 524
524 
Как с Apache Flink настроить локальную службу OLAP, а также развернуть ее в рабочей среде производственного кластера: архитектура, принципы работы и параметры конфигурации для сложных аналитических сценариев.
Служба Flink OLAP: архитектура и принципы работы
Идея выделить в Apache Flink механизм OLAP для анализа данных в потоковом хранилище появилась еще год назад в дорожной карте развития фреймворка. Хотя Flink и до этого позволял решать аналитические задачи как частный случай пакетной обработки, в будущем релизе 2.0, о котором мы писали здесь, планируется новый API потоковой и пакетной обработки аналитической обработки данных. Для этого будет внедрена поддержка API-интерфейсов хранилища для управления данными и метаданными, таких как: CTAS/RTAS, CALL, TRUNCATE и т.д., оптимизация на основе затрат со статистикой и индексация полей в потоковых хранилищах LakeHouse. Ожидается, что все это позволит улучшить выполнение краткосрочных OLAP-заданий с низкой задержкой и параллельным выполнением.
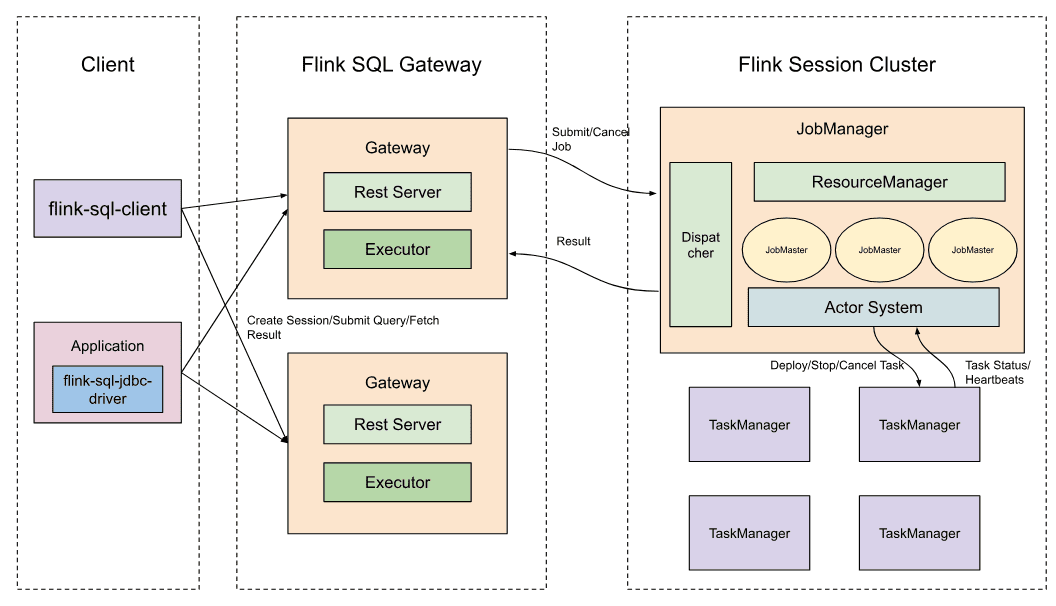
Уже в выпуске 1.19 и ранее Flink позволяет настроить локальную службу OLAP, а также развернуть ее в рабочей среде. Служба Flink OLAP состоит из трех частей: клиента, шлюза Flink SQL и кластера сеансов Flink. Клиентом может быть любой клиент, который взаимодействует с Flink SQL Gateway, например SQL Client, JDBC-драйвер Flink и т. д. Шлюз SQL обеспечивает простой способ анализа SQL-запроса, поиска метаданных, анализа статистики таблиц, оптимизации плана и отправки JobGraph в кластер. Этот сервис позволяет нескольким удаленным клиентам одновременно выполнять SQL-запросы, обеспечивая простой способ отправить задание Flink в кластер, найти метаданные и проанализировать данные во внешней сети. SQL-шлюз состоит из подключаемых конечных точек и процессора SqlGatewayService, который многократно используется конечными точками для обработки запросов. JDBC-драйвером Flink является Java-библиотека для подключения и отправки SQL-операторов на SQL Gateway в качестве JDBC-сервера. Перед использованием JDBC-драйвера необходимо запустить шлюз SQL в качестве JDBC-сервера и связать его с кластером Flink. Все OLAP-запросы выполняются в кластере сеансов Flink, позволяя сократить накладные расходы на запуск вычислительной среды.
