 680
680 
Содержание
Добавляя в наши курсы по Apache Kafka еще больше полезных кейсов, сегодня рассмотрим пример интеграции этой распределенной платформы потоковой передачи событий с масштабируемой key-value СУБД GridDB через JDBC-коннекторы Kafka Connect.
Apache Kafka как источник данных: source-коннектор JDBC
Apache Kafka часто используется в качестве источника или приемника данных для аналитической обработки практически в реальном времени. Благодаря множеству готовых коннекторов и платформе Kafka Connect подключение к внешним системам становится достаточно простой задачей. Предположим, необходим анализ данных временных рядов от устройств интернета вещей, которые изначально хранятся в GridDB – высокопроизводительной масштабируемой key-value СУБД от компании Toshiba, которая оптимизирована для огромных объемов информации. Примечательно, что GridDB по умолчанию поддерживает ACID-транзакции и согласованность данных на уровне контейнеров, суть которых аналогична таблицам реляционных баз данных [1].
Подключение распределенной платформы потоковой передачи событий к большинству СУБД реализуется через JDBC-коннектор в составе Kafka Connect от Confluent, интегрированного с реестром схем (Schema Registry) для эволюции схемы данных. В частности, source-коннектор JDBC Kafka Connect позволяет импортировать данные из любой реляционной СУБД с драйвером JDBC в топик через периодическое выполнение SQL-запроса и создания выходной записи для каждой строки в наборе результатов. По умолчанию каждая таблица из базы-источника копируется в отдельный выходной топик Kafka, а исходная СУБД непрерывно отслеживается на наличие новых или удаленных таблиц. Коннектор гибко настраивается, позволяя задавать множество параметров: типы JDBC-данных, динамическое добавление и удаление таблиц из базы-источника, белые и черные списки, интервалы опроса и пр. Благодаря автоматическому отслеживанию последней записи из каждой таблицы, source-коннектор JDBC Kafka Connect сможет снова запуститься в нужном месте в случае сбоя [2]. Подробнее о том, как работает этот коннектор, мы писали здесь.
В нашем примере интеграция Apache Kafka с GridDB будет реализована с помощью скрипта на языке Go, который отвечает за запись данных в GridDB их считывание коннектором-источником и передачу в Кафка и вывод на консоль [3].
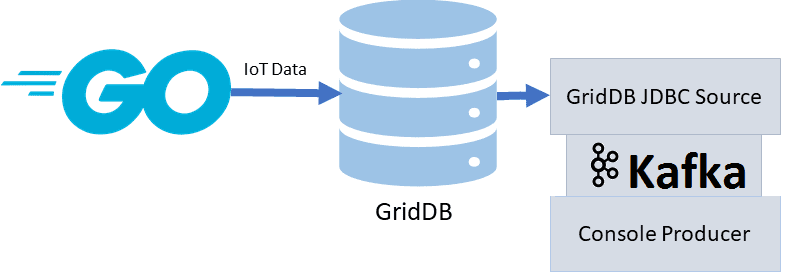
Sink-коннектор JDBC Kafka Connect для GridDB
Если Apache Kafka выступает в качестве приемника данных из СУБД, используется sink-коннектор JDBC Kafka Connect. Коннектор опрашивает данные из СУБД для записи в Кафка на основе подписки на топики, поддерживая идемпотентную записи с upserts, автоматическое создание таблиц и ограниченную эволюцию схемы данных. Коннектор поддерживает функцию очереди недоставленных сообщений, а также выполнение нескольких задач (одновременно, количество которых задается в параметре конфигурации tasks.max. Увеличение этого числа может повысить производительность, когда необходимо проанализировать несколько файлов.
