 828
828 
Содержание
Мы уже рассказывали про интеграцию Tarantool с Apache Kafka на примере Arenadata Grid. Сегодня рассмотрим, как интегрировать Кафка с MPP-СУБД Greenplum и каковы ограничения каждого из существующих способов. Читайте в сегодняшнем материале, что такое GPSS, PXF и при чем тут Docker-контейнер с коннектором Кафка для Arenadata DB.
IoT и не только или зачем интегрировать Greenplum с Apache Kafka
Прежде всего поясним, почему вообще возникает задача интеграции MPP-СУБД Greenplum с брокером сообщений Apache Kafka. Представьте, что есть множество входящих потоков данных, например, от устройств интернета вещей (Internet of Things, IoT), которые необходимо проанализировать в реальном времени. Или нужна оперативная аналитика биржевых показателей на платформе онлайн-трейдинга, где миллионы клиентов со всего мира торгуют валютой и ценными бумагами в режиме онлайн. Технология массивно-параллельной обработки данных (Massive Parallel Processing, MPP), реализованная в Greenplum, позволяет быстро и надежно решить подобные проблемы событийно-потоковой обработки (event streaming). Однако, загрузка этой информации происходит в Greenplum не напрямую, а опосредовано, через надежную Big Data систему сбора и агрегации потоковых данных – распределенную стриминговую платформу Apache Kafka.
6-я версия Greenplum, выпущенная осенью 2019 года, включает 2 следующих способа интеграции с Apache Kafka [1]:
- Greenplum Stream Server (GPSS) – средство ETL-процессов, которое принимает потоковые данные от одного или нескольких клиентов, используя механизм внешних таблиц базы Гринплам для преобразования и вставки данных в целевую таблицу этой СУБД;
- PXF (Platform eXtension Framework) – специализированный Java-фреймворк параллельного обмена данными со сторонними системами, который обеспечивает одновременное взаимодействие всех сегментов кластера Гринплам с внешним источником данных.
Также интересен способ интеграции Arenadata DB, основанной на Greenplum, и Кафка с помощью специализированного коннектора. Каждый из перечисленных способов мы подробнее рассмотрим далее.
Greenplum для инженеров данных и аналитиков данных
Код курса
GPDE
Ближайшая дата курса
16 февраля, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
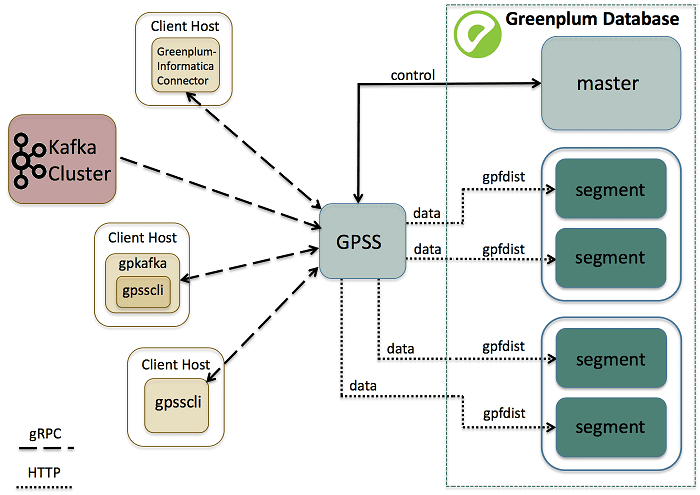
Что такое Greenplum Stream Server и как он работает
Greenplum Stream Server – это потоковый сервер gRPC, система удаленного вызова процедур с открытым исходным кодом, изначально разработанная в Google в 2015 году. Он включает операции и сообщения, необходимые для подключения к Greenplum и для записи данных от внешней системы в таблицу MPP-СУБД [2]:
- утилита командной строки gpss, которая позволяет запустить экземпляр GPSS, бесконечно ожидающий данных клиента;
- утилита командной строки gpsscli для отправки заданий загрузки данных из Kafka в экземпляр GPSS и управления этими заданиями.
Типичная последовательность выполнения ETL-задачи с использованием GPSS выглядит следующим образом [2]:
- пользователь инициирует одно или несколько ETL-заданий через клиентское приложение;
- клиентское приложение использует gRPC-протокол для отправки и запуска заданий на загрузку данных в работающий экземпляр службы GPSS;
- Экземпляр службы GPSS передает каждую транзакцию запроса на загрузку в главный экземпляр кластера Greenplum, с помощью протокола gpfdist для хранения данных во внешних таблицах, которые создаются вновь или используются повторно.
- Экземпляр службы GPSS записывает данные, полученные от клиента, непосредственно в сегменты кластера базы данных Greenplum.
Важным ограничением этого способа является то, что Greenplum Stream Server не поддерживает загрузку данных из нескольких топиков Kafka в одну и ту же таблицу СУБД Гринплам. В этом случае все задания будут зависать [3].
