В этой статье для дата-аналитиков и разработчиков распределенных приложений рассмотрим несколько распространенных ошибок, которые можно сделать в PySpark-коде. Когда PySpark-код на DataFrame DSL лучше запросов Spark SQL, как изящно решить проблему длинных строк, почему пользоваться функцией cache() надо осторожно, а также откуда появляются NULL-значения при внешних соединениях потоковых таблиц. Spark...
Чтобы сделать наши курсы для дата-инженеров еще более полезными, сегодня рассмотрим, как объединить Apache NiFi и Airflow в рамках одного ETL-конвейера обработки данных. Читайте далее, зачем совмещать эти технологии и как сделать это наиболее эффективно, обращаясь к конечным точкам REST API процессоров NiFi из задач DAG-графа AirFlow. Apache Airflow +...

В рамках продвижения нашего нового курса по графовой аналитике больших данных в бизнес-приложениях, сегодня рассмотрим пример анализа данных о путешествиях средствами графовой СУБД Neo4j и ее языка запросов Cypher. Читайте далее, где взять данные о путешествиях цифровых кочевников и как определить самое популярное направление. Цифровые кочевники и графы их путешествий Хотя...

В октябре 2021 года российская компания «Аренадата Софтвер» выпустила новый продукт для аналитики больших данных под брендом Arenadata. Что такое Arenadata LogSearch (ADLS), при чем здесь Elasticsearch и какие потребности закрывает эта корпоративная адаптация open-source технологии полнотекстового поиска от отечественных разработчиков. Elasticsearch, OpenSearch и Arenadata LogSearch: близнецы или тройняшки? Среди...

Сегодня разберем кейс платформы онлайн-обучения Udemy по разработке собственной системы потоковой аналитики больших данных о событиях пользовательского поведения на Apache Kafka, Hive и сервисах Amazon. Про требования к инфраструктуре отслеживания событий и их реализацию с помощью Apache Kafka, Hive, Kubernetes, AWS S3 и EMR, а также чем AVRO лучше Protobuf....
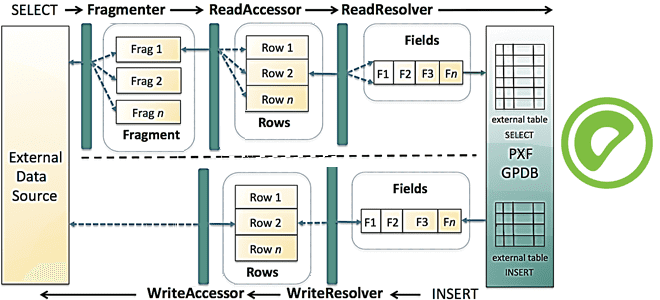
Специально для дата-инженеров, разработчиков OLAP-конвейеров и архитекторов DWH на MPP-СУБД Greenplum и Arenadata DB сегодня рассмотрим, что представляет собой PXF, из каких компонентов он состоит и как они взаимодействуют друг с другом, чтобы обеспечить параллельный высокопроизводительный доступ к данным и объединенную обработку запросов к разнородным источникам. Что PXF и зачем...

В начале сентября 2021 года вышел 3-й релиз языка программирования Scala, который разработчики называют полностью переработанным из-за модернизации системы типов и добавления новых функций. Текущая версия Apache Spark 3.2.0, выпущенная месяцем позже, поддерживает Scala 2.13 и 3.0 с ограничением некоторых возможностей. Читайте далее, как разработчикам распределенных Spark-приложений писать задания на...
Добавляя в наши курсы по Apache Kafka еще больше полезных кейсов, сегодня рассмотрим пример интеграции этой распределенной платформы потоковой передачи событий с масштабируемой key-value СУБД GridDB через JDBC-коннекторы Kafka Connect. Apache Kafka как источник данных: source-коннектор JDBC Apache Kafka часто используется в качестве источника или приемника данных для аналитической обработки...

29 сентября 2021 года вышла новая версия популярного Big Data фреймворка Apache Flink. Мы сделали краткий обзор главных улучшений свежего релиза 1.14 общедоступного дистрибутива, а также его коммерциализации в Ververica Platform 2.6. Узнайте, как потоковая обработка и аналитики больших данных с Apache Flink станет еще проще и эффективнее. Исправление ошибок...

Сегодня рассмотрим, как Uber эффективно обрабатывает миллионы запросов на поездки c помощью технологий надежного хранения и быстрой аналитики больших данных. Вас ждет краткий ликбез по системе геопространственной индексации H3 и рассказ о том, почему компания заменила NoSQL-Cassandra c компонентом Saga интеграционного фреймворка Camel на геораспределенную облачную NewSQL-СУБД Spanner от Google....