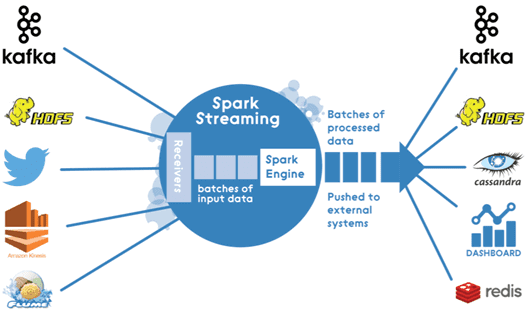
В этой статье мы рассмотрим архитектуру Big Data конвейера по непрерывной обработке потоковых данных в режиме реального времени на примере интеграции Apache Kafka и Spark Streaming. Что такое Spark Streaming и для чего он нужен Spark Streaming – это надстройка фреймворка с открытым исходным кодом Apache Spark для обработки потоковых...

Apache Kafka – не единственный программный брокер сообщений и система управления очередями, используемая в высоконагруженных Big Data проектах. Кафка часто сравнивают с другим популярным продуктом аналогичного назначения – RabbitMQ. В сегодняшней статье мы рассмотрим, чем похожи и чем отличаются Apache Kafka и RabbitMQ, а также поговорим о том, что следует...

Мы уже рассказывали о сериализации, схемах данных и их важности в Big Data на примере Schema Registry для Apache Kafka. В продолжение ряда статей про основы Кафка для начинающих, сегодня мы поговорим про Apache Avro – наиболее популярную схему и систему сериализации данных: ее особенностях и применении в технологиях Big...
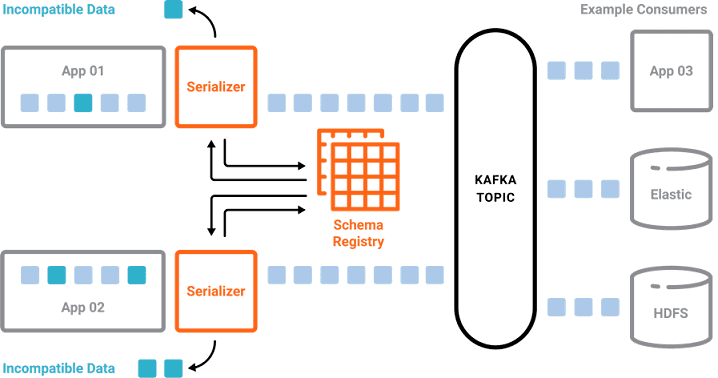
Продолжая серию публикаций про основы Apache Kafka для начинающих, в этой статье мы рассмотрим, зачем этой распределенной системе управления сообщениями нужен реестр схем данных (Schema Registry) и что такое сериализация файлов Big Data. Что такое схемы данных в Big Data и как они используются Понятие схемы неразрывно связано с форматом...

В рамках серии публикаций про основы Apache Kafka для начинающих, сегодня мы поговорим про информационную безопасность этой популярной в сфере Big Data распределенной системы управления сообщениями: шифрование, защищенные протоколы, аутентификация, авторизация и другие средства cybersecurity. Что обеспечивает безопасность Apache Kafka в кластере Big Data Информационная безопасность Apache Kafka основана на...
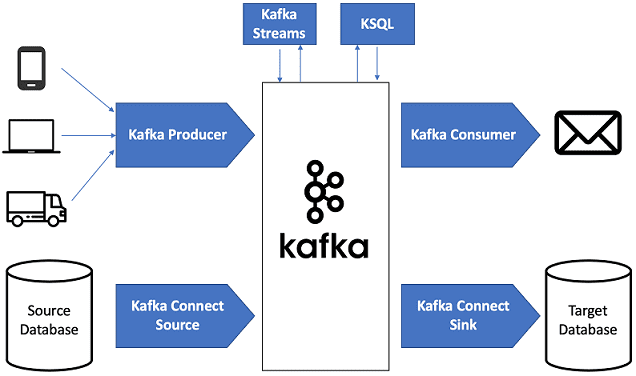
Продолжая разговор про основы Apache Kafka, сегодня мы рассмотрим, почему этот распределённый брокер сообщений стал таким популярным в архитектуре систем Big Data. Читайте в нашей статье, как Кафка обеспечивает высокую производительность процессов сбора и агрегации информационных потоков от множества источников, надежно гарантируя долговечную сохранность сообщений, и эффективно интегрируется с другими...
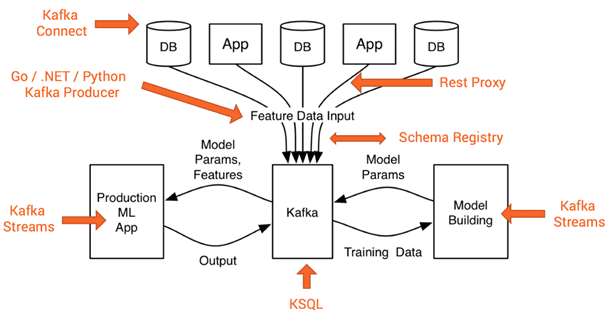
Рассмотрев основы Apache Kafka, сегодня мы расскажем о месте этого распределённого брокера сообщений в архитектуре Big Data систем. Читайте в нашей статье, какие компоненты Кафка обеспечивают ее использование в программных продуктах машинного обучения (Machine Learning, ML), интернете вещей (Internet Of Things, IoT), системах бизнес-аналитики (Business Intelligence, BI), а также других...

Мы уже упоминали Apache Kafka в статье про промышленный интернет вещей (Industrial Internet Of Things, IIoT). Сегодня поговорим о том, где и для чего еще в Big Data проектах используется эта распределённая, горизонтально масштабируемая система обработки сообщений. Как работает Apache Kafka Apache Kafka позволяет в режиме онлайн обеспечить сбор и...

Мы уже рассказывали про достоинства и недостатки самой популярной DevOps-технологии 2019 года – платформы управления контейнерами Kubernetes для Big Data систем. Сегодня поговорим, зачем вообще нужны контейнеры, чем они отличаются от виртуальных машин, каковы их плюсы и минусы, а также для чего нужна их оркестрация. Что такое контейнеризация приложений и...

Сегодня, когда ИТ-компании распиливают монолиты своих Big Data систем на микросервисы, а DevOps-подход совершает свое победное шествие по локальным и облачным кластерам, Kubernetes стал, пожалуй, самой востребованной технологией 2019 года. Однако, K8s нужен далеко не каждому проекту. В этой статье мы поговорим о достоинствах и недостатках кубернетис, в каких случаях...