Как устроен PXF-фреймворк
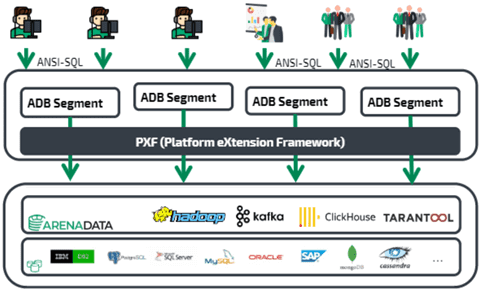
PXF появился еще в 5-ой версии Greenplum в 2017 году. Этот Java-фреймворк реализован в виде отдельного процесса на сервере, который общается с сегментами Greenplum через REST API с одной стороны, а с другой – использует сторонние Java-клиенты и библиотеки, чтобы через JDBC связать Гринплам с Apache HDFS, Hbase и Hive, а также внешними СУБД. Например, именно так X5 Retail Group в 2019 году построила собственную аналитическую платформу на базе Arenadata DB с кластером Hadoop, о чем мы подробно рассказывали здесь.
PXF предоставляет коннекторы для доступа к данным, хранящимся во внешних источниках. Коннекторы сопоставляют внешний источник данных с определением внешней таблицы базы данных Greenplum. Один процесс PXF-агента на каждом хосте сегмента Greenplum выделяет рабочий поток для каждого экземпляра СУБД, который участвует в запросе к внешней таблице. Агенты PXF на хостах с несколькими сегментами взаимодействуют с внешним хранилищем данных параллельно. PXF содержит встроенные коннекторы для Hadoop (HDFS, Hive, HBase), хранилищ объектов (Azure, Google Cloud Storage, Minio, S3) и баз данных SQL (через JDBC), а также поддерживает форматы данных text, Avro, JSON, RCFile, Parquet, SequenceFile и ORC [4].
Именно PXF-коннекторы лежат в основе интеграции Arenadata DB c Apache Kafka, которую мы рассмотрим далее.
Big Data интеграция: коннектор к Кафка в Arenadata DB
Установка коннектора выполняется с помощью специального пакета adb_kafka_external_connector-<version>.rpm на все сервера-сегменты кластера Greenplum. Этот пакет добавляет на каждый сервер Гринплам исполняемые файлы [5]:
- /usr/lib/adbkafka/adb-kafka-consumer;
- /usr/lib/adbkafka/adb-kafka-producer.
С архитектурной точки зрения коннектор Arenadata DB (ADB) к Apache Kafka – это кластер из отдельных синхронизированных процессов, запущенных в Docker, которые, с одной стороны, являются потребителями Кафка (consumer), а с другой — вставляют данные из топиков напрямую в сегменты Greenplum. Коннектор может работать с Kafka Registry и обеспечивает полную консистентность переносимых данных даже в случае аппаратных сбоев [6].
При использовании этого решения необходимо учитывать следующую специфику:
- число разделов (partition) в топике Kafka должно быть больше или равно числу сегментов ADB, которые запрашивают данные. Иначе нужно корректировать число сегментов при создании внешней таблицы [7];
- все сегменты-хосты кластера ADB должны иметь сетевой доступ до всех брокеров и Zookeeper-узлов кластера Kafka, а также иметь о них записи (hostname и IP-адрес) в своих директориях /etc/hosts [8];
- создание внешних таблиц коннектора доступно только суперпользователям СУБД, при том использование таблиц не ограничено [7].
Курс Apache Kafka: администрирование кластера
Код курса
KAFKA
Ближайшая дата курса
26 января, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
В следующей статье мы продолжим разговор про Apache Kafka и Zookeeper на примере интеграции с колоночной аналитической СУБД для больших данных ClickHouse. Про особенности интеграции Apache Spark c GP мы рассказываем в этой статье. А про коннектор для передачи данных из Apache NiFi в Гринплам читайте здесь.
Больше подробностей по настройке и эксплуатации Greenplum на примере Arenadata DB рассматривается на специализированном курсе Эксплуатация Arenadata DB в нашем лицензированном учебном центре повышения квалификации «Школа Больших Данных», который является единственным авторизованным партнером компании Arenadata по сертификации специалистов и обучению в Москве.
А особенности интеграции Apache Kafka с другими внешними источниками для потоковой обработки Big Data вы узнаете на практических курсах по Кафка для программистов, архитекторов, инженеров и аналитиков больших данных:
Источники
- http://docs.greenplum.org/6-4/analytics/overview/
- https://gpdb.docs.pivotal.io/streaming-server/1-3-6/overview/
- https://medium.com/@yaniv.bhemo/how-to-integrate-greenplum-db-with-apache-kafka-5bada63400b3
- https://gpdb.docs.pivotal.io/6-1/pxf/intro_pxf/
- https://docs.arenadata.io/adb/adbkafka/Installation/
- https://habr.com/ru/post/474008/
- https://docs.arenadata.io/adb/adbkafka/Restrictions/
- https://docs.arenadata.io/adb/adbkafka/Requirements/

