 1023
1023 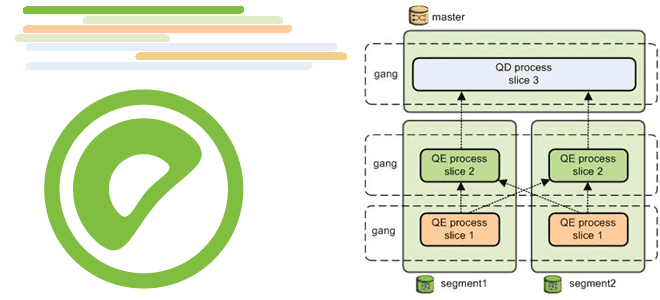
Содержание
Как координатор Greenplum на мастер-хосте рассылает сегментам планы выполнения запросов, что такое курсор параллельного получения результатов оператора SELECT и каким образом его использовать для аналитики больших данных в этой MPP-СУБД.
Особенности рассылки планов SQL-запросов в Greenplum на выполнение
Хотя Greenplum основана на PostgreSQL, некоторые механизмы работы этих СУБД отличаются. Например, поддержка массово-параллельной загрузки данных и централизованная архитектура кластера Greenplum обусловливает некоторые особенности обработки SQL-запросов в этой СУБД. Greenplum представляет собой несколько экземпляров PostgreSQL, работающих как единая СУБД благодаря мастер-хосту, где развёрнут мастер-сегмент – главный экземпляр PostgreSQL. Именно к мастер-сегменту подключаются пользователи и отправляют на него все SQL-запросы. Мастер-сегмент не содержит данных, а только принимает входящие подключения, собирает и систематизирует запросы, чтобы маршрутизировать их по сегментам, которые содержат фактические данные и выполняют запросы.
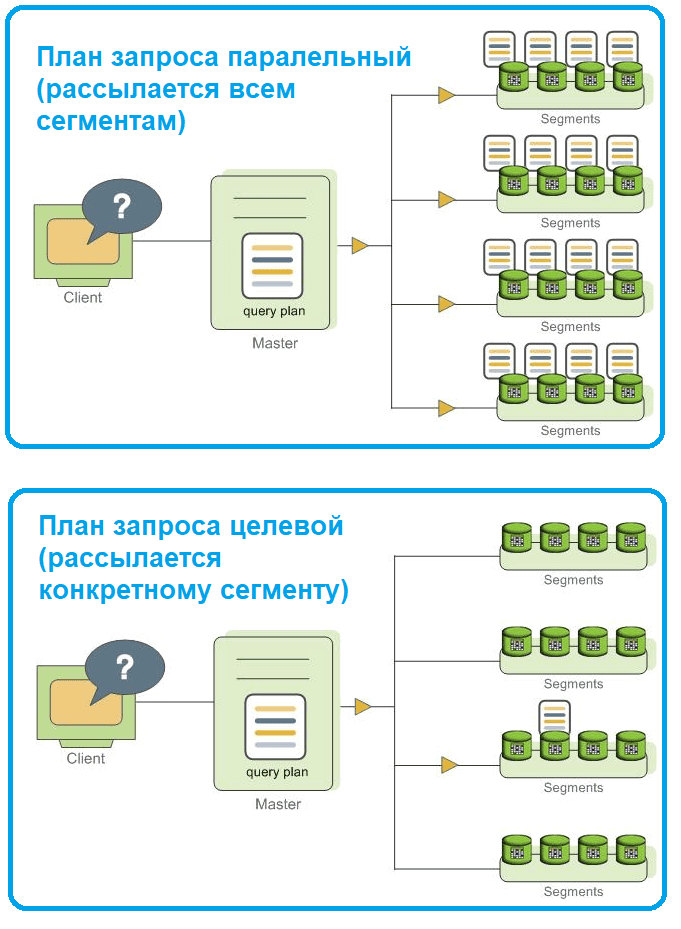
За фактическое получение, анализ и оптимизацию запросов на мастер-сегменте отвечает координатор, которые рассылает сегментам план запросов. Результирующий план запроса является либо параллельным при его отправке всем сегментам Greenplum, либо целевым, если он отправляется только одному сегменту.
