
Дополняя наши курсы по аналитике больших данных в бизнес-приложениях новыми полезными примерами, сегодня рассмотрим, как Apache Arrow помогает повысить производительность извлечения данных из Neo4j с помощью их колоночного представления и обработки в памяти, а не на диске. Чем neo4j-arrow лучше драйверов Java и Python, а также собственной Neo4j библиотеки Graph...
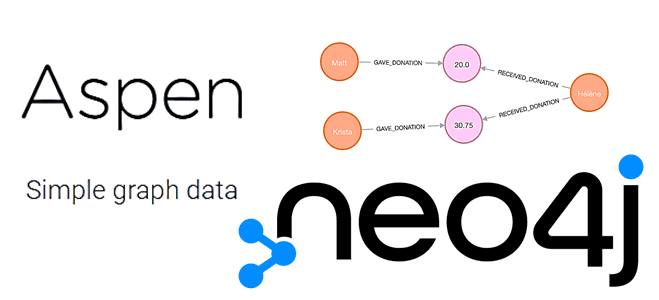
Обучая дата-аналитиков и разработчиков Neo4j, сегодня разберем, что такое Aspen, как этот язык разметки переводит текст в запрос Cypher с помощью одной командной строки и каким образом это пригодится для графовой аналитики больших данных в бизнес-приложениях. Что такое Aspen, а также как он связан с Neo4j и Cypher Будучи написанным на Ruby...

В этой статье для дата-аналитиков и разработчиков Neo4j, разберем, как реализовать GraphQL-сервер для взаимодействия с этой графовой NoSQL-СУБД. Библиотека Neo4j GraphQL и ее практическое применение для графовой аналитики больших данных в бизнес-приложениях. Еще раз про GraphQL О том, что такое GraphQL (GQL) и как это связано с архитектурным стилем REST, мы писали...

Продвигая наш новый курс по графовой аналитике больших данных в бизнес-приложениях, сегодня поговорим про визуализацию графов в NoSQL-СУБД Neo4j. А также рассмотрим, как с помощью GraphKer получить визуальное отображение графа данных о информационной безопасности: уязвимости, атаки и прочие нарушения cybersecurity. ТОП-5 способов визуализации графов в Neo4j Поскольку люди лучше воспринимают визуальную информацию, инструменты...
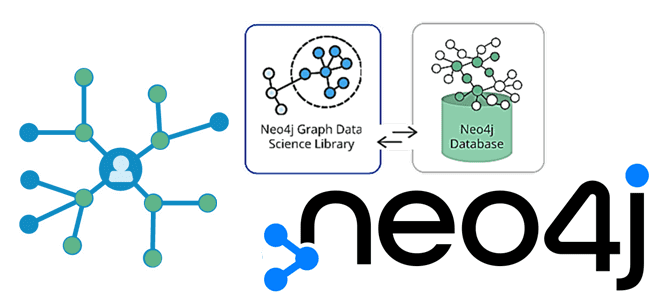
Продвигая наши курсы по прикладной Data Science и графовой аналитике больших данных в бизнес-приложениях, сегодня рассмотрим специальную DS-библиотеку в Neo4j и ее возможности для фильтрации подграфов. А также разберем, чем версия сообщества отличается от Enterprise Edition, как запустить анализ слабо связанных компонент и алгоритм определения центральности на проекции графа в памяти. Graph...
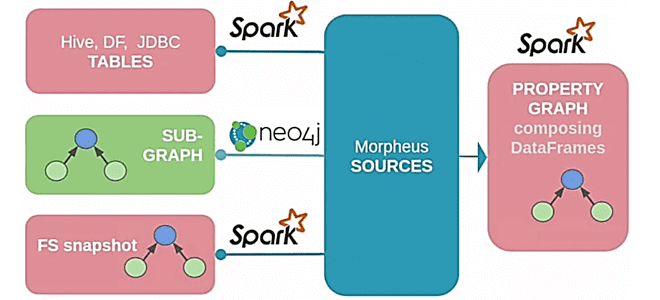
В рамках нашего нового курса по графовой аналитике больших данных в бизнес-приложениях, сегодня рассмотрим, как язык запросов Cypher должен был появиться в Apache Spark 3.0, зачем это нужно и почему до сих пор не реализовано. Краткая история проекта Morpheus, его связь с Neo4j, а также модулями Spark GraphX и GraphFrames. Что такое Morpheus...

Вчера мы рассматривали коннектор Neo4j к Apache Spark, который позволяет строить конвейеры аналитики больших данных с применением графовых алгоритмов. Продолжая эту тему, сегодня разберем варианты интеграции Neo4j с Apache Kafka с помощью шаблонных запросов Cypher в плагине и коннектора от Confluent, а также от каких конфигурационных параметров зависит пропускная способность...

Продвигая наш новый курс по графовой аналитике больших данных в бизнес-приложениях, сегодня заглянем под капот коннектора Neo4j к Apache Spark. Сценарии использования, принципы работы, поддержка потоковой передачи Spark и другие новинки версии 4.1 для построения эффективных аналитических коннекторов с помощью алгоритмов на графах. Как работает коннектор Neo4j к Apache Spark: краткий обзор Осенью...

В рамках продвижения нашего нового курса по графовой аналитике больших данных в бизнес-приложениях, сегодня рассмотрим пример анализа данных о путешествиях средствами графовой СУБД Neo4j и ее языка запросов Cypher. Читайте далее, где взять данные о путешествиях цифровых кочевников и как определить самое популярное направление. Цифровые кочевники и графы их путешествий Хотя...
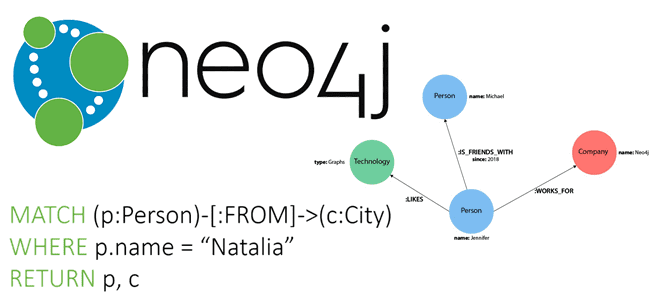
Продвигая наш новый курс по графовой аналитике больших данных в бизнес-приложениях, сегодня рассмотрим ключевые отличия графовых СУБД от реляционных, а также познакомимся с основами Neo4j и ее языком запросов - Cypher. Также вас ждет практический пример построения несложного графа средствами Cypher. Когда графовые СУБД лучше реляционных и почему Несмотря на...