data за счет распределенного масштабирования рабочих нагрузок.
В частности, чтобы считать данные из GP в коннектор, нужно создать scala.collection.Map, состоящий из строк для каждого параметра. Пример кода на Scala будет выглядеть так [1]:
val gscOptionMap = Map( "url" -> "jdbc:postgresql://gpdb-master:5432/testdb", "user" -> "gpadmin", "password" -> "changeme", "dbtable" -> "table1", "partitionColumn" -> "id" )
Чтобы загрузить данные из GP в Спарк, нужно указать источник данных Greenplum-Spark Connector, прочитать параметры и вызвать метод DataFrameReader.load (), как показано ниже:
val gpdf = spark.read.format("io.pivotal.greenplum.spark.GreenplumRelationProvider")
.options(gscOptionMap)
.load()
На внутреннем уровне Greenplum-Spark Connector оптимизирует параллельную передачу данных между сегментами этой MPP-СУБД и исполнителями Спарк. Использовать структуру данных DataFrame для доступа к данным можно сразу после того, как все worker’ы этого фреймворка завершат процесс загрузки. Как подобный коннектор реализовала российская компания Аренадата в виде ADB-Spark Connector мы расскажем в новом материале.
Core Spark - основы для разработчиков
Код курса
CORS
Ближайшая дата курса
16 декабря, 2024
Продолжительность
16 ак.часов
Стоимость обучения
48 000 руб.
Про особенности передачи данных из Apache Kafka в GP мы рассказываем в этой статье. А о коннекторе для интеграции GP с Apache NiFi читайте здесь.
Практически разобрать интеграцию Apache Spark с Greenplum и другие особенности эксплуатации этих технологий аналитики больших данных на примере решений Arenadata или отдельных фреймворков вам помогут специализированные курсы в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Greenplum для инженеров данных
- Основы Apache Spark для разработчиков
- Анализ данных с Apache Spark
- Потоковая обработка в Apache Spark
- Администрирование Greenplum / Arenadata DB