Каждый сегмент отвечает за выполнение операций локальной базы данных со своим собственным набором данных. Большинство операций с базой данных, таких как сканирование таблиц, объединение, агрегирование и сортировка, выполняются во всех сегментах параллельно. Каждая операция выполняется в базе данных сегментов независимо от данных, хранящихся в других базах данных сегментов.
Определенные запросы могут получать доступ только к данным в одном сегменте, например однострочные операции INSERT, UPDATE, DELETE, SELECT или запросы, которые фильтруют столбцы ключа распределения таблицы. В таких запросах план запроса не рассылается по всем сегментам, а нацелен на сегмент, который содержит затронутые или релевантные строки.
Исходный SQL-запрос Greenplum переводит в план выполнения — набор операций, которые база данных выполнит для получения ответа на запрос. Каждый шаг этого плана, называемый узел, представляет собой операцию с базой данных, такую как сканирование таблицы, объединение, агрегирование или сортировка. Планы читаются и прогоняются снизу вверх. Поскольку данные, над которыми должен выполниться запрос, могут физически располагаться на разных узлах кластера Greenplum в плане запросов могут появиться операции перемещения кортежей между сегментами во время обработки. Планы целевых запросов, отправляемые координатором к конкретному узлу, обычно не требуют перемещения данных.
Чтобы добиться максимального параллелизма во время выполнения запроса, Greenplum делит работу плана запроса на фрагменты или слайсы (slice) — части, над которой сегменты могут работать независимо. План запроса делится на слайсы везде, где в плане происходит операция перемещения, по одному слайсу на каждой стороне движения. Каждый сегмент получает копию плана запроса и работает над ним параллельно.
Greenplum создает ряд процессов базы данных для обработки запроса. В координаторе рабочий процесс запросов называется диспетчером запросов (QD, Query Dispatcher). QD отвечает за создание и отправку плана запроса. Он также накапливает и представляет окончательные результаты. В сегментах рабочий процесс запроса называется исполнителем запроса (QE, Query Executor). QE отвечает за выполнение своей части работы и передачу ее промежуточных результатов другим рабочим процессам. Каждому слайсу плана запроса назначен как минимум один рабочий процесс, который работает над назначенной ему частью плана запроса независимо. Во время выполнения запроса в каждом сегменте будет несколько процессов, работающих над запросом параллельно. Связанные процессы, которые работают над одним и тем же фрагментом плана запроса, но в разных сегментах, называются группами (gangs). По мере завершения части работы кортежи передаются по плану запроса от одной группы процессов к другой в рамках межпроцессного взаимодействия Greenplum.

Получение результатов запроса с помощью курсора параллельного получения
Механизм обработки результирующего набора SELECT-запроса в базе данных называется курсор. По сути, это поименованная область памяти, содержащая результаты запроса на выборку данных. Параллельная архитектура Greenplum влияет и на реализацию этого механизма. В частности, в Greenplum есть расширенная реализация курсора, которая позволяет получать результаты запроса по требованию параллельно из нескольких сегментов. Это курсор параллельного получения, который создает особый механизм обработки результирующего набора SELECT-запроса в узле координатора Greenplum, позволяя одновременно извлекать меньшее количество строк из более крупного запроса. После объявления курсора параллельного получения, диспетчер запросов к Greenplum (QD) отправляет план запроса каждому исполнителю запросов (QE) и создает для него конечную точку перед выполнением запроса. Конечная точка — это источник результатов запроса для курсора параллельного получения на конкретном QE. Вместо возврата результата запроса непосредственно в QD конечная точка сохраняет результат запроса для получения с помощью процесса прямого соединения. Для этого надо открыть сеанс получения – специальное соединение в режиме получения, и использовать SQL-команду с ключевым словом RETRIEVE для получения результатов запроса из каждой конечной точки курсора параллельного получения. После объявления курсора параллельного получения можно открыть сеанс получения для каждой конечной точки. В любой момент времени для конечной точки может быть открыт только один сеанс получения.