Развертывание Flink как OLAP-сервиса дает следующие преимущества:
- массивная параллельная обработка больших объемов данных с возможностью гибко настроить параметры планировщика, чтобы установить параллелизм заданий для удовлетворения требований к задержке запросов при различных размерах состояния stateful-операторов;
- эластичное управление ресурсами, включая динамическое масштабирование, когда кластер сеансов может распределять ресурсы в соответствии с рабочей нагрузкой.
- повторное использование коннекторов для подключения к внешним системами как источникам или приемникам данных;
- унифицированный вычислительный механизм для потоковой и пакетной обработки данных, а также OLAP-вычислений.
Развертывание OLAP-сервиса Flink
Запустить Flink OLAP можно локально и в производственном развертывании. Для локальной установки необходима Java 11 и бинарная версия фреймворка, скачиваемая с официального сайта. Распаковав архив с командой
tar -xzf flink-*.tgz
далее следует запустить локальный кластер с помощью скрипта bash, поставляемого с Flink:
./bin/start-cluster.sh
Затем можно перейти к веб-интерфейсу по адресу http://localhost:8081, чтобы просмотреть панель мониторинга фреймворка и убедиться, что кластер запущен и работает. Чтобы запустить CLI со встроенным шлюзом, надо вызвать команду
./bin/sql-client.sh
Далее можно просто выполнять запросы в CLI и получать результаты.
Для производственного развертывания сервиса Flink OLAP нужно настроить все компоненты этой службы, т.е. кластер сеансов и шлюз SQL. Как уже было отмечено ранее, для отправки запросов в SQL Gateway надо использовать JDBC-драйвер Flink, который обеспечивает низкоуровневое управление соединениями. Чтобы ускорить передачу данных, рекомендуется повторно использовать JDBC-соединения. Это поможет избежать частого создания и закрытия сеансов на шлюзе, также снизит задержку выполнения запросов.
Кластер сеансов Flink можно развернуть в Native Kubernetes – системе оркестрации контейнеров для автоматизации развертывания, масштабирования и управления приложениями, используя режим сеанса. Развертывая в Native Kubernetes, кластер сеансов может динамически выделять и освобождать диспетчеры задач. Настройка параметра slotmanager.number-of-slots.min в кластере сеансов поможет значительно сократить время холодного запуска запроса.
Flink SQL Gateway надо развернуть как stateless-микросервис и зарегистрировать его экземпляр в компоненте обнаружения служб, чтобы клиент мог балансировать запросы между экземплярами.
Также необходимо настроить каталоги состояний, чтобы снизить затраты на холодный запуск, поскольку служба Flink OLAP работает долго, и информация каталога кластера Flink OLAP меняется не часто.
Далее следует настроить коннекторы к источникам данных, т.к. кластер сеансов и шлюз SQL используют их для анализа статистики таблицы и чтения данных из настроенного источника. Использование JDK17 в ZGC может значительно оптимизировать проблему сборки мусора в метапространстве, поскольку ZGC (Z Garbage Collector) является масштабируемым сборщиком мусора с малой задержкой. ZGC выполняет всю дорогостоящую работу одновременно, не останавливая выполнение потоков приложения более чем на 10 мс, что делает его подходящим для приложений, требующих малой задержки и/или использующих очень большую кучу памяти порядка нескольких терабайт. Это характерно для stateful-приложений, включая OLAP сервисы. Сборщик мусора ZGC может обеспечить время паузы приложения, близкое к нулю, очищая память от неиспользуемых объектов.
OLAP-запросы необходимо выполнять в пакетном режиме, используя пакетный планировщик позволяет, чтобы планировать их поэтапно и избежать взаимоблокировок. Также рекомендуется настроить конфигурацию slotmanager.number-of-slots.min в качестве зарезервированного пула ресурсов, обслуживающего OLAP-запросы. Менеджер задач TaskManager следует настроить с большей спецификацией ресурсов, чтобы увеличить объем локальных вычислений и снизить накладные расходы на сеть, сериализацию и десериализацию данных. Аналогичное справедливо и для диспетчера заданий JobManager, который является единой точкой вычислений в OLAP-сценариях и может требовать больше ресурсов.
Освойте применение Apache Flink для потоковой обработки событий в распределенных приложениях аналитики больших данных и машинного обучения на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
[elementor-template id=»13619″]
Источники

