 1224
1224 
Содержание
Мы уже рассказывали про достоинства и недостатки самой популярной DevOps-технологии 2019 года – платформы управления контейнерами Kubernetes для Big Data систем. Сегодня поговорим, зачем вообще нужны контейнеры, чем они отличаются от виртуальных машин, каковы их плюсы и минусы, а также для чего нужна их оркестрация.
Что такое контейнеризация приложений и как это работает
Контейнеризация (виртуализация на уровне операционной системы, контейнерная или зонная виртуализация) – это метод виртуализации, при котором ядро операционной системы поддерживает несколько изолированных экземпляров пространства пользователя вместо одного. С точки зрения пользователя эти экземпляры (контейнеры или зоны) полностью идентичны отдельной операционной системе. Ядро обеспечивает полную изолированность контейнеров, поэтому приложения из разных контейнеров не могут воздействовать друг на друга [1].
В неработающем состоянии контейнер – это файл (набор файлов) на диске. При запуске контейнера контейнерный движок (Docker, CRI-O, Railcar, RKT, LXC) распаковывает образ контейнера с нужными файлами и метаданными, передавая их ядру операционной системы (ОС).
Контейнерный движок – это программное обеспечение, принимающее запросы пользователя, в т.ч. параметры командной строки, скачивающее образы контейнеров и запускающее их. Запуск контейнера похож на запуск системного процесса и требует API-обращения к ядру ОС. Такой API-вызов обычно инициирует дополнительную изоляцию и монтирует копию файлов, которые находятся в образе контейнера. При этом с ядром ОС для запуска контейнеризованных процессов связывается среда выполнения контейнеров – низкоуровневый компонент, который обычно используется в составе контейнерного движка, но также может применяться и в ручном режиме для тестирования контейнеров. Среда выполнения контейнеров от контейнерного движка получает точку монтирования контейнера (при тестировании это может быть просто каталог) и метаданные контейнера (при тестировании это может быть собранный вручную файл config.json).
После запуска контейнер становится системным процессом. Процедура запуска контейнеров, а также формат образов контейнеров, хранящихся на диске, определяются и регулируются стандартами. Сегодня наиболее популярным становится стандарт Open Container Initiative (OCI), который задает спецификацию формата образов контейнеров, определяя дисковый формат их хранения, а также метаданные (аппаратная архитектура, операционная система) [2].
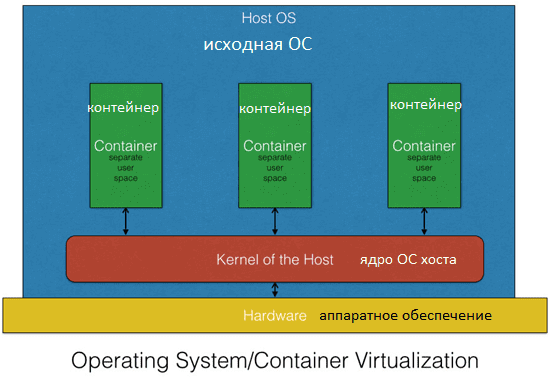
Чем отличается контейнер от виртуальной машины
В отличие от аппаратной виртуализации, когда эмулируется аппаратное окружение и может быть запущено множество гостевых ОС, в контейнере запускается экземпляр ОС только с тем же ядром, что и у исходной (хостовой) операционной системы. Таким образом, все контейнеры узла используют общее ядро. При этом отсутствуют дополнительные накладные расходы ресурсов на эмуляцию виртуального оборудования и запуск полноценного экземпляра ОС, что характерно аппаратной виртуализации. Существуют реализации для на создания практически полноценных экземпляров ОС (Solaris Containers, контейнеры Virtuozzo, OpenVZ), а также варианты изоляции отдельных сервисов с минимальным операционным окружением (jail, Docker) [1], которые наиболее часто используются в Big Data системах с учетом роста популярности микросервисной архитектуры.
Таким образом, контейнеры позволяют уместить гораздо больше приложений на одном физическом сервере, чем любая виртуальная машина, которая занимает гораздо больше системных ресурсов (оперативной памяти и процессорных циклов). В отличие от виртуальной машины, где эмулируется ОС и необходимое виртуальное оборудование, в контейнере размещается только приложение и необходимый минимум системных библиотек. Благодаря этому можно запустить в 2-3 раза больше приложений на одном сервере. Также контейнеризация позволяет создавать портативное и целостное окружение для разработки, тестирования и последующего развертывания, что соответствует подходу DevOps [3].