Используя курсор параллельного извлечения для одновременного чтения результатов запроса из нескольких сегментов Greenplum, разработчик выполняет ряд действий:
- объявить курсор параллельного получения для SQL-запроса с помощью команды
DECLARE par_cursor PARALLEL RETRIEVE CURSOR FOR SELECT * FROM table_name;
- получить список созданных конечных точек параллельного получения данных, вызвав функцию gp_get_endpoints() или проверив представление gp_endpoints в сеансе на хосте координатора Greenplum с помощью команд, которые вернут список конечных точек созданных для курсоров параллельного получения, объявленных в текущем сеансе текущим пользователем:
SELECT * FROM gp_get_endpoints(); SELECT * FROM gp_endpoints;
Также в представлении pg_cursors перечислены все объявленные курсоры, доступные в данный момент в системе. Из этого представления тоже можно получить информацию обо всех курсорах параллельного извлечения, выполнив команду
SELECT * FROM pg_cursors WHERE is_parallel = true;
- открыть соединение для получения данных с каждой конечной точкой с помощью параметра конфигурации сервера gp_retrieve_conn в запросе на соединение, установив ему значение true;
- получить конкретное число строк или все данные из каждой конечной точки с помощь команды
RETRIEVE ALL FROM ENDPOINT par_cursor_endpoint_name;
- дождаться завершения получения данных поможет функция gp_wait_parallel_retrieve_cursor(), которая отображает состояние получения данных из курсора параллельного получения или ожидает, пока все конечные точки завершат получение данных. Эта функция вызывается в блоке транзакции, где объявлен курсор параллельного получения. Функция gp_wait_parallel_retrieve_cursor() возвращает значение true, когда все кортежи полностью получены со всех конечных точек. Иначе функция возвращает значение false и ошибку.
- обработать ошибки получения данных, которые могут возникнуть в сеансе получения, если операция извлечения отменена или прервана. Конечная точка частично извлекается только после завершения сеанса получения. Когда в каком-то сеансе получения возникает ошибка, Greenplum удаляет его конечную точку из QE, а другие сеансы извлечения продолжают работать в обычном режиме. При ручном закрытии транзакции до полного получения данных со всех конечных точек или если функция gp_wait_parallel_retrieve_cursor() вернула ошибку, Greenplum завершает все оставшиеся открытые сеансы получения данных.
- закрыть курсор параллельного получения с помощью команды CLOSE.
Максимально возможное значение по умолчанию количества курсоров параллельного получения, активных в кластере Greenplum, равно 1024. Суперпользователь Greenplum может ограничить количество открытых курсоров, установив параметр конфигурации сервера gp_max_parallel_cursors.
В заключение отметим, что текущая реализация параллельного курсора получения в Greenplum имеет следующие ограничения:
- оптимизатор запросов GPORCA не поддерживает запросы к курсору параллельного получения;
- при объявлении курсора параллельного получения Greenplum игнорирует предложение BINARY, которое позволяет объявить двоичный курсор, возвращающий данные в двоичном представлении;
- курсоры параллельного получения не могут быть объявлены с предложением WITH HOLD, которое указывает, что курсор может продолжать использоваться после успешной фиксации создавшей его транзакции;
- курсоры параллельного извлечения не поддерживают операции с командами получения данных FETCH и перемещения позиции без получения данных MOVE;
- курсоры параллельного получения не поддерживаются в интерфейсе программирования сервера (SPI, Server Programming Interface) и в пользовательских функциях хранимых процедур на языке PL/pgSQL.
Освойте администрирование и эксплуатацию Greenplum и Arenadata DB для эффективного хранения и аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

