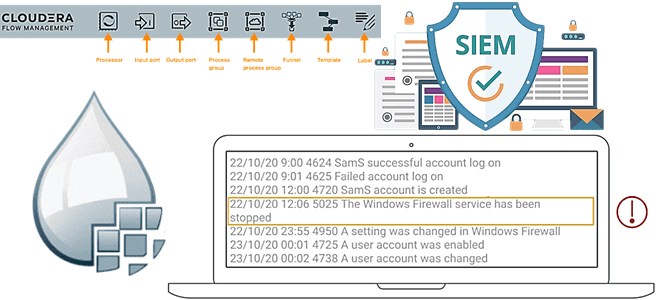
В этой статье для дата-инженеров рассмотрим, что такое Cloudera Flow Management и как это позволяет ускорить аналитику больших данных в кейсах информационной безопасности. Читайте далее о преимуществах SIEM-анализа, преобразования и распределения security-событий с помощью Apache NiFi и его легковесного агента MiNiFi для устройств интернета вещей (Internet Of Things, IoT). Что...
Чтобы добавить в курсы по Apache AirFlow еще больше полезных примеров, сегодня рассмотрим, как избежать дублирования кода при загрузке данных. Этот пример пригодится дата-инженерам в работе с ELT-процессами наполнения информацией корпоративных хранилищ и озер данных. Читайте про фреймворк динамической загрузки данных на базе конфигурационных YAML-файлов, DAG-фабрик и загрузчиков. Проблема дублирования...

Продвигая наш новый курс «Greenplum для инженеров данных», сегодня мы рассмотрим особенности организации таблиц в этой MPP-СУБД, типы данных и оптимальное расположение столбцов. Читайте далее, чем heap storage отличается от append-optimized, когда выбирать колоночную, а когда – строковую модель хранения данных для таблицы, почему BIGINT с TIMESTAMP следует размещать перед...

Сегодня рассмотрим, что такое Data Build Tool, как этот ETL-инструмент связан с корпоративным хранилищем и озером данных, а также чем полезен дата-инженеру. В качестве практического примера разберем кейс подключения DBT к Apache Spark, чтобы преобразовать данные в таблице Spark SQL на Amazon Glue со схемой поверх набора файлов в AWS...

Постоянно добавляя в наши курсы Apache Kafka для разработчиков интересные и практические примеры, сегодня мы разберем кейс тревел-площадки Trainline, которая агрегирует данные от 270 железнодорожных и автобусных компаний в 45 странах, предлагая выгодные билеты на европейские поезда и автобусы. Читайте далее, почему пакетный режим работы озера данных перестал отвечать требованиям...

Сегодня рассмотрим пример построения системы аналитики больших данных для мониторинга финансовых транзакций в реальном времени на базе облачного Delta Lake и конвейера распределенных приложений Apache Kafka, Spark Structured Streaming и других технологий Big Data. Читайте далее о преимуществах облачного Delta Lake от Databricks над традиционным Data Lake. Постановка задачи: финансовая...

Чтобы дополнить наши курсы по Spark для разработчиков распределенных приложений и инженеров данных практическими примерами, сегодня рассмотрим кейс американской ИТ-компании ThousandEyes, которая разрабатывает программное обеспечение для анализа производительности локальных и глобальных сетей. Читайте далее, как создать надежный конвейер и устойчивое озеро данных (Data Lake) для быстрой аналитики Big Data в...
Мы уже рассказывали, почему качество данных является важнейшим аспектом разработки и эксплуатации Big Data систем. Приемлемое для эффективного использования качество массивов информации достигается не только с помощью процессов подготовки датасета к машинному обучению и профилирования данных, но и за счет их согласования. Читайте далее, что такое Data reconciliation, зачем это...

Продолжая разговор про фиксацию заданий Apache Spark при работе с облачными хранилищами больших данных, сегодня подробнее рассмотрим, насколько эффективны commit-протоколы экосистемы Hadoop, предоставляемые по умолчанию, и почему известный разработчик Big Data решений, компания Databricks, разработала собственный алгоритм. Читайте далее про сравнение протоколов фиксации заданий в Spark-приложениях: результаты оценки производительности и...

Сегодня поговорим про особенности транзакций в Apache Spark, что такое фиксация заданий в этом Big Data фреймворке, как она связано с протоколами экосистемы Hadoop и чем это ограничивает переход в облако с локального кластера. Читайте далее, как найти компромисс между безопасностью и высокой производительностью, а также чем облачные хранилища отличаются...