 739
739 
В этой статье для дата-аналитиков и разработчиков Neo4j, разберем, как реализовать GraphQL-сервер для взаимодействия с этой графовой NoSQL-СУБД. Библиотека Neo4j GraphQL и ее практическое применение для графовой аналитики больших данных в бизнес-приложениях.
Еще раз про GraphQL
О том, что такое GraphQL (GQL) и как это связано с архитектурным стилем REST, мы писали здесь. GraphQL развивает REST-технологию взаимодействия компонентов распределенного приложения с использованием HTTP-протокола. Будучи изначально разработанным Facebook для собственных нужд, в 2015 году язык запросов GraphQL стал публично доступным. Подобно RESTful-API, GQL позволяет клиентским приложениям работать с данными в разных источниках: СУБД, файловое или объектное хранилище и пр., с помощью простых GET и POST-запросов. Однако, в отличие от RESTful API, GraphQL позволяет передавать и получать только те данные, которые нужны для каждого конкретного случая, а не все то, что есть на конечной точке. Это экономит объем сетевого трафика, повышает гибкость приложений, позволяет объединять разные сущности в один запрос и увеличивает скорость разработки на клиенте.
Язык запросов и серверная среда их выполнения для API-интерфейсов GQL реализует все четыре основных функции работы с данными, называемые CRUD-операциями (Create, Read, Update, Delete). Запросы на чтение называются простыми (query), а за изменение данных отвечают мутации (mutation), которые выполняют операции создания (Create), обновления (Update) и удаления (Delete) записей. Мутации реализуются как вызов удаленных процедур (RPC, Remote Procedure Call), который передается с клиента на GraphQL-сервер, т.е. HTTP-сервер с GQL-схемой данных (JSON, AVRO и т.д.). Вспомнив, что такое GQL и чем это полезно, далее рассмотрим, как использовать этот язык запросов совместно с графовой NoSQL-СУБД Neo4j.
Библиотека Neo4j и связь с Cypher
Можно рассматривать GraphQL как архитектуру проектирования API, когда все запросы на операции с данными представляются как связанный граф: сервис создается через определение типов и полей для них с последующим предоставлением функций для каждого поля. Neo4j включает специальную библиотеку, которая позволяет быстро разработать сервер GQL для взаимодействия с этой графовой СУБД. Также эта библиотека автоматически предоставляет функции, необходимые для получения типов и полей, определенных в схеме GQL. При этом имя типа должно быть идентично метке узла в Neo4j. Библиотека Neo4j GraphQL по умолчанию предлагает полную поддержку CRUD-операций.
По сути, библиотека Neo4j GraphQL — это уровень выполнения запросов GQL к Cypher для реализаций Neo4j и JavaScript. Чтобы использовать библиотеку, следует предоставить определения нужных типов для генерации схемы GraphQL с CRUD-преобразователями, которые производят Cypher и поддерживаются экземпляром Neo4j. Получив схему, ее можно передать в любой совместимый инструмент JavaScript GQL, например, Apollo Server, и подготовить функциональный API для клиентов. Это экономит время разработчика на написание повторяющихся преобразователей или бизнес-логики.
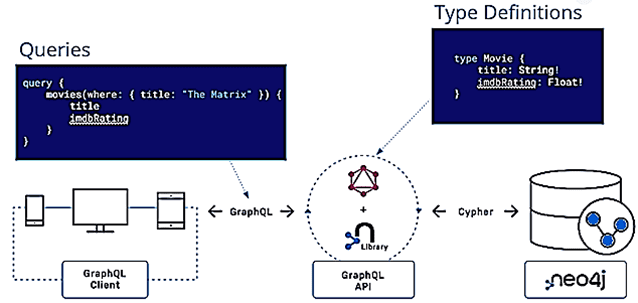
Наиболее простое отображение типов GQL — это узлы Neo4j, где имя типа GraphQL сопоставляется с меткой узла Neo4j. Отношения как связи между узлами графа представлены путем пометки определенных полей директивой. Эта директива @relationship определяет тип отношений в базе данных, а также направление, в котором они развиваются.
Например, определим тип «Пользователь» (User) со свойством «Имя» (name) и тип «Пост» (Post) со свойствами «Контент» (Content) и «Лайки» (likes), которые показывает, сколько пользователей отметили этот пост. GQL-схема будет выглядеть так:
type User {
name: String
}
type Post {
content: String
likes: [User] @relationship(type: «LIKES», direction: IN)
}
Найти посты с числом лайков больше 5, поможет следующий GQLзапрос:
query {
posts(where: { likesAggregate: { count_GT: 5 } }) {
content
}
}
В заключение отметим, что Neo4j предоставляет инструмент, который позволяет с минимальными усилиями генерировать определения типов GraphQL из существующей базы данных. Это предоставляется отдельным npm-пакетом introspector. Обычно это однократная процедура, которую следует рассматривать как отправную точку для схемы GQL. Этот инструмент полностью поддерживает создание определений типов, включая свойства отношения через директиву @relationship и метку узлов @node, чтобы сопоставлять его с символами, которых нет в поддерживаемом GQL наборе, а также additionalLabels для узлов с несколькими метками. Если свойство элемента имеет смешанные типы на графе, оно будет исключено из сгенерированных определений типов, т.к. GraphQL-сервер выдаст ошибку, найдя данные, не соответствующие указанному типу. При пропуске каких-либо свойств, они будут выведены в журнал отладки.
Сохранив созданные определения типов в файле GraphQL-схемы, например, schema.graphql, этот файл можно использовать на своем сервере.
Узнайте больше подробностей про использование Neo4j для графовой аналитики больших данных в бизнес-приложениях на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков больших данных в Москве:
Источники

