 1886
1886 
Содержание
Мы уже рассказывали о сериализации, схемах данных и их важности в Big Data на примере Schema Registry для Apache Kafka. В продолжение ряда статей про основы Кафка для начинающих, сегодня мы поговорим про Apache Avro – наиболее популярную схему и систему сериализации данных: ее особенностях и применении в технологиях Big Data.
Как устроен Apache Авро: принцип работы
Напомним, сериализация – это процесс преобразования данных из текстового формата в двоичный, необходимый для передачи данных по сети и сохранения информации в виде файла на диске, в памяти или базе данных.
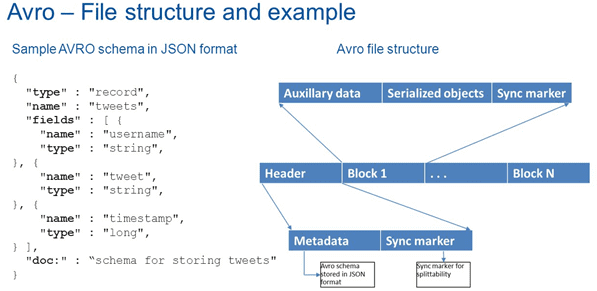
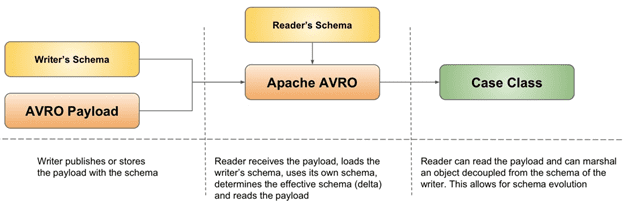
Avro создает файл, в котором он хранит данные вместе со схемой в своем разделе метаданных вместо хранения информацию о типе поля с каждым полем. Благодаря этому для чтения сериализованной информации не требуется предварительное знание схемы [1].
Схема данных Avro – это описание структуры данных на языке JSON (JavaScript Object Notation) – текстового формата, независимого от реализации. Авро обеспечивает богатую структуру данных, поддерживая следующие типы [2]:
- примитивные – null, Boolean, int (знаковое целое 32 бита), long (знаковое целое 64 бита), float, double, string (unicode строка), bytes (последовательность байт), fixed (последовательность байт с длиной, заданной в схеме);
- сложные составные – union (сумма), recod (произведение), enum (перечисление), array (массив/список), map (ассоциативный массив);
- логические (в терминологии AVRO) – decimal (число с фиксированной запятой), date (дата), time-millis (время с миллисекундной точностью), time-micros (время с микросекундной точностью), timestamp-millis (дата-время с миллисекундной точностью), timestamp-micros (дата-время с микросекундной точностью), uuid (universally unique identifier, универсальный уникальный идентификатор).
Контейнер Авро состоит из заголовка и одного или нескольких блоков данных [3]. Заголовок содержит:
- 4 байта, ASCII ‘O’, ‘b’, ‘j’, далее 1.
- метаданные файла, содержащие схему.
- 16-байтное случайное число — маркер файла.
Для блоков данных Avro может использовать бинарную кодировку или формат JSON. С точки зрения производительности бинарную кодировка эффективнее и компактнее, но для отладки удобнее использовать человекочитаемый формат JSON [3].
Протокол Avro описывает RPC-интерфейс с помощью следующих полей [3]:
- protocol – строка с именем протокола (обязательное поле);
- namespace– строка, которая дополняет/уточняет имя протокола
- doc – строка с описанием протокола на естественном языке;
- types – список определения сложных типов (особый тип errorопределяет тип ошибки);
- messages — JSON-объект, где ключ — название сообщения, а значение — само сообщение.
В рамках передаваемого в формате Avro сообщения иcпользуются следующие аргументы [3]:
- doc – строка c описанием сообщения;
- request – список именованных типизированных параметров схемы
- response – имя схемы;
- error – список именованных типизированных параметров схемы (среди ошибок);
- one-wayboolean, определяет может ли response быть null.
