 717
717 
Вчера мы разбирали In-Memory СУБД на примере Tarantool. Сегодня поговорим про Arenadata Grid: что это такое, чем хороша эта база данных, каким образом она связана с Тарантул и чем от него отличается. Также рассмотрим, как Arenadata Grid интегрируется с внешними Big Data системами, в т.ч. основными компонентами инфраструктуры Apache Hadoop для хранения больших данных: HBase и HDFS.
Краткий обзор Arenadata Grid
Arenadata Grid (ADG) – это платформа резидентных вычислений от российской компании «Аренадата Софтвер», которая разработала первый отечественный дистрибутив Apache Hadoop (Arenadata Hadoop, ADH). ADG позволяет значительно ускорить приложения без замены существующих СУБД и линейно масштабировать Big Data систему на сотни кластерных узлов в режиме постоянной работы. В основе Arenadata Grid лежит Tarantool, что обеспечивает основные преимущества этой Big Data системы [1]:
- распределенный кэш «ключ-значение» в памяти, что позволяет выполнять сквозное чтение и запись, в т.ч. между разными Big Data приложениями;
- высокая скорость вычислений благодаря in-memory подходу, что увеличивает производительность используемых традиционных СУБД в 1000 раз путем сокращения затрат на чтение и запись с жесткого диска;
- гибкая линейная масштабируемость путем добавления новых узлов в существующий кластер без его остановки. Оптимальное расположение данных в кластере уменьшает их миграцию при изменении топологии. В случае необходимости миграция данных выполняется автоматически.
- Распределённые транзакции и SQL-запросы;
- Многоуровневое хранение данных в оперативной памяти и на жестком диске вне кучи (OffHeap);
- Отсутствие мастер-узла в кластере благодаря специальной функции расчета нужного сервера с целевой записью.
С практической точки зрения наиболее частыми сценариями использования ADG считаются следующие [1]:
- ускорение обработки аналитических запросов над оперативными данными в массивно-параллельной СУБД, например, Arenadata DB или Greenplum. Также здесь можно отметить ускорение распределенных вычислений на Apache Hadoop или Spark.
- реализация транзакционного кэша данных для систем потоковой передачи и шин данных. В этом случае ADG выполняет подкачку данных из реляционной или NoSQL-СУБД в оперативную память.
- распределенное хранение транзакционных данных с поддержкой SQL-запросов как в памяти, так и на диске.
ADG vs Tarantool: сходства и отличия
При том, что Arenadata Grid основана на Tarantool, она также дополнена специфическими компонентами для удобства администрирования и эксплуатации [2]:
- службы мониторинга хостов и метрик экземпляров и приложений Tarantool для интеграции сArenadata Monitoring;
- служба сбора событий с экземпляров Tarantool для агрегации и индексирования в кластереElasticSearch;
- HTTP-балансировщик вызовов REST-API.
По аналогии с Arenadata DB (ADB), бесшовная интеграция с экосистемой Apache Hadoop (HBase, HDFS, Hive) обеспечивается за счет параллельного обмена данными по JDBC-протоколу в рамках Java-фреймворка PXF. Напомним, PXF позволяет СУБД параллельно обмениваться данными со сторонними системами с помощью самостоятельно написанных коннекторов. PXF представляет собой отдельный процесс на сервере, который общается с сегментами СУБД через REST API с одной стороны, а с другой использует сторонние Java-клиенты и библиотеки [3]. О практическом использовании этого решения на базе MPP-СУБД Greenplum мы рассказывали здесь, разбирая кейс X5 Retail Group по построению распределенной отказоустойчивой системы аналитики больших данных.
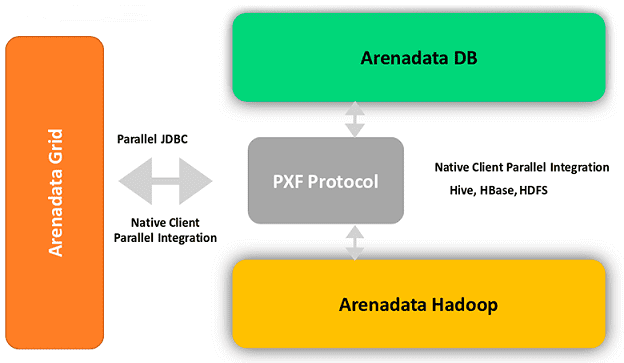
Несмотря на общее ядро и область практического использования, Tarantool и Arenadata Grid сложно назвать прямыми конкурентами. Скорее они дополняют друг друга, предоставляя свои специфические преимущества. Это подтверждает соглашение о стратегическом сотрудничестве и совместной разработке Big Data решений, подписанное вендорами этих In-Memory СУБД в ноябре 2019 года [4].
На практике наиболее значимым фактором выбора между Tarantool и Arenadata Grid является существующая или планируемая ИТ-инфраструктура, где будет использоваться одна из этих In-Memory СУБД. Например, если основой вашей Big Data экосистемы являются решения компании Areandata (ADH, ADB, QwikMarts), логичнее выбрать ADG с целью легкой интеграции и единообразия. В других случаях стоит решать индивидуально, сравнивая возможности расширения, особенности эксплуатации и поддержки вендора, а также прочие сопутствующие условия.
В следующей статье мы поговорим про интеграцию Tarantool с Apache Kafka, разобрав коннекторы и процессоры обработки потоковых данных на примере Arenadata Grid. А освоить тонкости работы с продуктами компании Arenadata и получить сертификат специалиста можно в нашем лицензированном учебном центре обучения и повышения квалификации руководителей и ИТ-профессионалов (менеджеров, архитекторов, инженеров, администраторов, аналитиков и Data Scientist’ов) «Школа Больших Данных» в Москве:
- Администрирование кластера Arenadata Hadoop
- Основы Arenadata Hadoop
- Эксплуатация Arenadata DB
- Администрирование кластера Arenadata Streaming Kafka
- Администрирование Arenadata Streaming NiFi
Источники
- https://arenadata.tech/products/adg/
- https://docs.arenadata.io/adg/Concepts/index/
- https://habr.com/ru/company/ibs/blog/343640/
- https://www.cnews.ru/news/line/2019-11-11_mailru_group_i_ibs_podpisali_soglashenie