Преимущества и недостатки контейнеров в Big Data
С точки зрения использования контейнеризации приложений в Big Data наиболее значимы следующие достоинства этой технологии [4]:
- стандартизация – благодаря базе открытых стандартов контейнеры могут работать во всех основных дистрибутивах Linux, Microsoft и других популярных ОС;
- независимость контейнера от ресурсов или архитектуры хоста, на котором он работает, облегчает переносимость образа контейнера из одной среды в другую, обеспечивая непрерывный конвейер DevOps-процессов от разработки и тестирования к развертыванию (CI/CD pipeline);
- изоляция – приложение в контейнере работает в изолированной среде и не использует память, процессор или диск хостовой ОС, что гарантирует изолированность процессов внутри контейнера и обеспечивает некоторый уровень безопасности. Подробнее про безопасность в контейнерных технологиях, в частности, про уязвимости Kubernetes, мы написали в отдельных материалах.
- возможность повторного использования – все компоненты, необходимые для запуска приложения, упаковываются в один образ, который может запускаться многократно;
- быстрота развертывания – на создание и запуск контейнера требуется гораздо меньше времени, чем на экземпляр виртуальной машины или настройку полноценного рабочего окружения;
- повышение производительности труда – если каждый микросервис сложной системы упаковать в отдельный контейнер, за который отвечает один разработчик, то можно распараллелить рабочие задачи без взаимных зависимостей и конфликтов;
- упрощение мониторинга — управление версиями контейнерных образов позволяет отслеживать обновления, избегая проблем с синхронизацией.
Тем не менее, при всех вышеотмеченных достоинствах, контейнерной виртуализации свойственны следующие недостатки:
- «упаковка» в контейнер гораздо большего количества ресурсов, чем требуется приложению, что приводит к разрастанию образа и большому размеру контейнера [5];
- проблема с обеспечением информационной безопасности – несмотря на то, что многие системы работы с контейнерами (Kubenetes, Docker и пр.) включают средства защиты от взлома и потери данных, например, изоляция пространства имен, гибкие механизмы сетевых политик и ролевой авторизации пользователей по ключу, а также прочие инструменты, о которых мы подробнее рассказываем в следующей статье, использование контейнеров не всегда безопасно. Например, некоторые важные подсистемы ядра операционной системы Linux функционируют вне контейнера (переферийные устройства, SELinux, Cgroups и вся файловая система внутри системного раздела /sys). Благодаря этому можно взломать операционную систему, если клиент (пользователь или приложение) контейнера имеет root-права [5]. Подробнее об этом читайте в нашей следующей статье.
- проблема обеспечения качества при увеличении числа контейнеров, включая распределение рабочей нагрузки – для решения этой задачи используются системы оркестрации контейнеров, о которых мы поговорим далее.

Зачем нужна оркестрация: как работать со множество контейнеров в Big Data системах
Оркестрация контейнеров в Big Data системах нужна для следующих действий [2]:
- развертывание нескольких контейнеров одновременно в различных средах окружения (на компьютере разработчика, на тестовом и рабочем серверах, в среде аварийного восстановления, в облачном кластере и пр.), что соответствует DevOps-концепции непрерывной разработки, тестирования и поставки программного обеспечения;
- динамическое распределение контейнеров по узлам кластера (балансировка нагрузки);
- постоянный мониторинг состояния контейнеризованных приложений и автоматическая отработка их отказов (перезапуск).
Современный рынок свободного и проприетарного ПО предлагает множество систем оркестрации контейнеров. Наиболее популярными и подходящими для надежных и высоконагруженных Big Data систем считаются Kubernetes, Apache Mesos и Red Hat OpenShift. Для не слишком больших проектов подойдут Docker Swarm, Nomad, Fleet, Aurora. Также заслуживают внимания облачные решения Amazon EC2 Container Service и Microsoft Azure Container Service [6].

Источники
- https://ru.wikipedia.org/wiki/Контейнерная_виртуализация
- https://habr.com/ru/company/redhatrussia/blog/416169/
- https://habr.com/ru/company/it-grad/blog/279229/
- https://www.cloud4y.ru/about/news/obzor-tekhnologii-konteynerizatsii/
- https://habr.com/ru/company/it-grad/blog/279229/
- https://www.xelent.ru/blog/chto-takoe-orkestratsiya-konteynerov/