Преимущества Apache Avro по сравнению с другими схемами данных для Big Data систем
Компания Confluent, разработчик одной из наиболее популярных в промышленной эксплуатации версий Apache Kafka, отмечает следующие достоинства схемы данных Avro для использования ее в Big Data системах [4]:
- Прямое отображение в формат JSON, который часто используется для описания событий и объектов в Big Data системах;
- Компактное представление, по сравнению с вышеупомянутым JSON-форматом, для которого характерно многократное повторение некоторых участков кода (имя поля в каждой записи), что может быть критичным в больших объемах.
- Быстрота передачи и обработки данных благодаря компактности формата Авро;
- Поддержка множества языков программирования (C, C++, C#, Go, Haskell, Java, Python, Scala, а также другие скриптовые и ООП-языки).
- Широкие возможности по описанию объектов и событий, включая создание собственных схем данных, а также средства дополнения языка схемы, определяемые в чистом JSON.
- Обеспечение совместимости с предыдущими версиями по мере развития данных с течением времени.
Apache Kafka для инженеров данных
Код курса
DEVKI
Ближайшая дата курса
24 августа, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Разумеется, Apache Avro – не единственная система сериализации и схема данных для Big Data. В частности, в рамках экосистемы Apache Hadoop часто используется Parquet – бинарный, колоночно-ориентированный (столбцовый) формат хранения данных, разработанный специально для этого проекта [5]. Благодаря колоночному (столбцовому) представлению и ориентации, в первую очередь на работу в HDFS, Parquet показывает более высокие результаты в тестах на производительность (сравнение скорости записи, чтения, сжатия и SQL-запросов) по сравнению с Apache Avro [6]. Подробнее про сравнение Авро и Паркет читайте в нашей новой статье.
Тем не менее, благодаря следующим особенностям Авро, он пока остается весьма популярным форматом, схемой данных и системой сериализации [3]:
- поддержка удаленного вызова процедур (RPC, Remote Procedure Call);
- наличие 2-х видов кодировки: бинарный вид и человекочитаемый формат JSON, о чем мы рассказываем здесь;
- быстрота обработки и компактность представления бинарного формата данных;
- динамическая типизация (интеграция с динамически типизированными языками) и отсутствие предгенерации кода для работы. Данные сопровождаются схемой генерации кода, которая может быть обработана без статических типов в случае статически типизированных языков.
- Отсутствие накладных расходов на информацию о типах при сериализации данных, поскольку схема всегда находится рядом с данными.
- Обеспечение совместимости новых версий данных со следующими за счет отсутствия идентификаторов полей: при изменении схемы сохраняются обе версии, которые используются при обработке данных и все конфликты могут быть разрешены символьно ввиду отсутствия строгих целых идентификаторов.
Где используется Avro: Apache Kafka, Hadoop, а также другие технологии и проекты Big Data
Схема данных и система сериализации Авро достаточно часто используется в различных Big Data проектах для высоконагруженных систем во всем мире. Обзор вакансий с рекрутингового портала HeadHunter показал, что данная технология востребована не только крупными компаниями, (Сбербанк, МТС и другие data-driven предприятия, работающие c Big Data). Например, в Почте России Apache Avro используется для разработки межкорпоративных систем обмена данными.
Множество отечественных и зарубежных ИТ-компаний также применяют Авро в качестве устоявшегося и надежного средства работы с нереляционной информацией. Среди гигантов ИТ-индустрии стоит отметить опыт соцсети LinkedIn, где большие данные о пользовательском поведении (события, метрики и прочие информационные потоки в режиме онлайн) агрегировались в Apache Kafka с помощью схемы данных Avro, а затем сохранялись в кластере Apache Hadoop [4]. Подробнее о том, как Kafka использует реестр схем, читайте в нашей новой статье.
Узнайте, как работать с Apache Avro на практике в Kafka, Hadoop и других технологиях больших данных на наших практических курсах для руководителей, архитекторов, администраторов, инженеров, аналитиков Big Data и Data Scientist’ов в лицензированном учебном центре обучения и повышения квалификации ИТ-специалистов в Москве:
- https://www.codeflow.site/ru/article/java-apache-avro
- https://habr.com/ru/post/346698/
- https://ru.bmstu.wiki/Apache_Avro
- https://www.confluent.io/blog/avro-kafka-data/
- https://ru.bmstu.wiki/Apache_Parquet
- http://datareview.info/article/test-proizvoditelnosti-apache-parquet-protiv-apache-avro/