Sink-коннектор требует знания схемы данных, поэтому следует использовать подходящий конвертер схем. Ключи записи Кафка могут быть примитивными типами или структурой Connect, а значение записи должно быть структурой Connect с примитивными типами данных. По умолчанию первичные ключи не извлекаются, если для параметра pk.mode установлено значение none. Это не подходит для расширенного использования, такого как семантика upsert, и когда коннектор отвечает за автоматическое создание целевой таблицы. Существуют различные режимы, которые позволяют использовать поля из ключа или записи, а также позиции смещения.
Если указанная таблица базы данных не существует или в ней отсутствуют столбцы, коннектор может самостоятельно выполнить инструкцию CREATE TABLE или ALTER TABLE для создания таблицы или добавления столбцов, если свойства auto.create и auto.evolve установлены в значение true [4].
Практический пример
Возвращаясь к рассматриваемому примеру, отметим, что перед использованием принимающего коннектора следует настроить его файл конфигурации. В частности, определить параметры и информацию о подключении, чтобы учетные данные Кафка-сервера могли взаимодействовать с сервером GridDB. В частности, в файле config/connect-jdbc.properties задаются следующие параметры [3]:
bootstrap.servers=localhost:9092
name=griddb-sources
connector.class=io.confluent.connect.jdbc.JdbcSourceConnector
tasks.max=1
key.converter.schemas.enable=true
value.converter.schemas.enable=true
batch.size=1
mode=bulk
topic.prefix=gridstore-02-
table.whitelist=»kafkaTop»
connection.url=jdbc:gs://239.0.0.1:41999/defaultCluster/public
connection.user=admin
connection.password=admin
auto.create=true
transforms=TimestampConverter
transforms.TimestampConverter.type=org.apache.kafka.connect.transforms.TimestampConverter$Value
transforms.TimestampConverter.format=yyyy-MM-dd hh:mm:ss
transforms.TimestampConverter.field=datetime
transforms.TimestampConverter.target.type=Timestamp
JDBC-драйвер GridDB предоставляет интерфейс SQL для этой NoSQL-СУБД. При интеграции с Kafka с использованием sink-коннектора следует убедиться, что имя контейнера GridDB соответствует таблице из белого списка в файле jdbc.properties. В нашем примере это kafkaTop.
Таким образом, Go-скрипт будет выглядеть следующим образом [1]:
containerName := «kafkTop»
conInfo, err := griddb_go.CreateContainerInfo(map[string]interface{} {
«name»: containerName,
«column_info_list»:[][]interface{}{
{«timestamp», griddb_go.TYPE_TIMESTAMP},
{«id», griddb_go.TYPE_SHORT},
{«data», griddb_go.TYPE_FLOAT},
{«temperature», griddb_go.TYPE_FLOAT}},
«type»: griddb_go.CONTAINER_TIME_SERIES,
«row_key»: true})
if (err != nil) {
fmt.Println(«Create containerInfo failed, err:», err)
panic(«err CreateContainerInfo»)
}
defer griddb_go.DeleteContainerInfo(conInfo)
После выполнения этого скрипта можно использовать Source-коннектор JDBC, чтобы прочитать таблицу и передать данные в Apache Kafka, запустив в консоли следующую инструкцию:
$ ./bin/connect-standalone.sh config/connect-standalone.properties config/connect-jdbc.properties
Эта команда запустит коннектор, и он начнет поиск таблицы, которая находится в белом списке. При ее отсутствии, если поиск не дал результатов, об этом выдастся соответствующее сообщение. Для чтения сообщения в топике Kafka и вывод их в консоль, следует запустить shell-скрипт предварительно написанного потребителя:
$ bin/kafka-console-consumer.sh —topic gridstore-03-kafkaTop —from-beginning —bootstrap-server localhost:9092
Эта команда будет выводить содержимое контейнера GridDB в виде сообщения Kafka на консоль.
Курс Apache Kafka: администрирование кластера
Код курса
KAFKA
Ближайшая дата курса
26 января, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Узнайте больше про администрирование и эксплуатацию Apache Kafka для разработки распределенных приложений потоковой аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

